Permission to
share safely.
Power your data marketplace initiatives and data access governance projects with a unified platform that brings all your data assets and people together.
Take a tour

We are excited to announce a new suite of capabilities that make it easier to securely implement a data marketplace, so you can put data to work faster.
Identify sensitive data, enable access, and automatically enforce policy on all of it — no matter where it lives.
Use intuitive workflows to allow data users, stewards, and governors to negotiate and automate data access and policies.
Scale fast access to data with native integrations across all supported compute and storage platforms.
Make curated data products findable on a single, central platform.
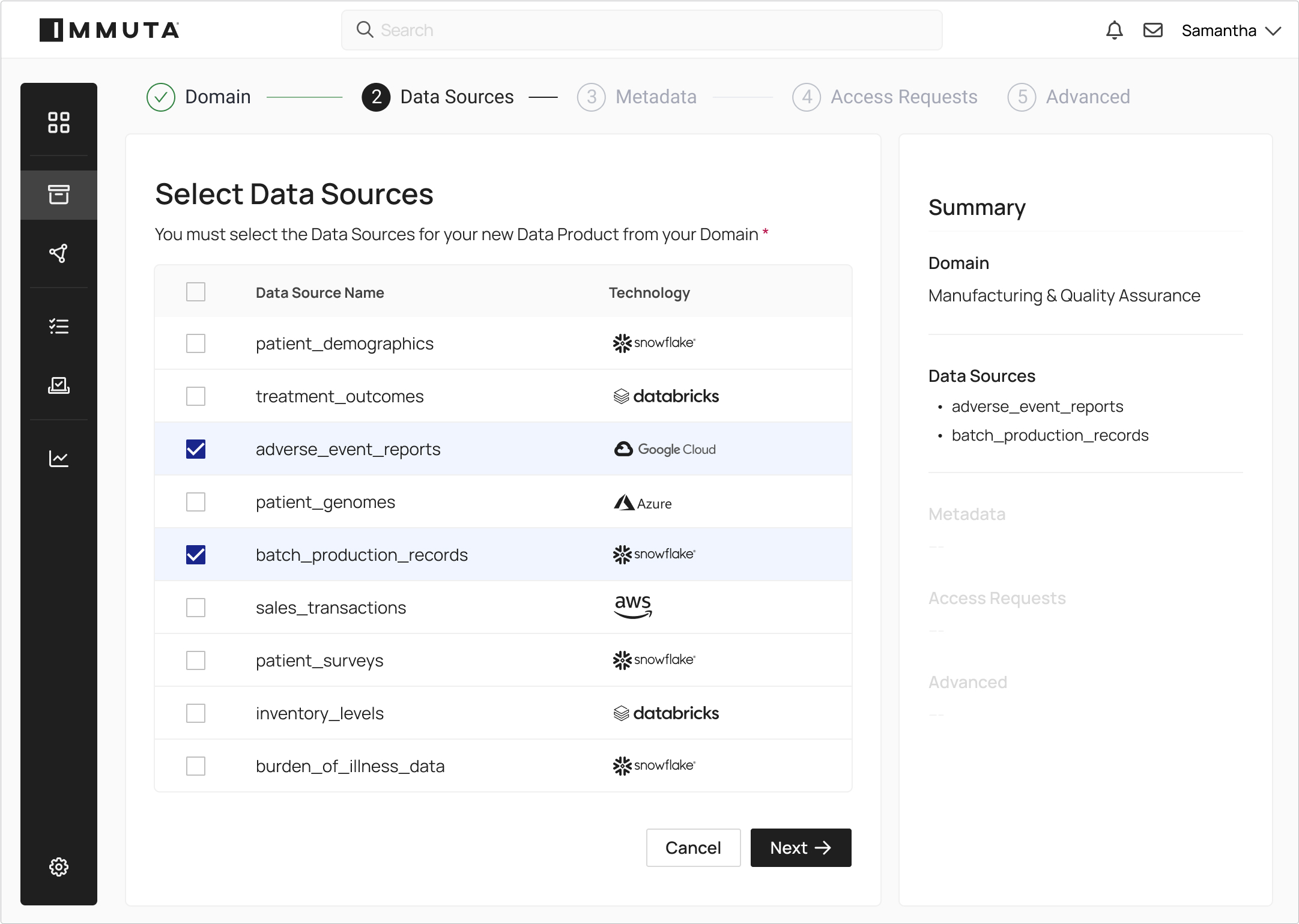
Define logical domains for local control and visibility. Enable business users to manage metadata and access approvals separately from data product owners.
