
Over the last few years, data catalogs have delivered on an important promise: they’ve made it dramatically easier for organizations to understand what data they have. Teams can search across domains, see descriptions and quality signals, and finally get visibility into assets that were previously hidden inside warehouses, pipelines, and applications.
That progress matters. For many organizations, building a reliable inventory of data was a massive undertaking, and catalogs solved a real discovery problem.
And yet, for all that progress, a familiar frustration remains. The moment users try to actually use the data they’ve found, the experience often breaks down.
They can see the data. They understand what it is. They know it’s valuable. But getting access still feels slow, manual, and unpredictable.
The reason isn’t that catalogs failed. It’s that discovery and delivery were never the same problem to begin with.
When discovery outpaces delivery
Catalogs were designed to answer a specific question: What data do we have, and how do we describe it in a way people can understand? They were built as metadata systems, not policy engines. Their role is to surface information about data, where it lives, how it’s structured, who owns it, and whether it meets quality standards.
That role remains critical.
The problem shows up after discovery. Once users find what they need, the path to access is still fragmented. Governance, security, IT, and data owners are often involved through a series of manual handoffs. Requests are routed through ticketing systems. Policies are interpreted differently depending on the platform or team involved.
In practice, catalogs can end up acting as a highly visible entry point into a long, opaque approval process. Users find a dataset, copy the link, and paste it into a ticket. From there, it disappears into a queue with no clear sense of how long access will take or who will ultimately decide.
As visibility increases, demand increases with it. More people see more data. But the organization’s ability to provision access hasn’t changed. In some cases, the gap actually widens.
What actually has to change
When discovery outpaces delivery, the system doesn’t just slow down, it starts to behave unpredictably. Data leaders aren’t dealing with a usability issue; they’re dealing with a structural mismatch. The organization has optimized for findability without modernizing the way access decisions are made and enforced. Until delivery is treated as a first-class problem alongside discovery, catalogs will continue to expose demand faster than the enterprise can satisfy it.
The operational cost of visibility without access
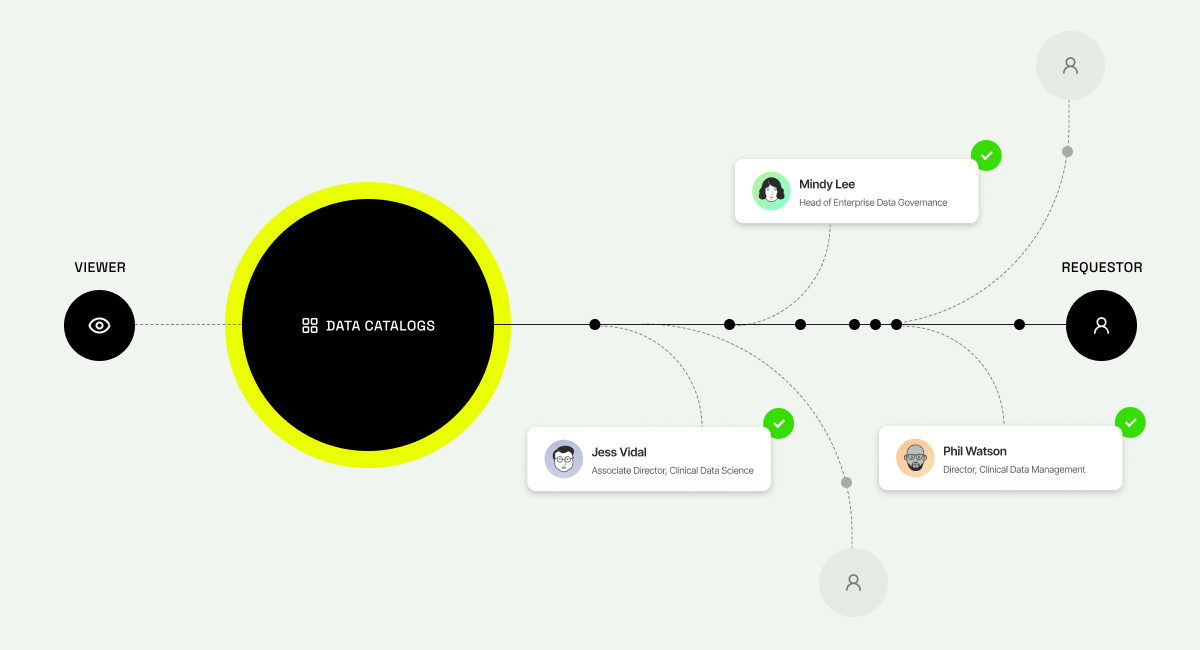
When everyone can see data but almost no one can get it quickly, the operational consequences ripple across teams.
Analysts wait. Engineers burn cycles answering the same access questions repeatedly. Security and governance teams struggle to keep decisions consistent because every request becomes a one-off interpretation of policy. Backlogs grow, and frustration becomes normalized.
Over time, one of two things tends to happen. Either everything slows down as teams try to manage the growing volume of requests manually, or people start working around the system altogether. Shadow pipelines appear. Data gets copied into places it shouldn’t live. Temporary workarounds become permanent patterns.
None of this happens because teams don’t care about governance. It happens because the process can’t keep up with the scale of demand created by modern data environments.
The more successful the catalog is at surfacing data, the more pressure it puts on a provisioning model that was never designed to operate at that scale.
Why data catalogs were never meant to solve access
It’s important to be clear about what catalogs are, and are not.
Catalogs are architected as metadata repositories. They establish a shared understanding of data assets and provide a foundation for quality, stewardship, and discovery. They were never intended to evaluate entitlements, enforce access policies, or automate delivery across platforms.
