GigaOm Report & Webinar: The Advantage of ABAC Over RBAC
Dig deeper into GigaOm's analysis of ABAC vs. RBAC


The good news is no.
The better news is you are already 90% of the way there and probably don’t even know it!
Before we get into the how, let’s first describe the difference between the RBAC and ABAC forms of data access control. As we’ve outlined in great detail in this blog, the acronyms are actually very poorly named. When breaking out the acronyms – Role-Based Access Control (RBAC) and Attribute-Based Access Control (ABAC) – it’s easy to assume all that changes is Roles become Attributes. But that’s not true at all.
The difference between RBAC and ABAC is really STATIC vs DYNAMIC.
I’m going to use the most basic (fake) code example to show you why. Let’s say you have the following code:
def print_full_name(first_name, last_name) {
full_name = first_name + “ “ + last_name;
print full_name;
}Now, when I want to print someone’s full name, I can inject the first_name and last_name variables in the print_full_name function, voila. So whether I have ten full names to print, or 1,000 full names to print, I only ever need to write this single print_full_name function. It can DYNAMICally print any and all names.
Alright, let’s say I have three full names and I’m NOT able to use variables in functions. I would have to do this:
def print_steves_name() { -- notice no variables allowed
print “Steve Touw”;
}
def print_matts_name() {
print “Matt Carroll”;
}
def print_mikes_name() {
print “Mike Schiller”;
}This does not scale because I need to create a function for every name I need to print. I know this looks ridiculous, but guess what, that’s RBAC. This is the difference: ABAC is able to inject variables at runtime, as we saw in the print_full_name function, but RBAC must pre-create all possible scenarios up front (print_steves_name, print_matts_name, etc). It is STATIC – and static doesn’t scale.
Now that we have that foundational understanding, let’s convert this into real data policy language. I’m going to use open source Ranger as my RBAC example and Immuta as my ABAC example.
Instead of printing names, we are going to build row-level policies that restrict access to only certain countries. Take this table of fake credit card transactions, for example:

Now we want to restrict users to only see the country they are allowed to see, per their role…yes, I’m using the word role on purpose so you can see it has nothing to do with role vs attribute – it’s all about static vs. dynamic.
With Ranger (RBAC), the policies would look like:
Policy 1: Role: CN, Row Level Filter: TRANSACTION_COUNTRY = ‘CN’
Policy 2: Role: CZ, Row Level Filter: TRANSACTION_COUNTRY = ‘CZ’
…
Policy n: Role: PT, Row Level Filter: TRANSACTION_COUNTRY = ‘PT’As you can see, you must build a policy for every unique country you need to restrict, just like you had to write a function for every name you wanted to print.
With Immuta (ABAC), the policy (singular) would look like (your existing roles will be treated like groups):
Policy 1 (and only): TRANSACTION_COUNTRY IN (@groups)
In the actual Immuta UI:
We can also get tricky and replace the TRANSACTION_COUNTRY physical column name with a tag reference instead. This will help if the TRANSACTION_COUNTRY column is spelled inconsistently across tables (and even different databases) but tagged consistently:
Or, a shortcut for users not familiar with SQL:

