
There’s a growing gap between what AI can do and what organizations are ready to control.
Loading the Elevenlabs Text to Speech AudioNative Player…
When I talk to CDOs and data teams – regardless of industry, location, or size – one question keeps coming up:
How are other companies implementing Immuta with AI?
It’s a natural curiosity. When you hear business leaders and industry analysts talking about AI implementation day in and day out, it’s easy to assume that everyone else is several steps ahead of you. So, when I get this question, I know they’re also curious about how other companies are using AI.
The truth is, while many organizations are starting their AI implementation journey, few are running full scale agentic AI in production workloads. Experimenting with low-barrier-to-entry AI tools and free LLMs may help simplify workflows, but they’re a far cry from having an autonomous agent making trustworthy decisions.
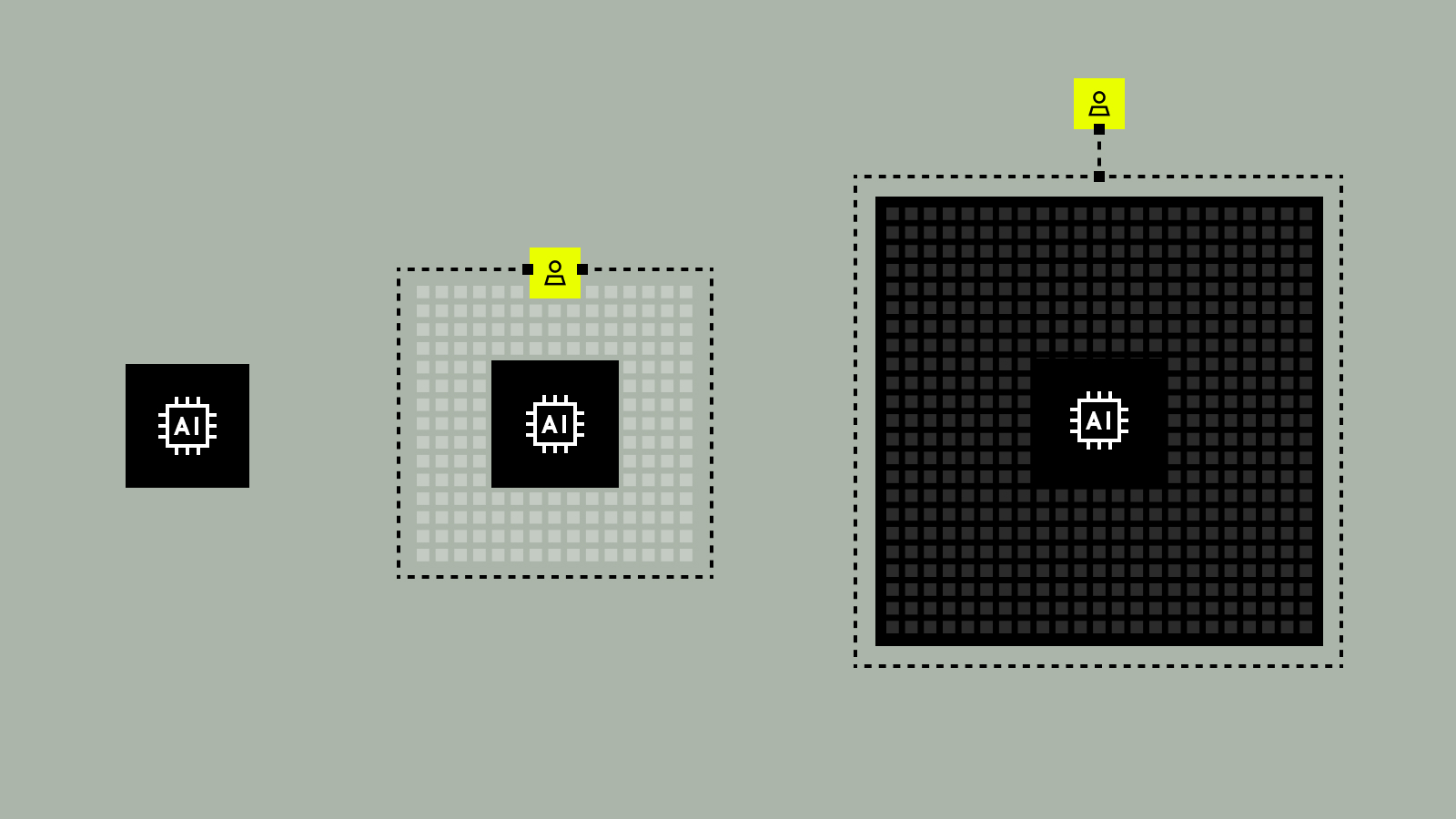
Through my conversations with Immuta customers and partners, I’ve come to see three levels of AI implementation emerging. In this blog, we’ll take a closer look at each, their risks and opportunities, and key milestones to cross before giving AI more autonomy. Because the organizations that understand how to implement AI responsibly will be the ones best positioned to lead as adoption accelerates and matures.
