A Guide to Automated Data Access
In Databricks Using Immuta


The new Databricks Enterprise Cloud Service architecture provides powerful network security capabilities, however, a lesser known benefit is that it enables Data-as-a-Service.
Data-as-a-Service gives you the ability to share data and provide compute and analytical tools along with it, providing data consumers with a full “data experience” in addition to a one-stop-shop for data. More specifically, it allows data providers to expose Databricks compute to data consumers, including consistent, analysis-ready data. This gives data consumers the ability to add their own data to the Databricks environment so they can create a robust set of inputs to drive new analytical models that provide a competitive edge.
How does Enterprise Cloud Service make this possible? At its foundation, Enterprise Cloud Service allows the creation of workspaces in a single VPC, across multiple VPCs in a single AWS account, or across multiple AWS accounts – all mapping to the same Databricks account. You can think of this as a dedicated Databricks URL for each data consumer.

In Databricks Using Immuta
This provides many benefits, including:
Initializing the Enterprise Cloud Service data sharing environment is easy. The data provider can store their data once in S3, create a global GLUE Catalog defining their tables once, and then spin up white labeled workspaces for each data consumer. Below is a simplistic diagram of that architecture:
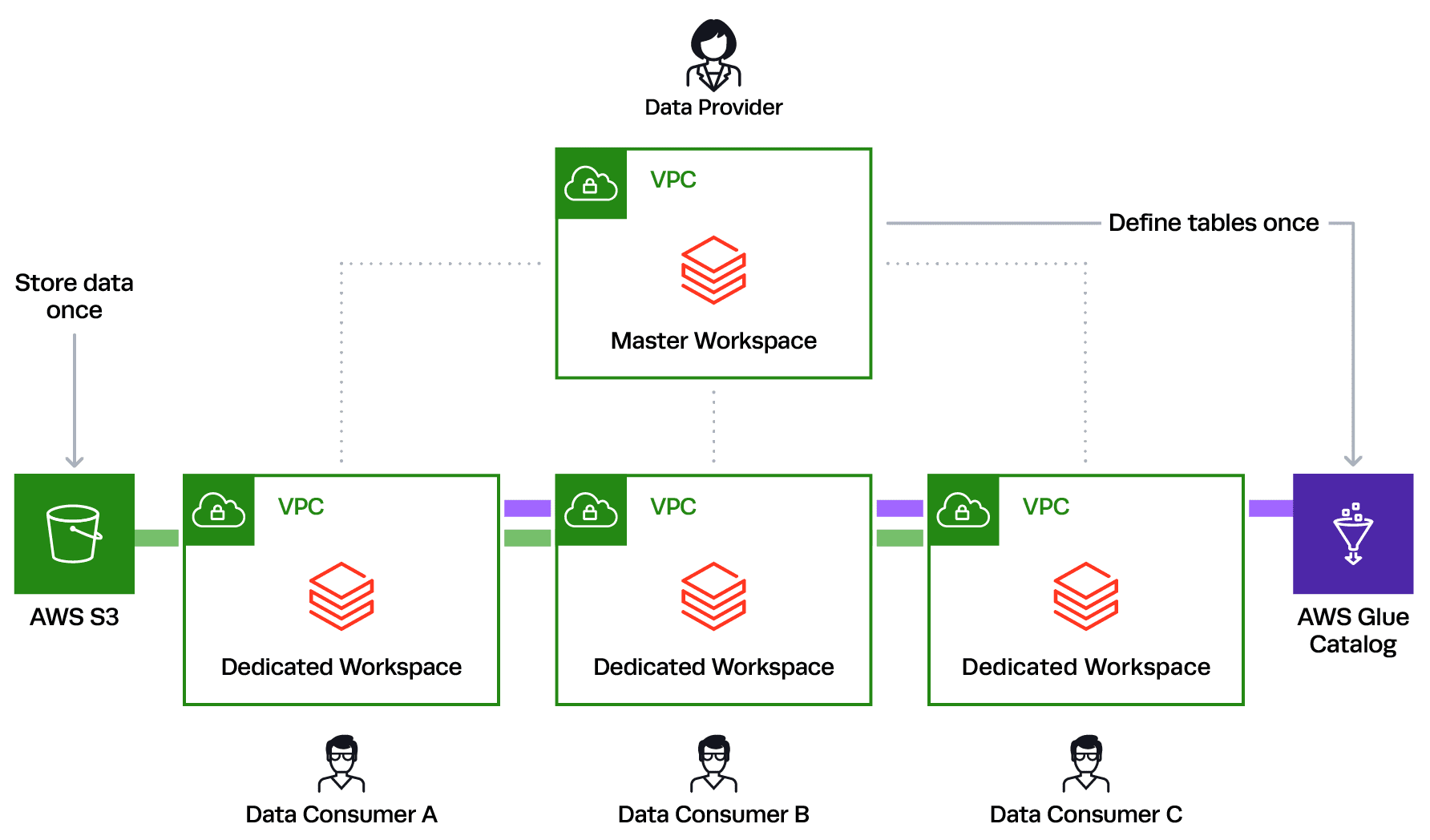
However, this is not the complete picture. As a data provider opening your data internally and externally, you must filter out certain tables or rows of data based on what the data consumer has paid for or what different business units should have access to. This may also include masking sensitive columns for untrusted data consumers while maintaining the ability to open those columns for trusted consumers who have signed a Business Associate Agreement (BAA), for example.