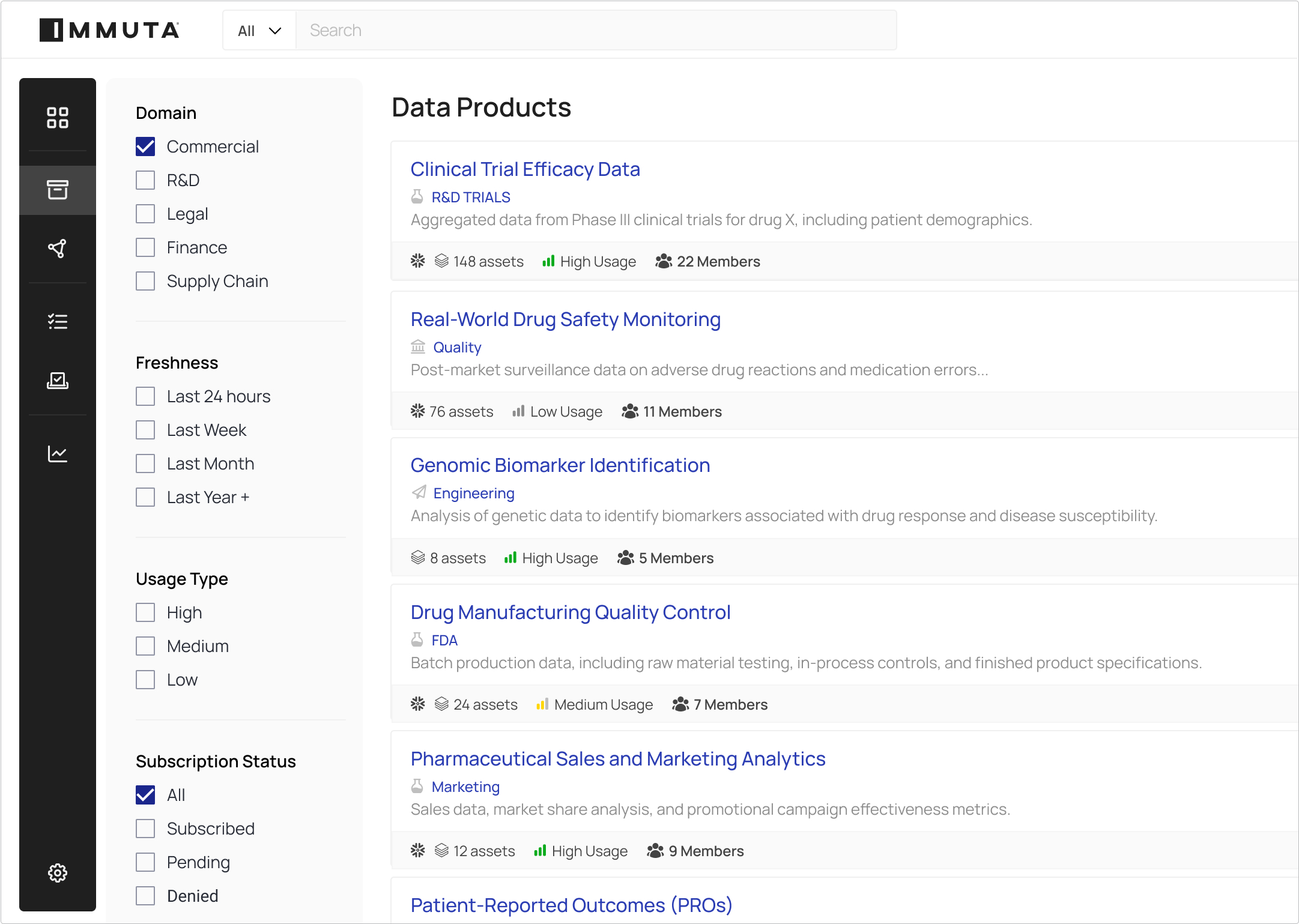
Make it easy for users to search and filter available data assets, and establish a process to request access.