The gap between AI implementation vision and reality
Before we go into the levels of autonomy, it’s worth answering the question of why they exist in the first place.
The AI implementation spectrum is broad, with some organizations eager to move fast while others hold back, waiting for clearer guidance, better tools, or more regulatory certainty. But one thing is consistent:
AI agents are the most prominent example of this. These systems are decision-makers, not just order-taking chatbots or assistants. That alone raises the stakes for implementation, because with greater autonomy comes a greater risk of unintended or unanticipated actions.
Having a roadmap for what to expect and control throughout the AI implementation process can help mitigate those risks and ensure that AI agents deliver on their potential – without compromise or consequences.

Level 1: Determinations for low-risk decisions
What it is
We start where most organizations are currently operating or experimenting. Using AI to suggest how to handle a low-risk decision is a straightforward use case that’s applicable across industries.
Consider a chatbot that helps your customers find answers faster. The LLM is pointed at your website to easily answer their questions. You may eventually add the option to provide some limited account information to help reduce the amount of calls coming into your call center. Regardless, the risk is rather small to start with a FAQ-type chatbot that scrapes publicly available information.
The pros
The pros of this stage for data teams are clear:
- Quick wins and fast iteration
- Sensitivity and security are not major concerns yet, especially with public information
- Little pushback since stakes are low
- Minimal risk exposure
- Clear separation between AI outputs and human action
The cons
Don’t let the simplicity of this implementation give you a false sense of security. The biggest risk is assuming these preliminary use cases are indicative of AI’s maturity – they’re not.
It all comes down to context. As use cases – and the decisions that come with them – become more complex, context about data sensitivity, user roles, downstream impact, or other critical details becomes even more important. Without it, AI agents are bound to fail in enterprise settings and expose organizations to greater risk.
The milestones
To avoid this and make your step up in AI implementation maturity as smooth as possible, consider the following milestones:
- Define risk classifications for AI decisions. Categorizing by high-, medium-, and low-risk decisions helps determine where automation is safe and where human oversight is needed.
- Create a governance baseline for AI outputs. Lay the foundation for a scalable system by logging, monitoring, and reviewing even basic AI suggestions. This will help you proactively correct any issues and put safeguards in place upon which you can continue to build.
- Start with tagging data based on business context, not just format. Labels that only focus on data’s format don’t say anything about its sensitivity. Context-based tags like PII, PHI, or location enable smarter, risk-aware automation in the short and long term. You must understand your data sensitivity before working to secure it.
Once these milestones have been prioritized and achieved, it becomes easier to move to the next phase of AI implementation.
Level 2: Some autonomous activity with full human control
What it is
By now you’ve established a trustworthy workflow for AI agents to handle low-risk access suggestions. The next phase involves giving them more leeway to initiate action and make autonomous decisions.
It’s worth noting that these decisions should still be low-risk. For instance, an AI agent may automatically approve access to datasets that have been classified as non-sensitive and leave human review for medium and high-risk approvals. This approach is still human-led, but now you can trust the AI to make certain decisions on its own – assuming those decisions fall within pre-approved risk parameters.
The pros
Because AI agents can handle slightly larger decisions in this phase, you can:
- Significantly reduce manual effort associated with routine tasks
- Provision data access – and enable insights – much faster
- Easily scale governance with the right controls in place
The cons
This approach only works if data tagging is accurate and systematic. If data is poorly tagged or classifications are inconsistent, agents are bound to make mistakes that could be risky, costly, or both.
For example, an AI agent may auto-approve access to a data product that is either not tagged with PII/PHI or is misclassified. But what if that label was inherited from an upstream dataset with different risk classifications? Without human oversight of the label’s accuracy, the agent may be inadvertently exposing sensitive information and compromising compliance.
Another challenge could arise when a data user requests access to a row or column that is masked by default. The AI agent may be unable to understand the rationale behind that one-off request, particularly if the masking means the dataset is classified as “low risk.” Without human intervention, the data in question may either be over- or under-provisioned.
In short, the drawbacks of this phase come down to:
- Unclear provenance of access decisions
- Difficulty tracing downstream impacts of AI actions
- Human oversight becomes reactive instead of proactive
The milestones
To avoid these challenges, focus on reaching the following milestones before moving forward with more advanced or autonomous AI implementations:
- Establish a risk classification framework for AI-triggered actions. This removes ambiguity and ensures automated decisions are consistent with organizational standards.
