Turning data into information and knowledge is a key strategic imperative for both government and commercial organizations – but it comes with a catch. Whether they’re looking to improve customer or citizen services, become more efficient, or drive innovation, companies and agencies alike are faced with the challenge of balancing security with speed to access data.
To complicate this balancing act, organizations must comply with a wide range of data regulations, such as the:
- General Data Protection Regulation (GDPR)
- Health Insurance Portability and Accountability Act (HIPAA)
- California Consumer Privacy Act (CCPA)
- Payment Card Industry Data Security Standard (PCI DSS)
According to The CISO Society 2024 State Of Data Security Report, most businesses are not very confident they have built a zero trust model with least-privileged permissions. In fact, nearly one-third of CISOs said they are not confident at all.
Within this complex environment, though, there is one strategy to begin to ensure security and compliance: building a robust data classification framework.
What is a data classification framework?
Data classification frameworks are a key component of data governance and security, labeling data based on its sensitivity and risk levels, and applicable regulatory requirements.
Using the classifications, organizations are able to:
- Know what data falls under requirements from laws, regulations, contracts, and other sources
- Securely share data with partners, contractors, and other organizations
- Enforce restrictions on access to and the transfer of sensitive data
Without classifying data, sensitive data may be mishandled without you even knowing it. Compliance becomes a nightmare, and data silos grow because it is too hard to merge, analyze, and share data across teams or other organizations.
How do I build a data classification framework?
Building a classification framework requires several steps, including:
- Establishing a data discovery and cataloging system
- Creating a common definition of data identifiers and classifications
- Authoring and implementing data policies
- Monitoring and auditing the data
Let’s take a closer look at some of these steps.
Step 1: Identify dark data
The first step is to find dark data, which is data that has been collected but not used. Once you’ve identified it, you can add it to your catalog of known data assets.
Step 2: Define data identifiers and classifications
Once data is known, you can begin to define data identifiers and classifications.