This severely complicates the above diagram because it means you would have to maintain individual copies of data as well as different catalog table definitions for every data consumer workspace. This quickly becomes too complex to manage. This is where the Databrick’s partner, Immuta, completes the Data-as-a-Service architecture.
With Immuta, you are able to reference the single Glue Catalog to build table-, row-, and column-level controls that will enforce policy dynamically, no matter the Databricks workspace. For example, I could build a rule in Immuta to hide any rows that contain data outside of the U.S. for data consumers that are U.S.-based. This rule will dynamically be applied natively in Databricks/Spark based on the user executing the query and their attributes (if in U.S. or not), no matter the Databricks workspace or identity management system.
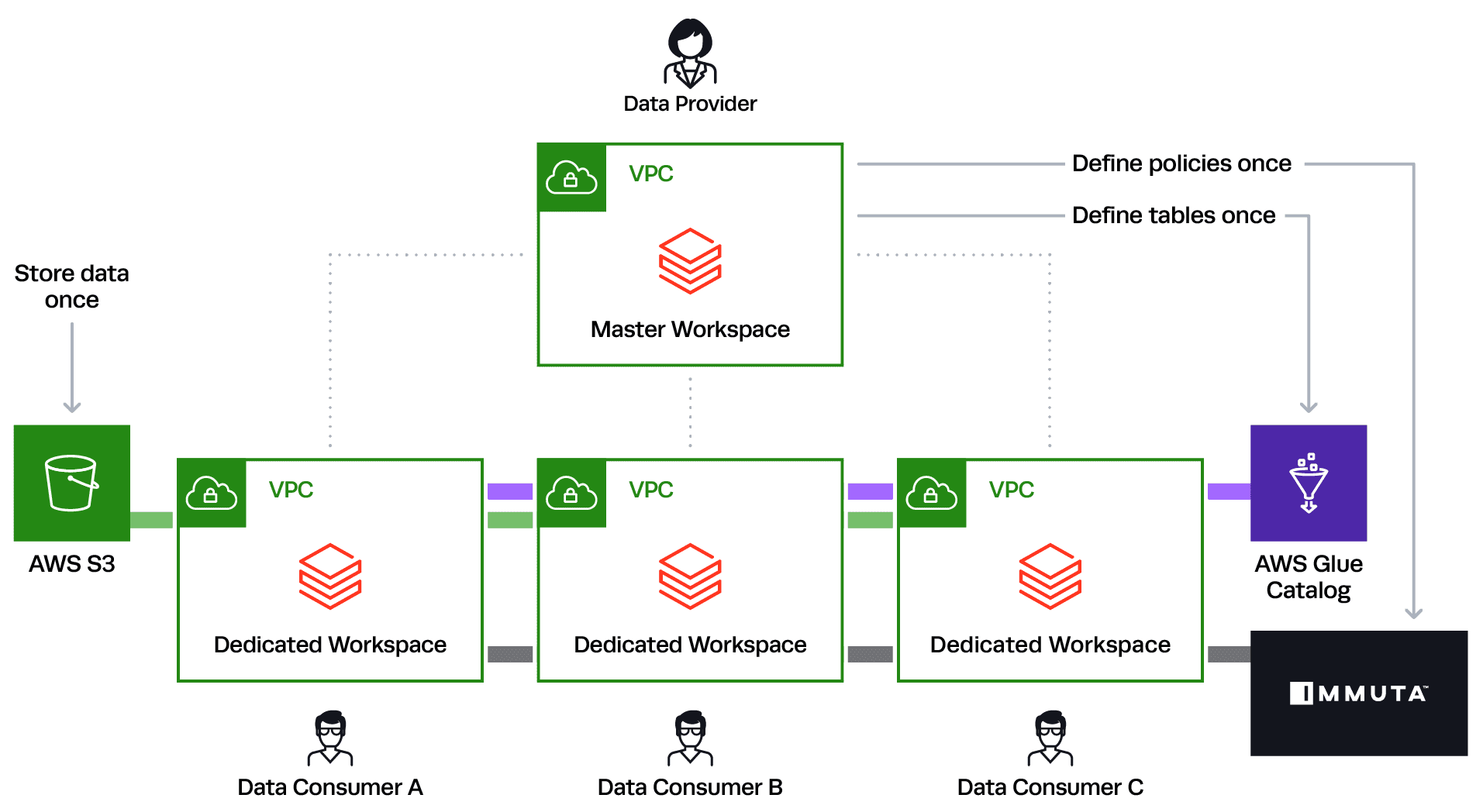
Leveraging this architecture allows for massive scalability because you can continue to maintain a single copy of your data and definition of your catalog tables, as well as a single consistent definition of your policies across all data consumers with Immuta. You will easily be able to provide a powerful and secure Data-as-a-Service platform that delights your data consumers.
Please reach out for more information on this architecture at [email protected] or request a free demo of Immuta.


