We have all seen capabilities for publishing data products, surfacing them for data consumers to discover and request access, and making access decisions. But what about when that data product contains sensitive columns that some users should see but others should not?
The state-of-the-art solution to date for this workflow has been to publish multiple versions of the same data product to accommodate different access levels. For example, you might create a “Public” version versus a “Highly Sensitive” version, with potentially many versions in between where some set of the data’s columns is hidden across them.
This approach can be extremely challenging to manage because:
- Your pipelines need to ensure all versions of the same data product remain consistent.
- You must execute and manage more transform jobs to create the various different versions.
- The fine-grained access control required to mask columns must now span multiple different tables/views.
- Your data product needs to ensure that any relationships between tables/views are not sensitive to the variations in visibility across versions, which could break referential integrity.
- You either need to create many, many different versions of the same data product, or give users access to far more sensitive columns than they actually need.
- You must maintain metadata across these different data products and make it clear to your data consumers that they are related – the only difference being their access level.
- Consumers may need to go through a request/approve flow for many of the versions until they get the version that actually has the data they need.
- The data stewards managing access reviews need to understand what each version contains sensitivity-wise in order to make a meaningful decision on the access request.
How can we make this a better experience for the data product owners, the consumers requesting access, and the stewards reviewing those requests?
Introducing Masking Exception Requests
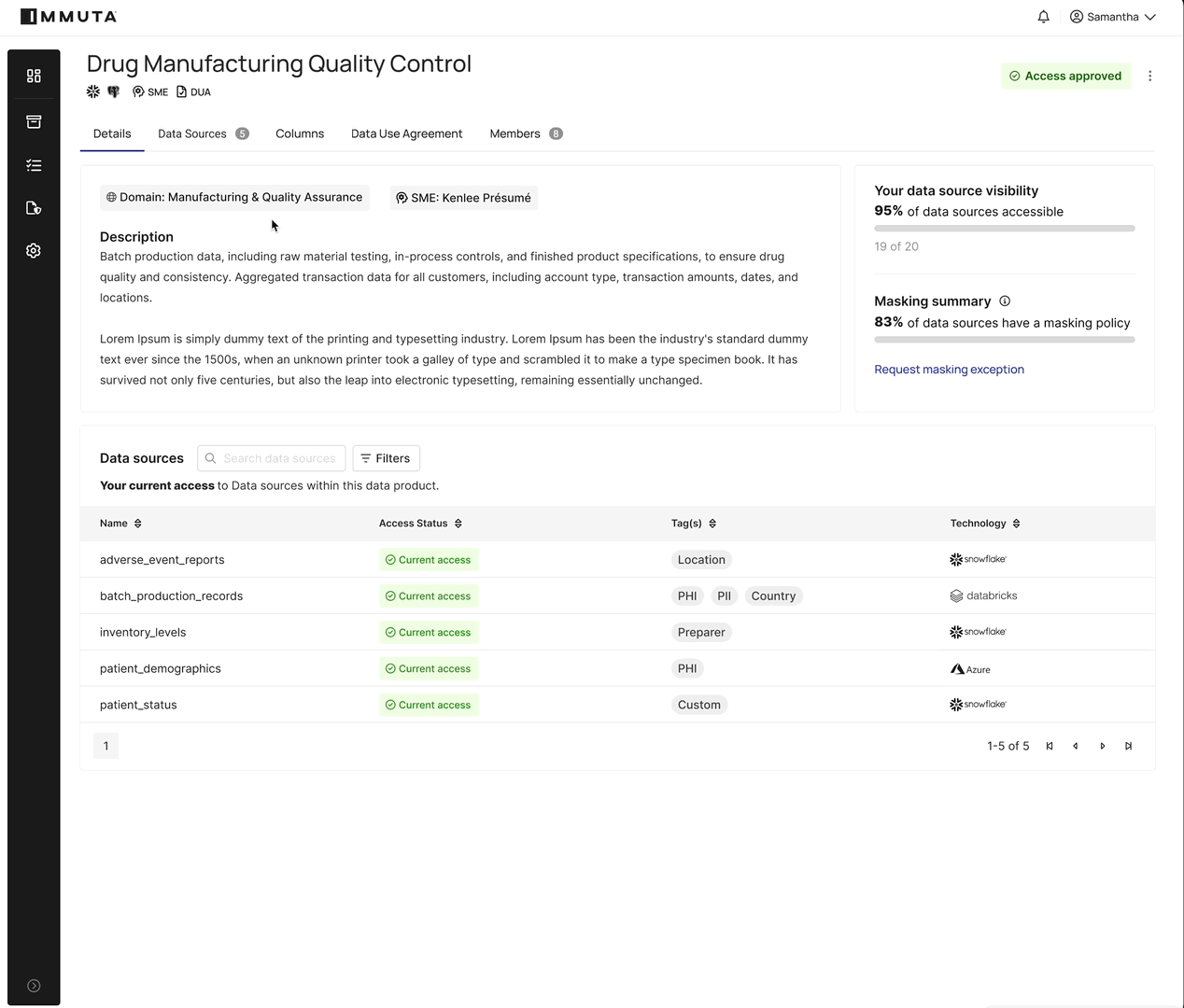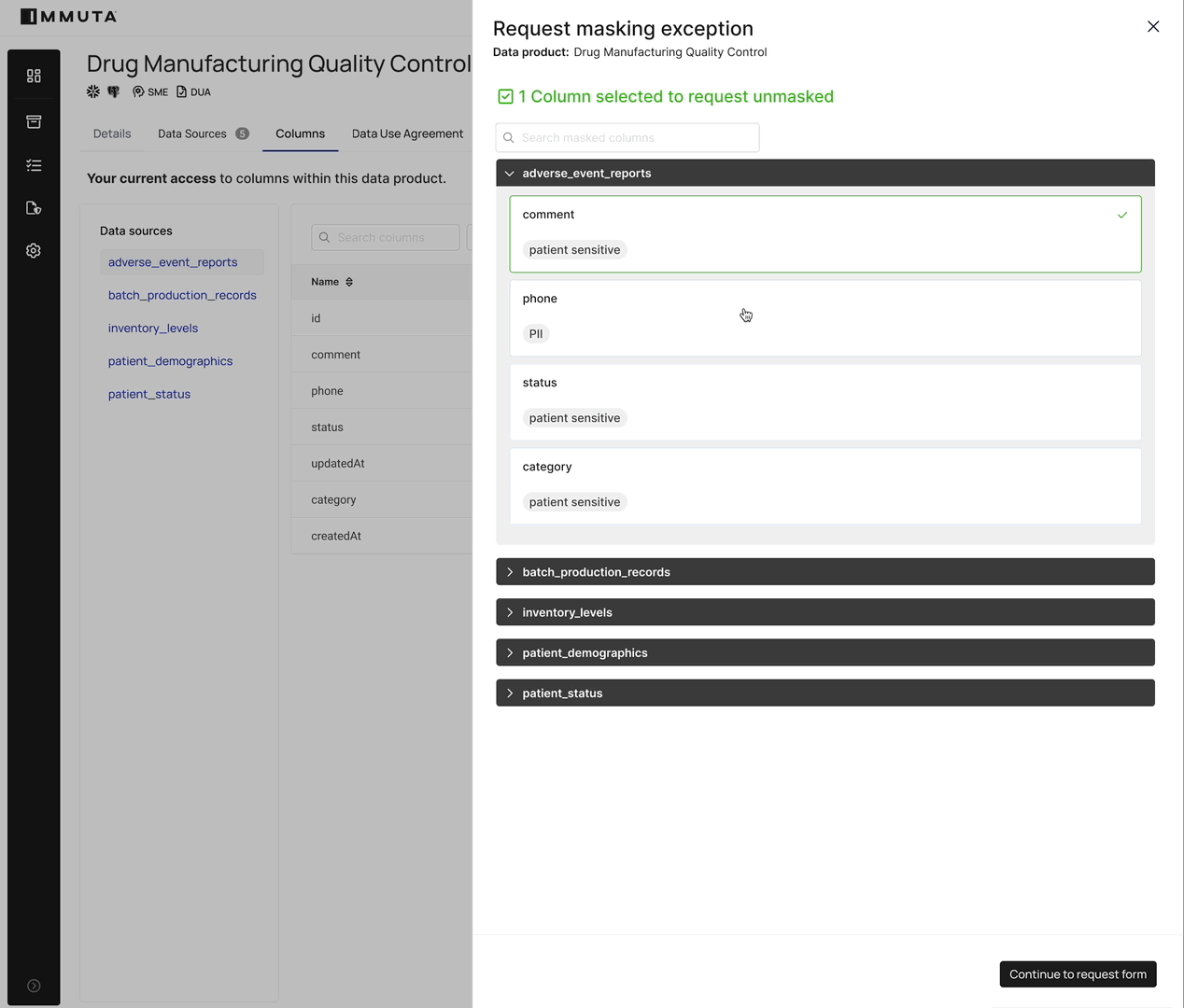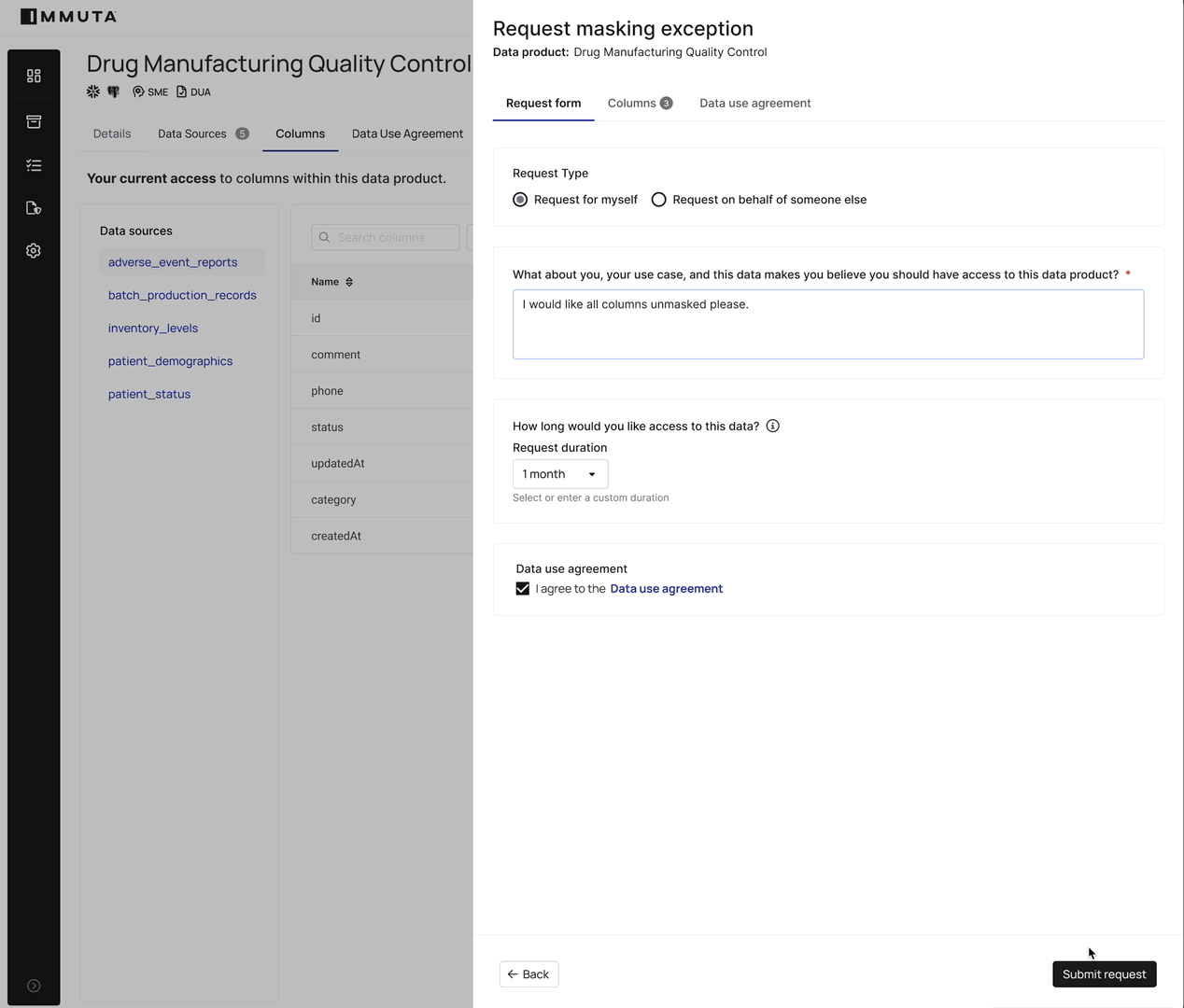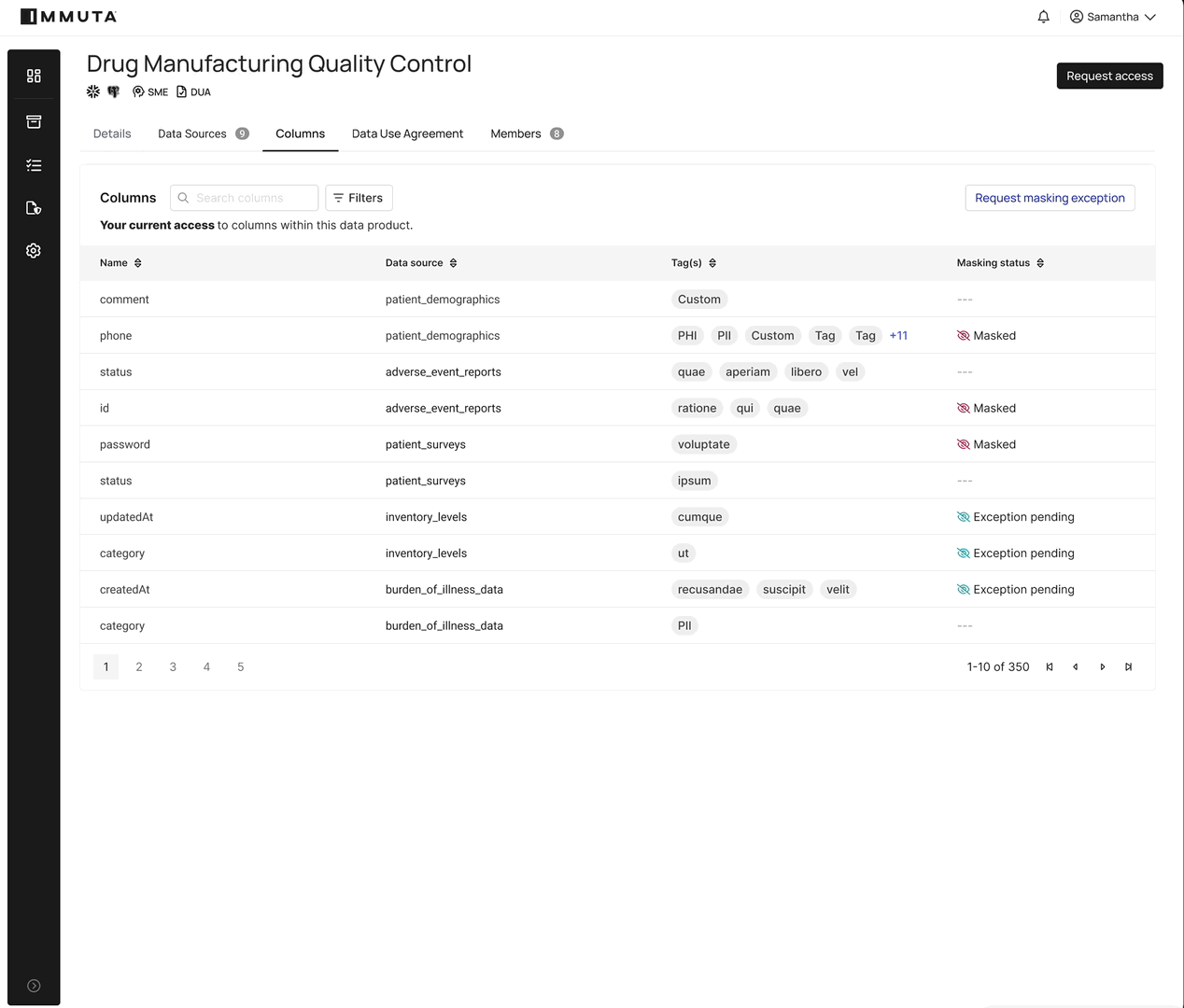
Rather than creating multiple versions to accommodate different access levels, Immuta allows data stewards to approve removal of specific column masks on a per-request basis.
