A Guide to Automated Data Access
In Databricks Using Immuta

Scalability and performance go hand-in-hand. If you have great performance, but not a scalable solution, you haven’t solved much. The inverse is also true. This is why the cloud is so successful, and tools like Databricks work so well – they can scale on the cloud by spinning up performance-appropriate compute to crunch data with Spark on demand: scalability and performance.
I already spent some time explaining how Immuta’s attribute-based access control (ABAC) model provides a highly scalable solution — 75X more scalable than role-based (RBAC) solutions like Ranger, as proven by GigaOm’s independent analysis. But that’s only half the picture; without performance, scalability is meaningless.
We’re continuously enhancing the Immuta platform to optimize scalability and performance. In this article, we’ll show you:
First, let’s start with a refresher on Immuta’s native integration with Databricks.
Immuta is not a virtualization solution. We integrate directly with our cloud data platform partners at the data level, providing a non-invasive and performant enforcement point. This blog details our performance results and some new performance enhancements on Databricks that we are extremely proud of; our performance coupled with our scalability provides a modern cloud data access control solution.
First, a quick tangent on how Immuta works in Databricks. Immuta is deployed through a lightweight plugin into the Databricks cluster that leverages open source hooks in the Spark planner, which allows us to rewrite queries to enforce complex policy. Remember, Immuta applies policy using a dynamic and scalable ABAC model coupled with this native enforcement architecture, providing the best of both worlds: scalability and performance.
This is important for Immuta customers that deliver cloud data innovation on Databricks, such as AstrumU, S&P Global, Janus Henderson, and others.

In Databricks Using Immuta
Using the same TPC-DS tests¹ that Databricks referenced in their performance blog post on Adaptive Query Execution: Speeding Up Spark SQL at Runtime, and masking 107 STRING columns across 14 TPC-DS tables with salted SHA-256 hashing, you can see very little variation in performance against the 100GB scale factor of TPC-DS. In fact, for most queries the latency was slightly over a second.
Other details:
You can download the raw results data here.
The key takeaway is that applying intensive masking, such as hashing, on many columns (107 of them) adds very little overhead in the TPC-DS benchmarks (more details in the next section).
Ok, so how have we made our Databricks integration even more performant?
If you can micromanage when value masking occurs, you can get significant performance gains. For example, naïvely creating a view that hashes a column will require all the values in that column to be hashed before other operations can be performed (such as joining). This can add a significant amount of overhead, especially on petabytes of data.
Immuta has implemented complex logic we term “smart mask ordering” that considers the types of queries and the masking techniques to avoid masking until the “last possible second”. This results in negligible overhead for column masking under many scenarios.
TPC-DS queries do all their joins on the INT columns and do very little scanning of the STRING column types. We masked with hashing because hashing retains referential integrity on joins and is an intensive operation; but is limited to STRING types. This is why we saw good performance numbers on the TPC-DS benchmark, even with so many columns masked and no smart mask ordering – there were very few scans performed on the columns. With this in mind, to do a more relevant test, we took a hand-crafted query that does a join across 4 salted SHA-256 hashed columns².
The results are staggering.
