Remember when you were in school – your teacher assigned you a report on Monday that was due on Friday. You went to the library, searched for the book you needed, got it stamped by the librarian at the front desk to log that you had it, and received a date by which to return the book. It was a very simple and quick process that left you with enough time to use the book to complete your report.
Why can’t getting access to data be this simple? If you’ve ever requested access, chances are you first had to search for and confirm the data you wanted, then raise a support ticket or send an email to your boss, and then wait and hope you get access some time later (but not too much later, or else the data would be useless).
If libraries worked like this, none would still be open. After searching for and finding your book, the librarian would direct you to a separate building to fill out a form to request that book (not to mention, the form would be quite confusing; instead of simply listing the book’s title, it would ask for a reference ID that only the librarian understands). The people in that building would take the form back to the library, where the librarian would review it (assuming you did not make any mistakes) and return to the people in the building. Those people would then tell another person in another building to deliver you the book. By this time, you’d have been waiting weeks, and would not have completed your report in time.
This may sound exaggerated, but it’s the model for requesting access to any data in most organizations. In this blog, we’ll look at why this model is no longer practical, and what data teams need to succeed in the future of data provisioning.
Why ticket-based systems no longer work
Ticketing systems weren’t built to manage access at scale
The ticket-based data provisioning model was designed a long time ago to process requests for a handful of applications (e.g. PowerPoint) or hardware access (e.g. the printer on level 3). But it only works with a limited number of applications/hardware and requests per employee. In those cases, the decision to grant access is relatively straightforward and granting the wrong access has only a minor impact (e.g. over-consumption on application licenses).
Consider the library analogy:
- Every table in your database, spreadsheet in the shared drive, dashboard or report in your BI tool, and file in your S3/ADLS storage is a book in your library.
- Traditionally, data in tables or CSV/JSON files could only be processed/transformed by engineers, just as books could only be checked out by librarians.
- AI has removed the technical barriers for non-engineers, so now anyone can use any data. The net result is longer lines in the library….bad time to be a librarian!
Ticketing systems lack the granularity needed for today’s data needs
Of course, you can solve the data request scalability problem using access policies. These policies automatically grant access to data to a user based on their role or another attribute, such as department or location.