- Ensure metadata tagging is robust and dynamic. We mentioned the criticality of data tagging. But maturity in this phase also means tags are dynamically updated, since static tags lack the real-time context AI agents need to make accurate decisions.
- Build controls for one-off scenarios. By requiring justifications for access, approval workflows, and triggers for risk thresholds, you can make sure the right data gets to the right people without exposing sensitive attributes.
Once these have been baked into standard AI-driven processes, you can feel confident moving into the third phase.
Level 3: Fully autonomous agents with humans in the loop
What it is
This is where most organizations think they want to go. But despite the hype and promise of emerging tech, few are actually ready for this phase – and even fewer are already there.
In this third phase of AI implementation, agents don’t just assist humans – they act on their behalf. An AI agent might proactively request access to data based on a predicted need, combine datasets for faster insights, or kick off entire workflows in anticipation of business events.
Let’s say an agent is supporting a pharmaceutical drug manufacturer. It detects an early spike in demand for the flu vaccine due to real-time trends and public health data. In response, the agent proactively requests access to inventory data, supply chain logistics, and historical vaccination records by region. Then, it triggers a workflow to accelerate vaccine shipments to high-risk areas in order to meet demand and avoid shortages or delays elsewhere.
The pros
For many organizations, getting to this phase represents a full embrace – and harnessing – of AI’s potential. After all, much of the buzz around AI is focused on passing mundane work to agents, freeing us up to do high-impact tasks.
So, it’s not hard to imagine the pros of autonomous AI agents with humans in the loop:
- Near-real-time decisions with minimal friction
- Major increases in operational efficiency
- Potential for true “always-on” data ecosystems (that don’t require humans to also be “always-on”)
The cons
In this phase, an AI agent can be seen as an extension of a human user. But swinging the balance of control away from humans and toward machines – especially at scale – will only work if you can confidently answer the following questions:
- How do you manage delegated authority?
- What happens if an agent accesses a dataset that contains a toxic join?
- How do you enforce purpose-based controls when a machine is inferring the purpose?
- What guardrails do you have in place to mitigate model bias?
Data and business leaders must align on these questions and develop contingency plans in case something goes wrong. Otherwise, you may find yourself:
- Dealing with unintended consequences from AI agents’ actions
- Struggling to assign accountability to human users
- Covering gaps in cross-functional maturity and collaboration across security, legal, data, and engineering teams
The milestones
The milestones in this phase are highly cross-functional. Because this type of advanced AI implementation can impact multiple departments, it’s critical to consider these milestones early on and develop plans to meet them:
- Build explainability into every AI-triggered decision. To build trust and accountability, you need to not just know that an agent took an action – you also need to know why. This can also help with future model training.
- Create “kill switches” or rollback mechanisms. If you detect unintended consequences, errors, or anomalies, you need a way to immediately halt or reverse AI-driven processes – and know how to avoid future mistakes.
- Formalize human-in-the-loop feedback loops and audit trails. Maintaining a clear record of human intervention – including who, when, and why – provides continuous evaluation and improvement of AI-driven decisions over time.
Lessons from the front lines
If you’re serious about AI implementation — beyond just dipping your toe in GenAI experiments — here are a few lessons I’ve picked up from organizations that are ahead of the curve:
- Treat AI agents like team members. Give them roles, responsibilities, permissions, and supervision. Like any new employee, they will require time and attention to train.
- Don’t skip the governance groundwork. Most AI challenges or failures I’ve seen weren’t model issues — they were governance issues. Make sure your governance framework is solid before you start building upon it.
- Focus on data context, not just data content. Without a shared understanding of context, like risk, purpose, and sensitivity, autonomy becomes dangerous. Your people, your metadata, and your AI agents should all be speaking the same language.
- Scale maturity, not just automation. You can automate chaos just as easily as you automate efficiency. Maturity and foresight are what will set successful organizations apart from those that struggle through AI implementations.
Final thoughts on AI implementation
The path to fully autonomous AI agents won’t be defined by breakthroughs in LLM performance. It will be defined by the people in charge of the agents. The choices you make today around governance, trust, and control will influence how, when, and with what level of success you’re able to implement autonomous AI.
And like many experts, I believe that AI implementation isn’t about replacing humans. Rather, it’s about augmenting human decision-making with systems that are fast, consistent, and reliable. But first, we need to earn the right to trust them.
We’re not 10 years away from that future – we’re 18–24 months away.
So the question isn’t whether your organization will adopt autonomous agents. It’s how you can do so responsibly and in a way that makes your work easier – not harder, more complicated, or more stress-inducing.
The time to start laying the groundwork is now, so you can reap the benefits – and the competitive edge – when the time comes.
Learn more.
Take a closer look at AI-driven data provisioning.


