Data catalogs are foundational in the modern data stack, delivering a single, searchable inventory of every dataset an organization owns. From engineers to business analysts, data catalogs give users a centralized knowledge base in which to explore and understand what’s available.
But what many organizations don’t realize is that a data catalog is only part of the equation. It’s a meticulously organized library where the books are locked behind glass. Even if you find what you’re looking for, you may not be able to actually get it. What use is that?
The real value lies in your ability to put the right data in the right hands, instantly and safely, so it can drive business decisions, unlock new opportunities, and move organizations forward. That’s where data provisioning comes in.
In this blog, we’ll look at why layering data provisioning on top of an existing data catalog allows you to leave less on the table and truly put your data to work.
The pros and cons of data catalogs
Data catalogs are a no-brainer for most data-driven enterprise organizations. After all, they offer everything data teams need to wrangle and organize their datasets:
- A central inventory of all data assets
- Rich metadata for context and classification
- Easy search and discovery for technical and non-technical users
- Data lineage to track data origins and transformations
These capabilities are critical for data governance and self-service data access. But here’s where most organizations get tripped up: While the data catalog can handle discovery, it stops short of delivery.
Data catalogs simply weren’t designed to provision data access. So without that layer, even the most advanced data architectures end up with slow, manual access hurdles. Users find data, request access to it, and wait. And wait. Sometimes for months. Meanwhile, the promise of agile, data-driven decision-making remains largely unfulfilled, and users’ frustrations grow.
The solution isn’t to ditch your data catalog. It’s understanding where the pain points lie, and putting systems in place alongside the catalog so the right people get the right data, right when they need it. Let’s dive in.
Pain point 1: Finding data vs. getting data
Imagine a product manager is performing a market analysis and finds a data product in the catalog that can help accelerate their research. They request access — and then the wait begins. The approval process might involve a chain of emails, a help desk ticket, or even manual policy checks. By the time the product manager gets access, the market window has shifted and the insights are less valuable.
This kind of dilemma is particularly problematic in highly regulated, fast-paced industries like healthcare and life sciences. For instance, drug manufacturers may need real-time access to public health data, inventory levels, and regional vaccination records in order to accurately forecast demand for flu vaccines and coordinate supply chain logistics. But delays to accessing this data sets timelines back and puts the manufacturer at risk of not having vaccines available in time to avoid a spike in flu infections.
In cases such as this, a data catalog surfaces what exists but without automated provisioning workflows, it can’t shorten the distance between discovery, consumption, and results.
And this bottleneck can have an organization-wide ripple effect: 31% of organizations have missed internal goals due to data access challenges, and 30% have lost revenue because of it.
Pain point 2: The governance and compliance gap
Catalogs excel at inventory management: they can tell you what data you have and where it lives. But you still need to be sure that available data is also governed and controlled. A data provisioning system that enforces policy across inventoried datasets closes the gap.
Without a provisioning system that has a built-in dynamic data governance framework, you risk:
- Manual tagging and policy authoring that takes away from higher priority tasks
- Inconsistent policy enforcement across datasets
- An increased likelihood of compliance violations when sensitive data slips through the cracks
Already, 53% of data professionals report handling governance processes manually, and 62% say those processes delay data access. As AI implementation accelerates and agents increasingly act on behalf of human users, the stakes will continue to rise. Assuming that a data catalog can solve for governance and compliance needs could have serious repercussions down the line.
Pain point 3: Scaling access for data products and AI
Raw tables are no longer the only go-to data format — data products have emerged as the most practical form of data delivery. Because they’re curated, context-rich, and designed for specific use cases, 43% of data leaders say data products will have a high impact on business outcomes.
Data products are also structured and readily available, so non-technical stakeholders have an easy time understanding and using them. That may be great for data democratization and self-service access, but it’s not so great for existing workflows that bet on limited numbers of data users.