Consider our library example. A policy would allow all students in Grade 5 to automatically check out books written for kids age 10 to 11. But what if a student in Grade 4 wanted to check out a book written for ages 10 to 11? Would the librarian now say all students in Grade 4 can also get those books?
Access policies provide a very efficient way to provision access because they’re highly scalable and don’t necessitate new roles for every need. Still, there are always exceptions. For instance:
- A user who does not have the appropriate attribute to satisfy a policy but still needs to access the data for a high-priority project.
- Not just one user, but hundreds asking for data, each with unique circumstances depending on the level of access they need.
This is where exception-based access, also sometimes referred to as self-service access, makes a big difference.
The limitations of self-service data access models
But, as described earlier, the existing self-service model does not work for modern data access needs. It simply relies on too many systems and people for it to be manageable and practical in providing timely access to the end user.
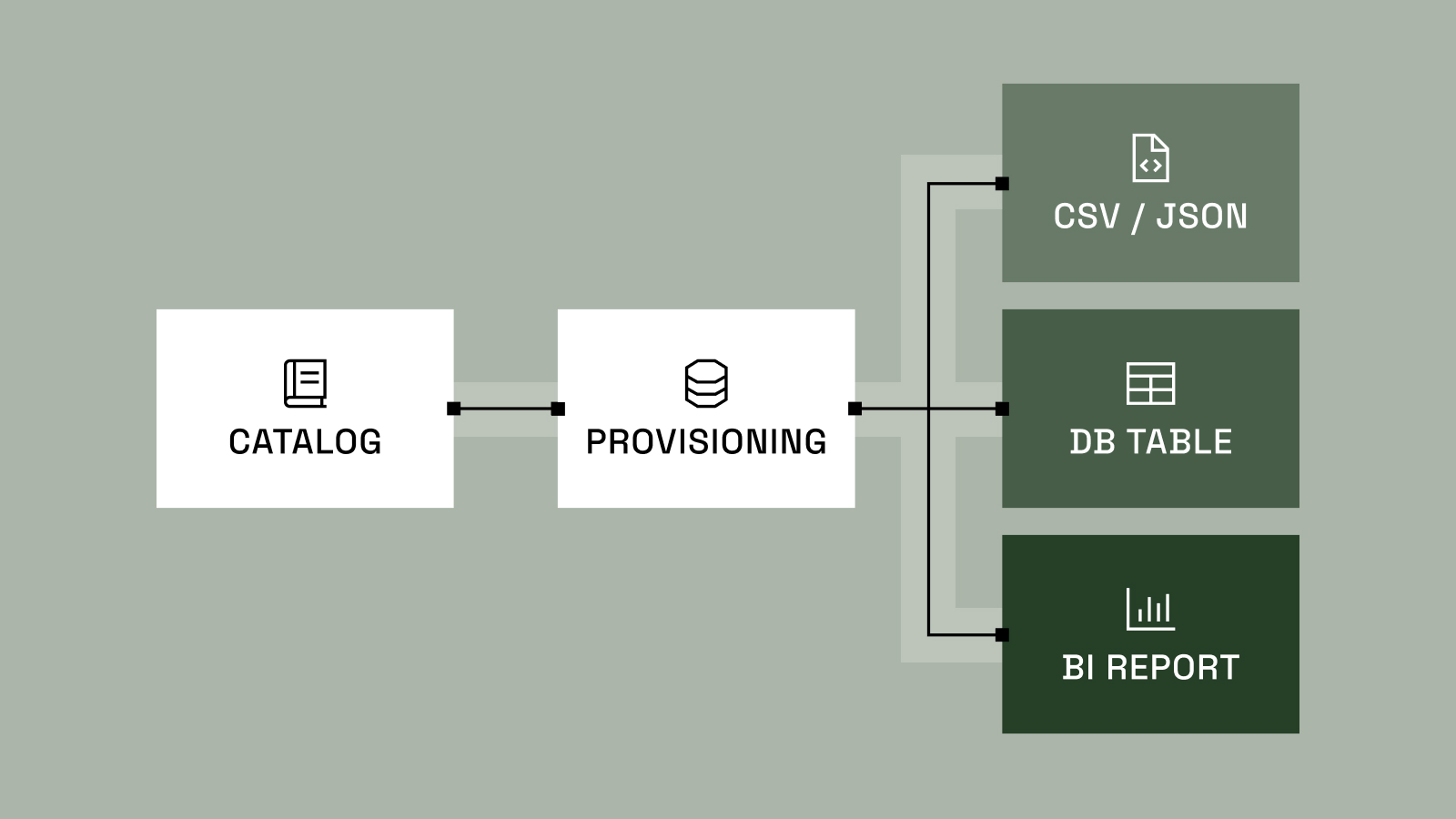
Let’s break down the different parts in the chain of self-service access:
- The data catalog provides a central, searchable hub for all data assets, regardless of where the data resides.
- The ticketing system is where users raise an access request.
- The identity access management (IAM) system contains information about the user/groups/roles.
- The identity governance and administration (IGA) tool can tell different systems which user belongs which role(s).
- The provisioning system natively applies the controls inside the data platforms.
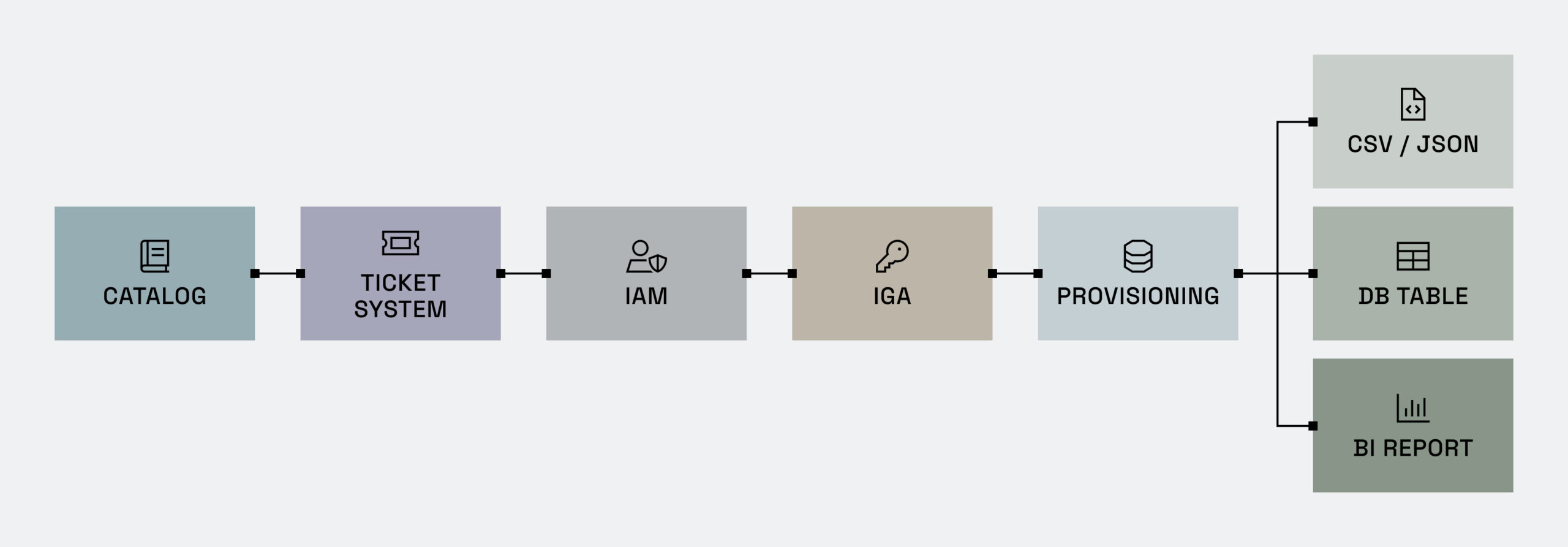
With so many different – and often disparate – elements, this model creates challenges such as:
- The data user needs to go between the catalog and the ticketing system in order to find data and then request access to it. This is both time consuming and error-prone.
- The form in the ticketing system needs to accurately capture the request. However, since the user is going between the catalog and the ticketing system, there is a risk of miscommunication or incompleteness.
- Once the process is completed in the ticketing system, this will kick off another process for a DBA to work in the data system to provision access according to the details in the ticket.
- Access is granted to a role rather than a user, so the role needs to exist first in the IAM. Otherwise, the user will be blocked from accessing the data.
- Access is coarse-grained, which means that any ad hoc or specific requests require further meetings, updates, and approvals. This causes frustration by further delaying speed to access.
- Any changes require updates in multiple systems. This opens the door for inconsistencies and security gaps.