As you can see, we are able to build a single policy which, at runtime, injects the user’s country via that @groups variable, which represents your already existing RBAC roles. This is very similar to how we built a single function to print the full name, no matter what first and last name get passed into it. It also spreads the policy across all tables with that particular tag, removing further policy bloat.
It gets worse for RBAC, though. What if someone has access to more than one country (like the USA and Canada)? You guessed it – they would need to build policy for every one of those cases as well.
Role: US or CN, Row Level Filter: TRANSACTION_COUNTRY = ‘US’ OR ‘CN’
This is not a problem for ABAC because, again, all countries are injected at runtime.
But wait, there’s more. What if a user has FR but gets added to UK two weeks later, resulting in a new role “FR or UK”? The problem is, that user will never see the UK data until someone remembers to go into the Ranger and add the new policy!
Role: FR or UK, Row Level Filter: TRANSACTION_COUNTRY = ‘FR’ OR ‘UK’
Can it get worse? Yes, it can.
What if you have these policies now, in this order:
Policy 1: Role: FR, Row Level Filter: TRANSACTION_COUNTRY = ‘FR’
Policy 2: Role: FR or UK, Row Level Filter: TRANSACTION_COUNTRY = ‘FR’ OR ‘UK’
This results in the same problem, that the user will never see the UK data. RBAC tools like Ranger must consider policy order as well, since everything is static. So in this scenario, FR would get hit first (Policy 1), since the user belongs to that role in addition to “FR or UK” (Policy 2), this results in Policy 1 executing for that user rather than Policy 2.
But can’t I just remove the user from FR when I add them to “FR or UK”?
The answer is maybe. What if that FR role grants them access to something else in some other system? At minimum, it’s another thing you have to remember to do – before you add anyone to a new role, you need to consider all other roles they belong to, what new policies need to be created, in what order, and what roles you may need to remove them from in order to consider policy order. Ouch. It removes the wonder from why making access changes in an RBAC system is such a house of cards.
You can easily see how you can quickly end up with hundreds or thousands of policies with RBAC vs a single policy with ABAC/Immuta. In fact, GigaOm did a study of Ranger vs. Immuta and came to the same conclusion:
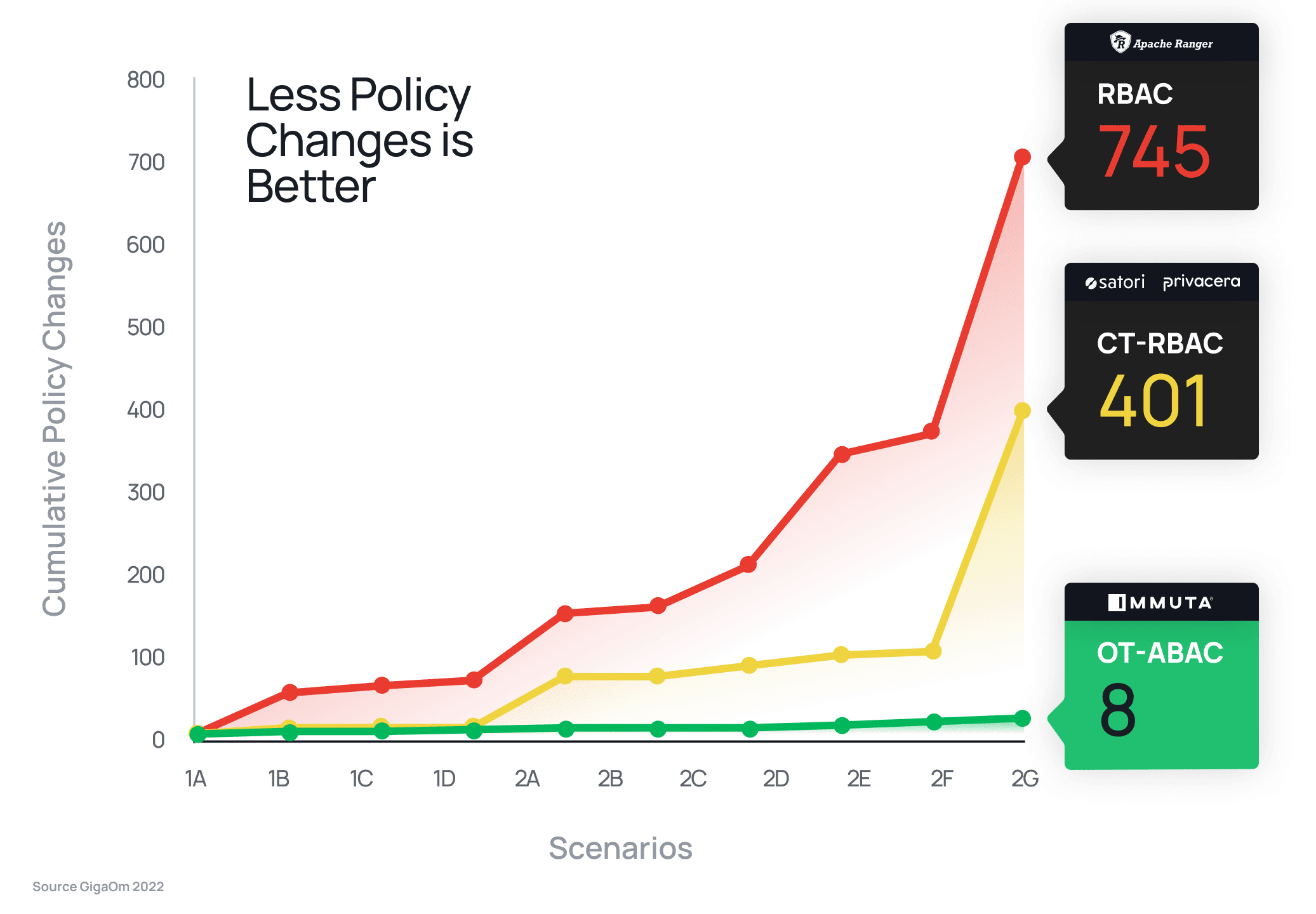
When compared head-to-head with Ranger’s RBAC approach, Immuta reduced policy burden by 93x, requiring just eight total policy changes vs. Ranger’s 745 to satisfy the same security requirements. The study also found that Ranger was unable to complete any advanced data security scenarios, while Immuta’s ABAC approach met each requirement with a single policy change. GigaOm’s results show plainly the implications of a static (RBAC) vs. dynamic (ABAC) model.
Hopefully it has become clear through the scenario above that modernizing to ABAC does not require much work at all. You already have all users assigned to their country roles, and simply need to create a single ABAC policy, not hundreds or thousands of RBAC policies.
But you said I’m only 90% of the way there? Yes, that’s true. To make ABAC truly work in this scenario, you would want to kill all the roles that represent access to two or more countries. For instance, you’d want to break a role like “US or CN” into individual country roles (“US”, “CN”) and ensure the user is in each. There is potentially some work there…but doesn’t that work make you feel cleaner? Ugh, that’s ugly otherwise and hard to maintain and understand who can access what data.
Modernizing to ABAC does not require a massive shift in how you tag users with metadata. Instead, it’s a massive paradigm shift in how you manage policy in a scalable, evolvable, and understandable manner. You already have all the roles, but you are now empowered to build policy separated from the roles in a dynamic and variable-based way. Nobody wants to write code without variables – it’s impossible to scale and manage – so why do you want to manage your data policies that way? You shouldn’t. And with Immuta’s ABAC approach, you don’t have to.
For more on the evolution of access control past RBAC and towards a future with ABAC, check out this white paper.
Request a demo from an Immuta expert today to see the benefits of ABAC faster than ever.

Dig deeper into GigaOm's analysis of ABAC vs. RBAC