For example, a user can request full access to a set of sensitive columns in a data product. If approved, Immuta modifies the masking policy behind the scenes – without exposing more than what was requested. The data product owner still maintains a single data product, but access becomes personalized.
For the data product owner, this greatly simplifies publishing. Owners can publish a single data product, knowing that masking and exception handling are managed dynamically by policy. Need to give a marketing analyst access to masked email fields but allow an investigator to see full PII? Same data product – different access, granted safely and auditably. The result: less duplication, less overhead, and more confidence that access is aligned with business intent.
For the data consumer, it is also a seamless experience. Once they have access to the data in the data product, it will become clear which columns they need access to in order to accomplish the task at hand. They can simply request access to those very specific columns, and if approved, a dynamic update to the masking policy exceptions in the data platform will provision those columns. No need for an administrator to manually run commands. Data consumers get immediate access to what they need – no more, no less.
For the steward who is responsible for reviewing the access requests, it is clear which columns were requested, how they were tagged to understand their sensitivity level, how they are currently masked, and what utility that masking type provides to aid their decision. They also have the ability to temporarily approve access to the columns in question, reducing risk. And our Review Assist feature will also aid the steward with recommendations based on past approvals to similarly tagged columns.
Requests for masking exceptions in the wild
How does this feature provide value in real customer use cases?
Prior to the availability of this feature, one of our health insurer customers would manage masking exceptions globally. When a user needed access to PII and was approved to do so, they would get access to all PII across all tables(!!). With this feature, their break-glass process is now granular, provisioning only exactly what the user requires.
Another customer, a payroll solution provider, needs to remove masks only for legitimate access purposes. Upon request to have a mask removed, they are now able to require that the requestor provide the purpose via a pre-set list, using our custom request form capability. And if approved, users gain access to only those requested columns.
Finally, internally at Immuta we can use our own software to investigate support tickets in our SaaS environment. All customer-sensitive data is masked from our teams, unless approved for temporary access (a very short period of time). A request can be pushed through our own formal channels and, if approved, access is temporarily provided to diagnose the support case. As with both examples above, access is only given to the precise columns required to do the job.
What's next?
We’ve discussed how this feature supports revealing masked columns, but what about filtered rows? That’s what’s coming next. Similar to requests to have masks removed for a column, users will be able to request that the row filter be altered. If approved, that underlying policy will be dynamically adjusted to reveal the appropriate approved data – no more, no less.
Learn more.
Explore Immuta AI features.