- Access is granted indefinitely; rescinding it requires an additional workflow, which is both time- and labor-intensive. At scale, this quickly becomes complicated and difficult to manage.
The future of data provisioning
While automated data provisioning platforms like Immuta can support the complexity of this process, this disjointed model simply will not scale. This is particularly true as more data users – both human and non-human (i.e. AI agents) – request access by exception.
We are seeing a number of fundamental shifts to support this:
1. Integrating catalogs with provisioning systems.
Consider a use case where you have a table with 10 columns, and you need to grant access to only three columns and rows related to a certain user’s department. Fulfilling this type of request using a standard form in a ticketing system will not work. Users are now using catalogs to find and request access to these complex data use cases.
2. Removing the requirement to map users to roles/groups when granting access in all cases.
By removing the need for a user to be mapped to a specific role/group, you reduce the dependency – and the burden – on your IAM/IGA teams. This also allows data product owners to independently publish data on their schedule, without waiting for roles/groups to be created.
3. Replacing traditional canned reports with data products.
Amid the rapid adoption of AI, data products are replacing traditional reports. AI copilots and vibe coding practices are removing the technical barriers for non-technical users to run advanced programmatic analyses, so access to more raw and unstructured data is needed. We see users requesting access directly to data products rather than individual tables or all data in a schema. The catalogs will contain these data products.
4. Provisioning data access immediately upon approval.
Once a request is approved, immediately provisioning access is paramount to ensuring the data is used efficiently and appropriately. If you have to wait until a DBA performs the last step and provisions access in the data platform, you undo all the benefits of implementing a flexible and agile expectation-based process.
5. Governing data through time-bound access.
Demands for data are becoming more pointed and time sensitive, meaning data teams need to rethink how they manage requests and approvals. Granting access indefinitely introduces security risks and adds additional administrative work by requiring someone to review all existing access permissions and determine whether to revoke a user’s access. However, reviewing the request once and making a determination about how long the user needs access helps reduce those risks and removes the cumbersome tasks of continuously reviewing users’ access.
How Immuta solves the data provisioning challenge in the AI era
Immuta’s provisioning capability allows data users to search for and request access to data in one place. Data owners are able to provision access to that data in a single platform – without the need for a DBA, data team, or another ticket. This reduces the risk of confusion and miscommunication.