- Identifiers are a way to classify sensitive data elements, such as names, emails, social security numbers, or employee IDs. They play a role in determining what protections, like masking, row-level filtering, and purpose-based access, should be applied to which data.
- Classifications express data classes and their related properties. Examples include public, confidential, GDPR, or controlled unclassified information (CUI).
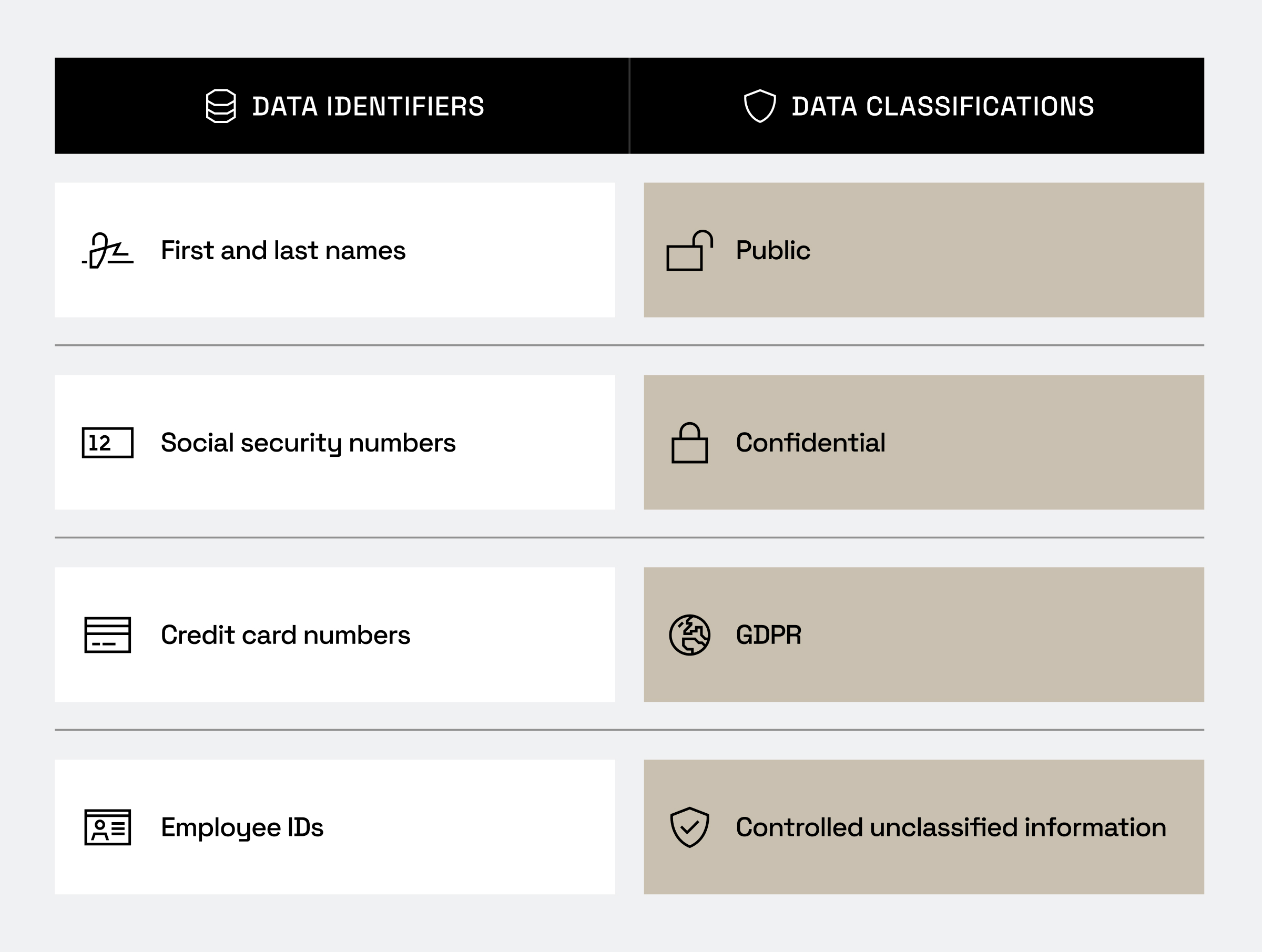
The identifiers ultimately help build the rules to classify the data correctly. Imagine there is a table with just a last name and a dollar amount. While the name could be personally identifiable information, if no other information is present to link the name to an individual, this data could be considered public.
But if a transaction ID that could be used to identify the individual were to be added, this table would be considered sensitive and would fall under the purview of privacy regulations such as GDPR or CCPA.
Step 3: Create access policies based on identifiers and classifications
Using the defined identifiers and classifications, rules can be created to define policies for who can access the data, as well as monitor and alert data governance teams on possible compliance issues or inappropriate exposure. The question then becomes, how does this get implemented in a scalable way within an enterprise?
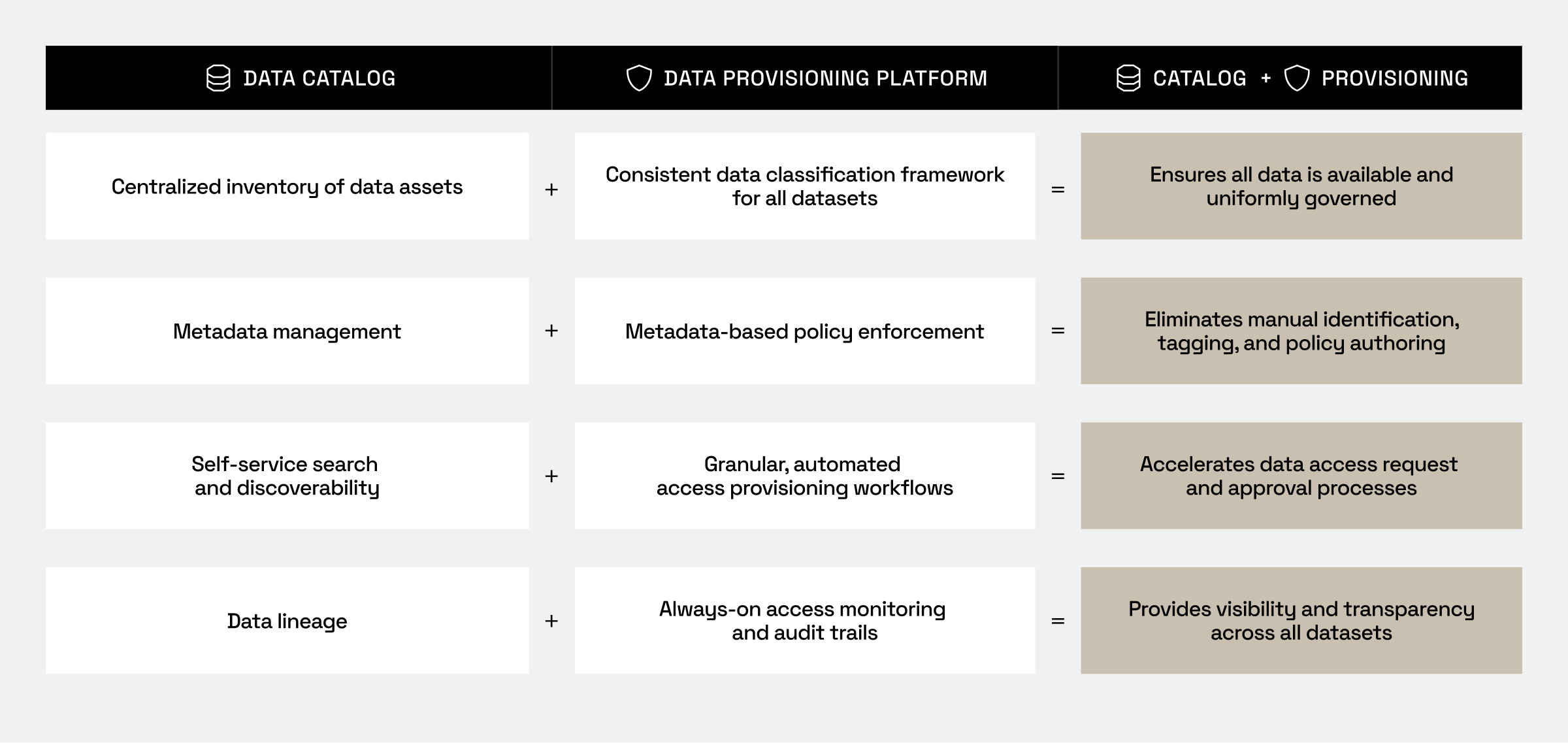
Why should you separate data classification frameworks from data catalogs?
It may seem counterintuitive, but a data catalog is not the right place for classification frameworks to live. Why?
Although catalogs are built to discover and tag data, making them a good place to share data metadata, they do not enforce data access policy, nor do they monitor data and alert for issues.
Instead, data classification frameworks should live in data access governance (DAG) tools that regularly interact with the data and can share identifiers and classifications back to the catalog for informational purposes, such as consumer data discovery and understanding where risky data lives.
DAG tools:
- Regularly scan the data environment for new tables
- Automatically identify and classify data
- Provide always-on monitoring to ensure compliance with policies and regulations