That separation wasn’t a flaw. It was a deliberate design choice.
The challenge now is that data access no longer happens in a narrow set of applications with tightly controlled logic. Data is converging into shared platforms. Humans access it through notebooks and BI tools. AI systems and agents increasingly rely on the same metadata to decide what data to consume.
As AI-driven demand accelerates, that gap becomes more visible. Agents can use catalog metadata to identify relevant data, but without governed provisioning behind it, they hit the same manual barriers as humans, only faster, and more frequently.
The result is a growing mismatch between what users and systems can discover and what they can actually use at the pace they need.
When catalog initiatives fall short
This gap often shows up after significant investment. Building a comprehensive catalog takes time, effort, and organizational alignment. Many enterprises have gone through multiple iterations trying to get it right.
The disappointment doesn’t come from the catalog itself. It comes from the expectation that discovery alone would unlock access.
Without a provisioning strategy designed to operate at scale, the same manual approval processes resurface. Access requests still rely on tickets. Data owners and legal teams are still pulled into ad hoc reviews. The experience reverts to the same bottlenecks, just with more people asking.
In those moments, discovery becomes a “nice to have” rather than a catalyst for value. Teams can find data, but they can’t use it efficiently. The underlying problem remains unsolved.
What changes when discovery and provisioning connect
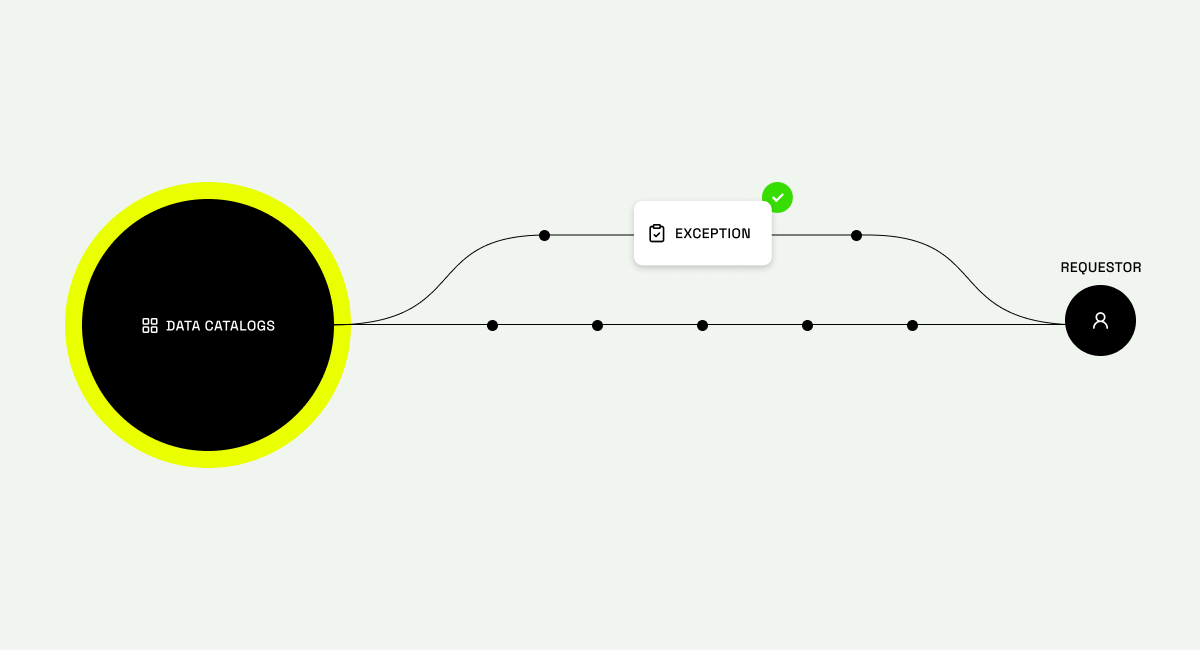
When governed provisioning is connected to discovery, the entire data experience changes.
Users don’t just see datasets; they see the policies that apply to them. They understand what access looks like, whether it’s masked by default, whether exceptions are possible, and how long approval typically takes. In some cases, access can be granted automatically based on existing entitlements, with exceptions routed through well-defined workflows.
The timeline compresses from weeks to minutes, not because governance is bypassed, but because policy evaluation and enforcement happen at the moment of request. Manual review is reserved for the cases that actually require it.
Everything becomes workflow-driven. Discovery is a workflow. Understanding policy is a workflow. Requesting access is a workflow. Receiving entitlements (or requesting an exception) is a workflow. Instead of a reactive ticket queue, access becomes an integrated part of how data is used.
This is also how governance becomes more consistent. Policies are applied uniformly. Decisions are explainable. Users aren’t guessing what rules apply or where their request stands. Visibility and usability improve together.
What actually has to change
For data leaders, the takeaway isn’t to “modernize the catalog.” Catalogs already do what they were designed to do.
The shift is to modernize the workflow that moves data from discovery to delivery. That means treating provisioning as a strategic capability, not an afterthought. Discovery and governed access need to operate as a connected experience, so every dataset users can see is paired with a clear, scalable path to access—whether the consumer is a human or an AI agent.
When discovery and delivery are aligned, catalogs stop stalling. They become the front door to a system that can actually put data to work at enterprise scale.
If this resonates, the next question is practical: what does it actually look like when discovery and governed access are connected in the real world? This piece explores how organizations are closing that gap by linking catalogs directly to access workflows—so finding data doesn’t become a dead end.
See it work.
Explore how organizations connect catalogs directly to governed access workflows.