Human users and AI agents demand governed, timely data product delivery. As we covered earlier, a metadata-rich catalog is valuable for finding data, but the path from catalog to consumer is still slow and risky without an automated provisioning workflow in between. For AI in particular, the longer it takes to get high-quality inputs, the more innovation grinds to a halt — and the greater the risk of outdated or incomplete data skewing the results.
The solution: Data catalogs with a provisioning layer
The missing link is a dedicated data provisioning layer that integrates seamlessly with the catalog but handles the heavy lifting of data policy enforcement, access, and auditing.
Coupling inventory and discoverability with provisioning and governance covers all your bases, while achieving compliance, efficiency, and scalability. This bolsters data delivery workflows with:
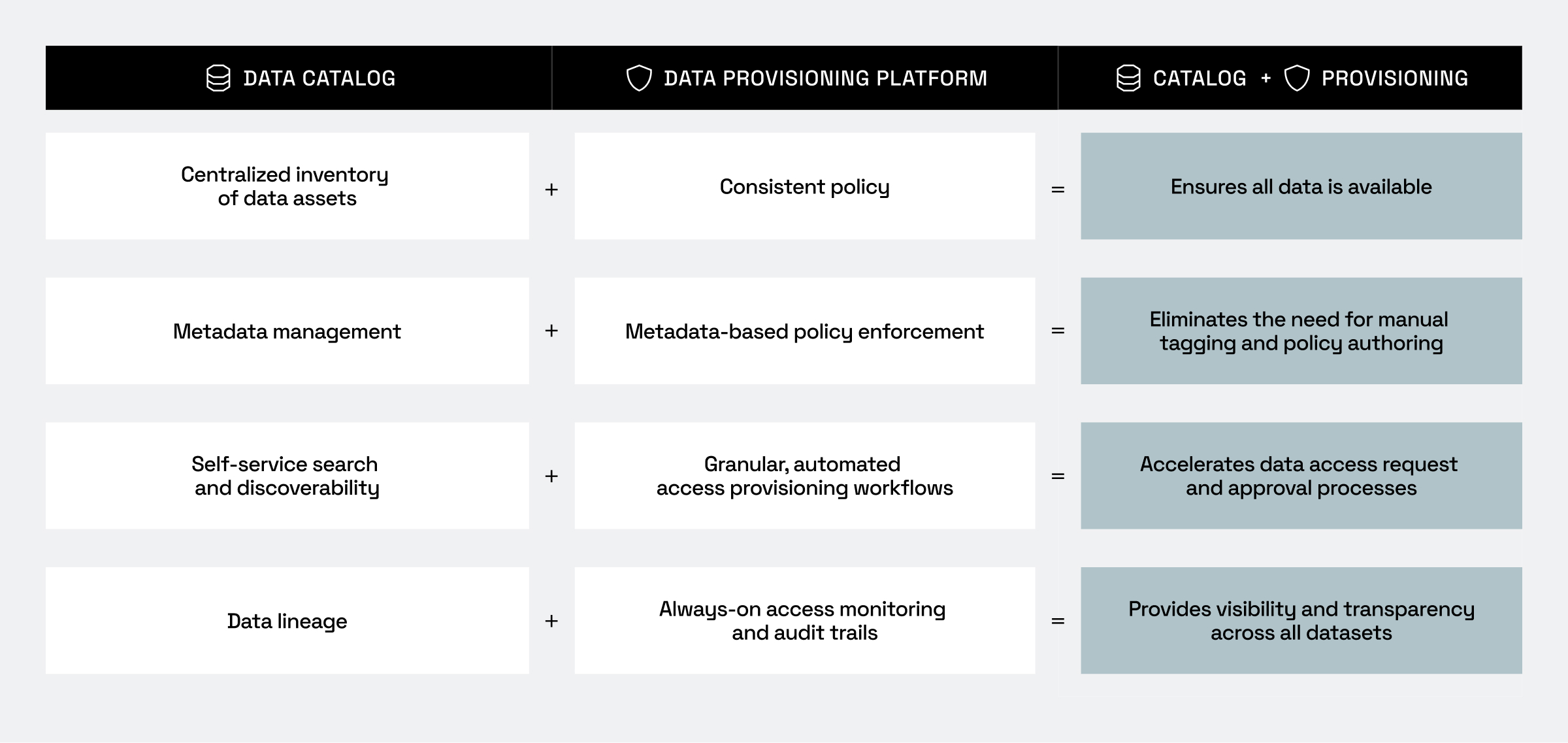
1. A centralized inventory with consistent enforcement
The catalog organizes your data, and the provisioning layer ensures policies are applied uniformly across it. This ensures that data is not only available and searchable, but also fully governed. Data users find what they need, and data owners rest assured that it’s protected – without having to review each and every request.