For example, Immuta has a number of customers that use the data catalog to manually tag data, but depend on Immuta to also run data identification and classification that verifies the manual tagging. This ensures that policies are enforced consistently on the right data – without blocking authorized users – and avoids any data falling through the cracks. Because data catalogs lack these functions, they pose a greater risk of both of those outcomes.
How Immuta supports data classification frameworks
With data discovery, classification, governance, and provisioning not just built in, but unified and automated, Immuta is an ideal solution to implement classification frameworks.
- Dynamic data discovery and classification within Immuta provides a clear inventory of available data, categorized by sensitivity and purpose.
- Pre-built and customizable identifiers allow you to get started quickly, while also providing the flexibility to create new rules to identify and classify unique data within your organization.
- An open API means tags can be pushed to data catalogs and other data security posture management (DSPM) tools to provide visibility across the enterprise.
- Automated policy enforcement based on data tags and dynamic attributes ensures sensitive data is accessed by only authorized users.
- A plain-language policy builder simplifies policy creation for technical and non-technical users giving control back to the data governor and the domain owners who know the data best.
- Unified auditing monitors all user activity and sends alerts when defined risk thresholds are breached, helping to ensure compliance with data rules and regulations. And by integrating with security information and event management (SIEM) tools and internal reporting capabilities, you can further accelerate the mandatory compliance reporting processes.
Looking forward: Why data classification frameworks matter now
Because a data access governance tool integrates tightly with the existing data environment – including data catalogs – it is the logical place to build classification frameworks. As organizations increasingly rely on distributed architectures and adopt AI systems, including AI agents, the need for systematic, trustworthy, and actionable data classification frameworks is becoming not just a nice-to-have, but a must-have in order to scale securely.
However, trying to build your classification framework in your data catalog is an unscalable and, ultimately, unreliable solution. Now is the time for commercial and public sector organizations alike to shift to building data classification frameworks within data access governance tools.
Learn more.
See data classification frameworks up close.