Query: select * from synthetic_crime_data a join synthetic_crime_data b on a.address = b.address and a.area_id = b.area_id and a.area_name = b.area_name and a.crime_code = b.crime_code limit 5;
Masked columns: address, area_id, area_name, crime_code masked by sha256 hashing with salt
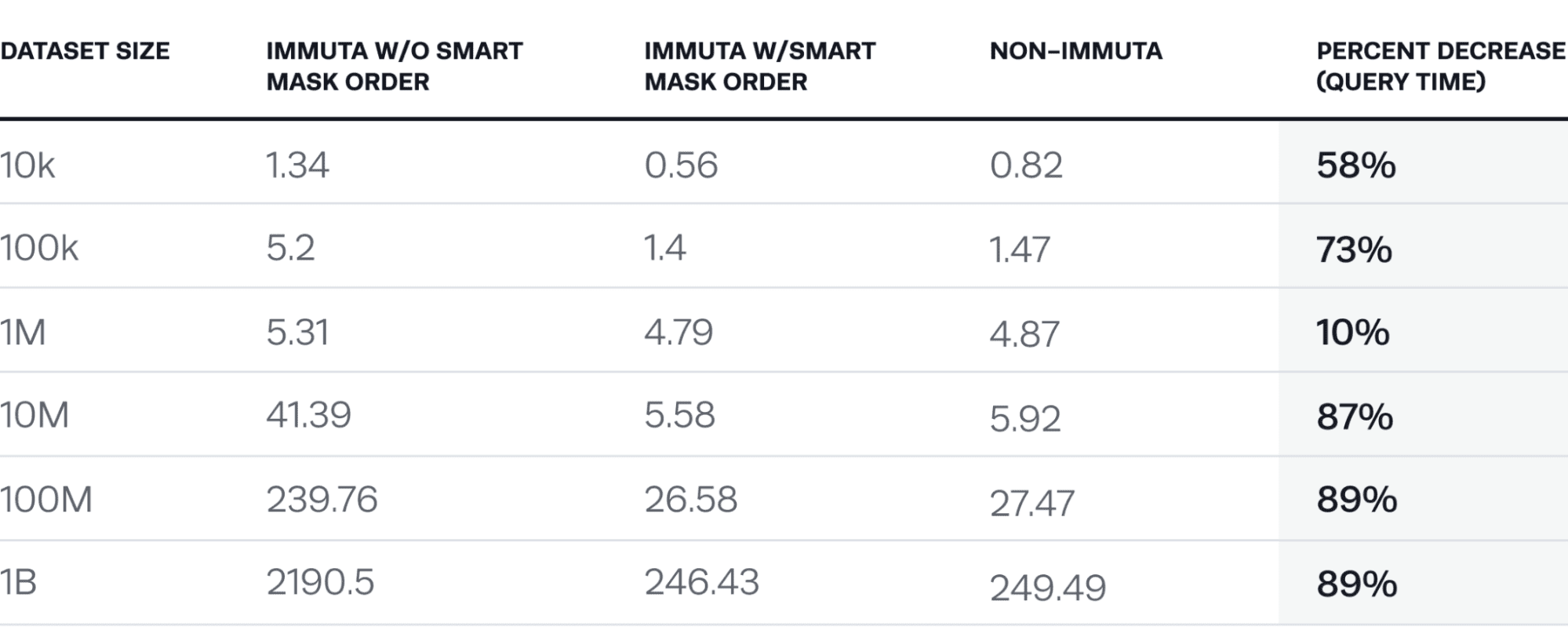
The key takeaway from this chart is that if you were to create a view that masks columns (not using Immuta), depending on the masking algorithm used, you would see results very similar to the “Immuta w/o smart mask order” column. This is due to the fact that with the view approach, Spark must compute hashed values for each of the four columns on one side of the join (this is a self join so it will leverage ReusedExchanges as an optimization). The amount of hashing operations = the amount of rows x the amount of columns masked, which means a total of 4 billion hash operations for the 1B data set. With smart mask ordering, this is reduced to a total of 5 (yes, five) hash operations (since it happened last and the limit of 5 is applied).
To see the scalability and performance of Immuta in your own Databricks environment, request a 14 day free trial of our SaaS offering.
The Immuta engineering team believes in transparency and reproducibility in any product claims so every organization can verify them in their own environment. Because of this, we released a new performance test notebook that makes it easier for prospective or existing customers to run this same TPC-DS test suite themselves and see the results. You can even combine this performance test with the scalability tests described in the GigaOm article, which also uses these same TPC-DS tables.
1. TPC-DS data has been used extensively by Database and Big Data companies for testing performance, scalability and SQL compatibility across a range of Data Warehouse queries — from fast, interactive reports to complex analytics. It reflects a multi-dimensional data model of a retail enterprise selling through 3 channels (stores, web, and catalogs), while the data is sliced across 17 dimensions including Customer, Store, Time, Item, etc. The bulk of the data is contained in the large fact tables: Store Sales, Catalog Sales, Web Sales — representing daily transactions spanning 5 years.
2. You might want to mask a column in a way that does not allow users to join on it, but also masks consistently so the data in that column can be grouped/tracked (such as a hash). This can be managed in Immuta – you can control if a masked column retains referential integrity or not down to the use case the analyst is tackling.