2. Metadata-driven data governance
Catalog metadata is ingested by the provisioning platform, triggering automated rules that determine who can access what, under which conditions. This significantly reduces the time spent combing through data, manually tagging it, and tediously writing policies to govern how it’s provisioned – so you can focus on higher priority tasks.
3. Granular, automated data access provisioning
Provisioning data access via ticketing systems like ServiceNow – which were built for application access, not data access – causes delays, confusion, and unnecessary headaches. With a data provisioning platform synced to your data catalog, access requests are answered instantly with dynamic access controls, eliminating manual approvals based on static guardrails.
4. Continuous visibility
Catalogs provide important data lineage capabilities, showing you data’s past. But you also need a view into the here and now. Data provisioning platforms complete the picture with always-on monitoring and audit trails, giving you the transparency you need without slowing down delivery.
Together, a data catalog and provisioning platform allow discovery to flow directly into self-service data access, without compromising speed, compliance, or security.
Product in practice: Data catalogs + provisioning platforms
To understand how a data catalog works with a data provisioning platform, let’s look at a real workflow.
- A product manager tasked with improving customer engagement and retention logs into their organization’s data catalog.
- They search for “customer churn prediction” and find a data product comprising customer demographics, transactions, and support interactions.
- They request access to the data product directly through the data catalog.
- Behind the scenes, the request is received by the connected data provisioning platform.
- The data product’s metadata tags indicate that it contains PII, which triggers a masking policy to be enforced.
- With the masking policy enforced, the product manager is immediately provisioned access to the data product because their role and usage purpose match the approved policy parameters.
- The product manager’s access is logged, monitored, and auditable, providing the data product owner and governance stakeholders with full transparency into how the data product is used.
All of this happens automatically and immediately, with no tickets, waiting, or workarounds.
Why now?
Why are we talking about pairing data catalogs with provisioning platforms now? It comes down to three key factors:
Data product adoption
We know that data products are becoming more popular as organizations recognize their viability for improving data utilization. With the embrace of data products comes the pressure to make them immediately accessible without manual intervention or compliance concerns. That’s where a data provisioning platform bolsters a catalog’s core capabilities.
AI innovation
AI systems thrive on structured, context-rich inputs from accurate, high-quality data. If that data can’t be provisioned efficiently, the lag in delivering inputs will stall projects and degrade outcomes. As a result, foundational models and anything built upon them will be brittle and less effective.
The need for speed
Gaining and keeping a competitive advantage requires getting insights faster than the rest of the market. That can only be done by removing the friction between finding and accessing the right data — without unnecessary risks, workarounds, or compliance concerns.
The bottom line on data catalogs and provisioning
A data catalog may be a core facet of the modern data stack, but it’s not the end-all be-all. Without data provisioning, your data asset utilization will be partial at best. With it, your data catalog becomes more actionable and directly tied to the success of your data initiatives.
Your data catalog tells you what’s possible, and your provisioning layer makes it real. Closing that gap puts you in the best position to make your data work harder and gain your competitive edge.
Learn more.
Explore data provisioning for leading platforms.