This new approach unshackles data owners and data platform teams from generic ticketing, IAM, and IAG services, significantly simplifying the data architecture and reducing the cost of managing data access provisioning. Compared to the figure above – which had three steps between the data catalog and provisioning – this model directly connects the two.
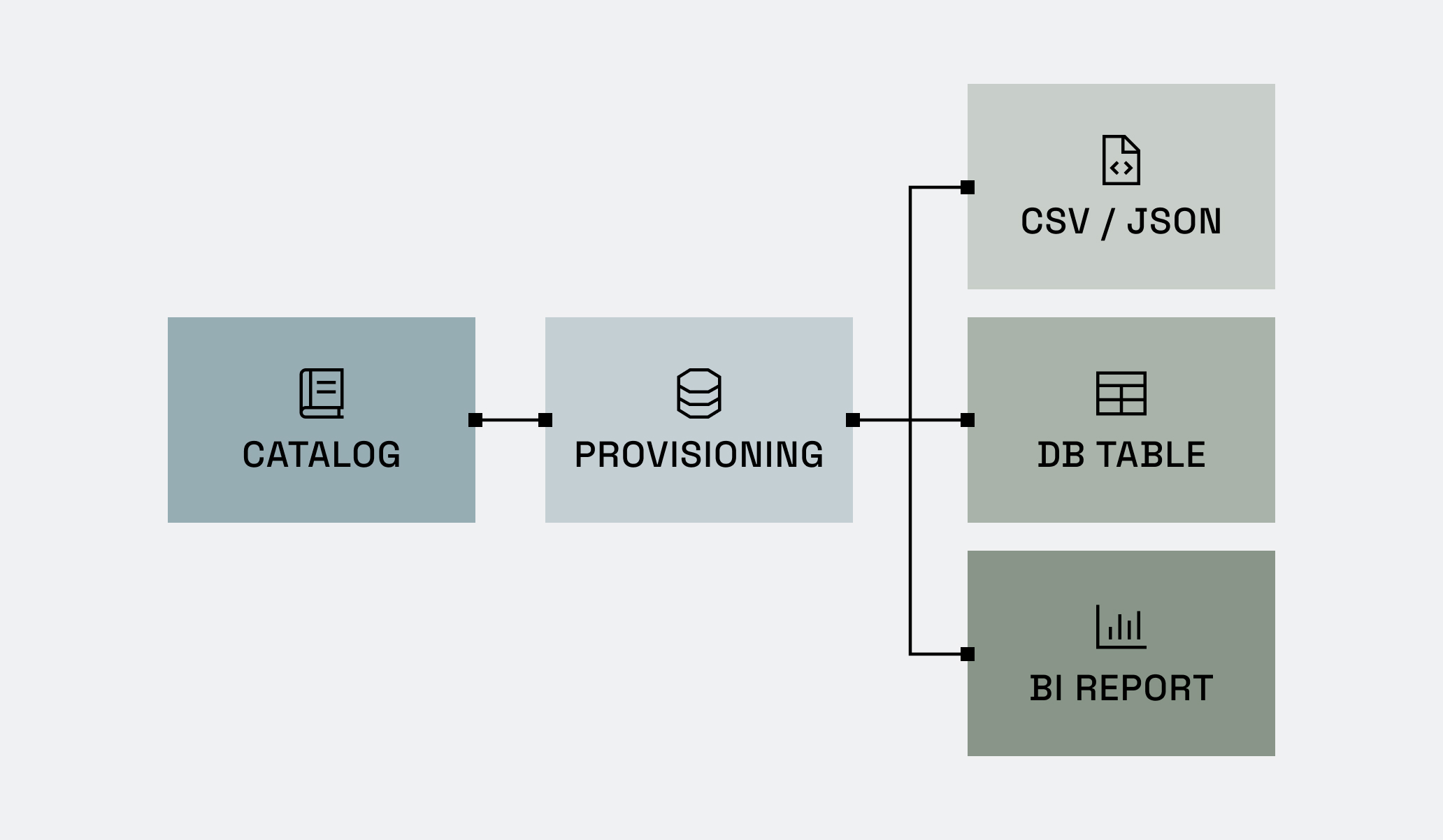
In addition to operational improvements, this approach enables organizations to roll out new data and AI initiatives faster, cheaper, and as safely as possible.
Dive in deeper.
Take a closer look at data provisioning in the AI era.