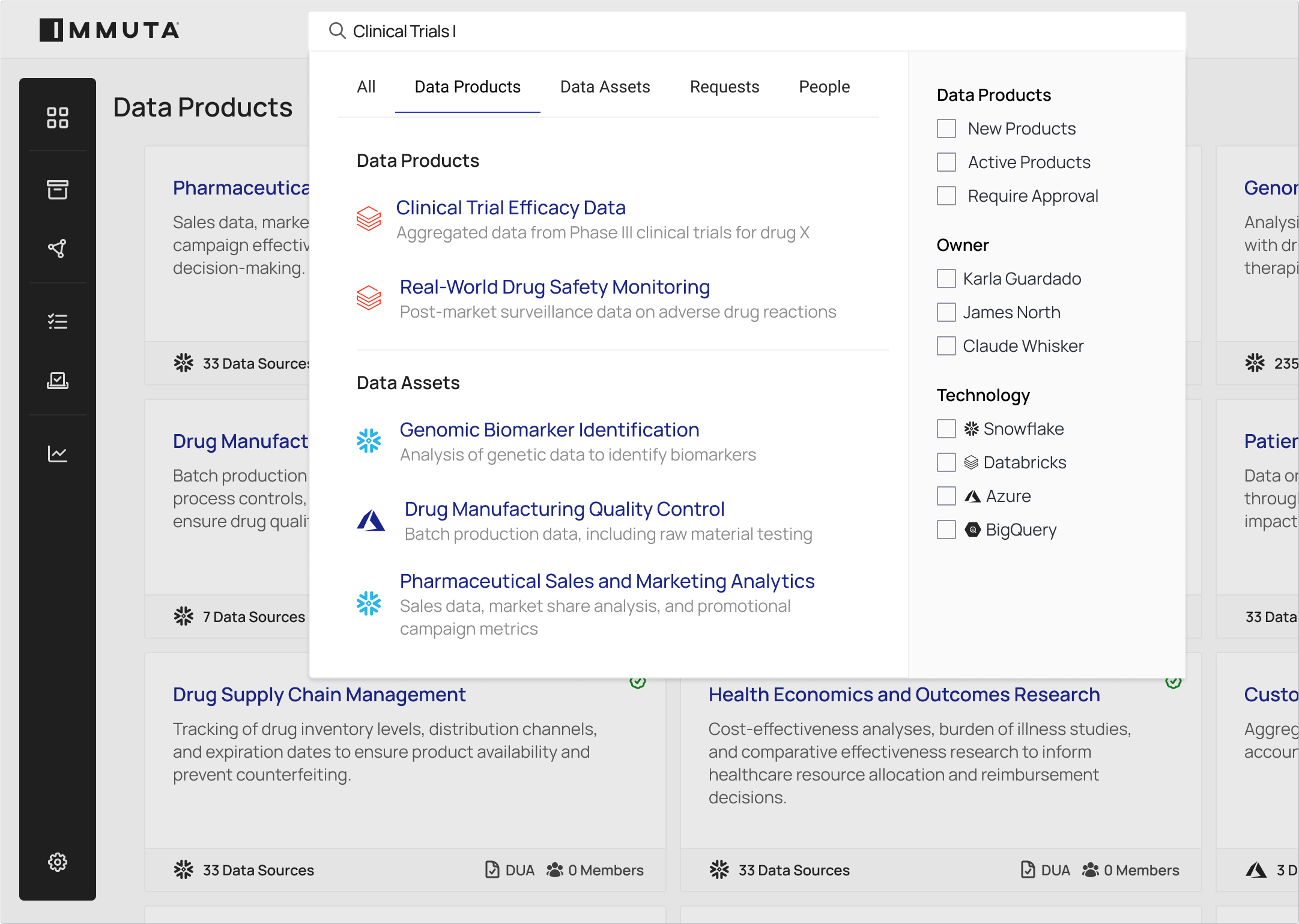
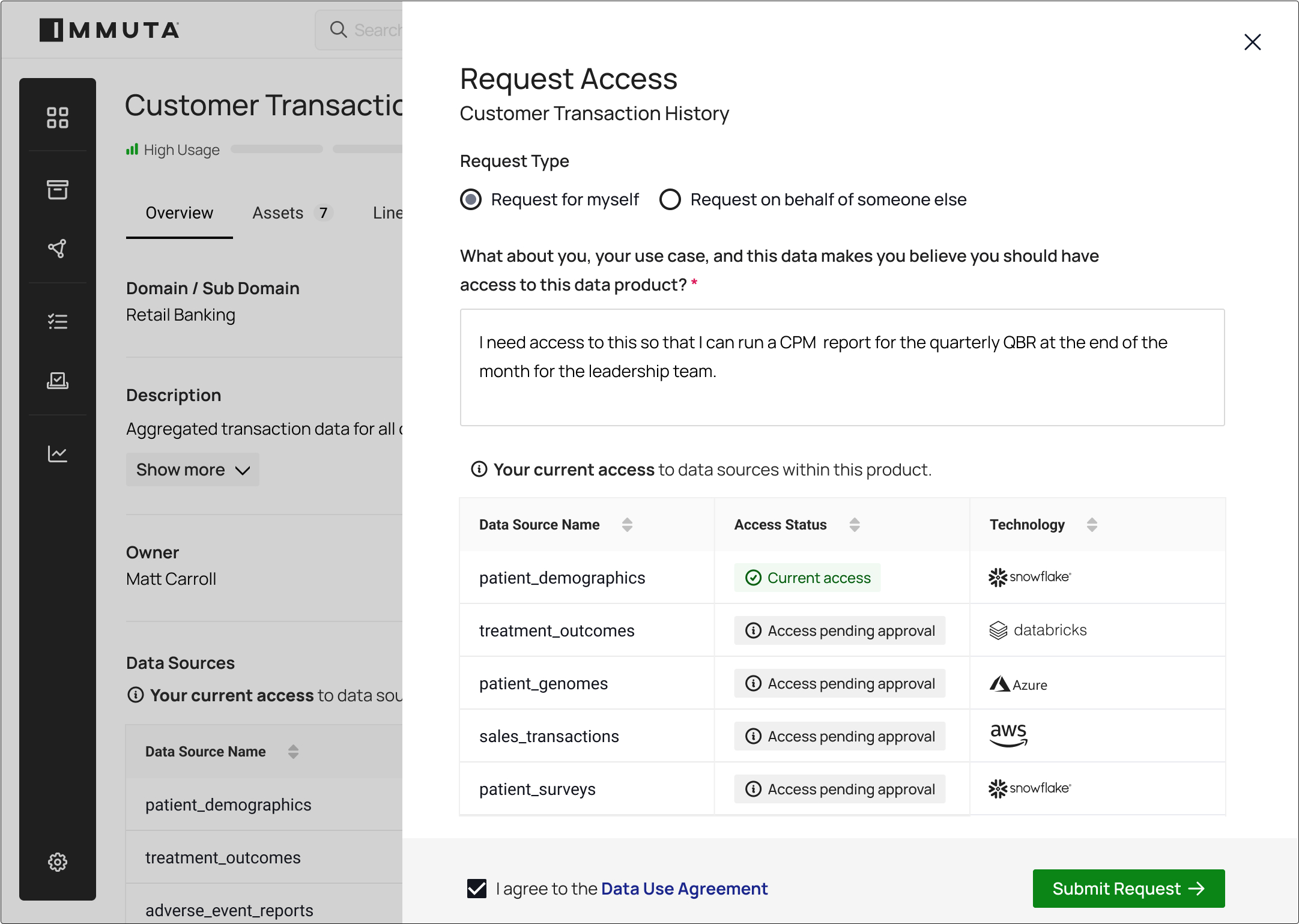
Streamline the approval of data access requests and automatically provision access based on data use agreements. Handle conditional approvals with time-bound access.

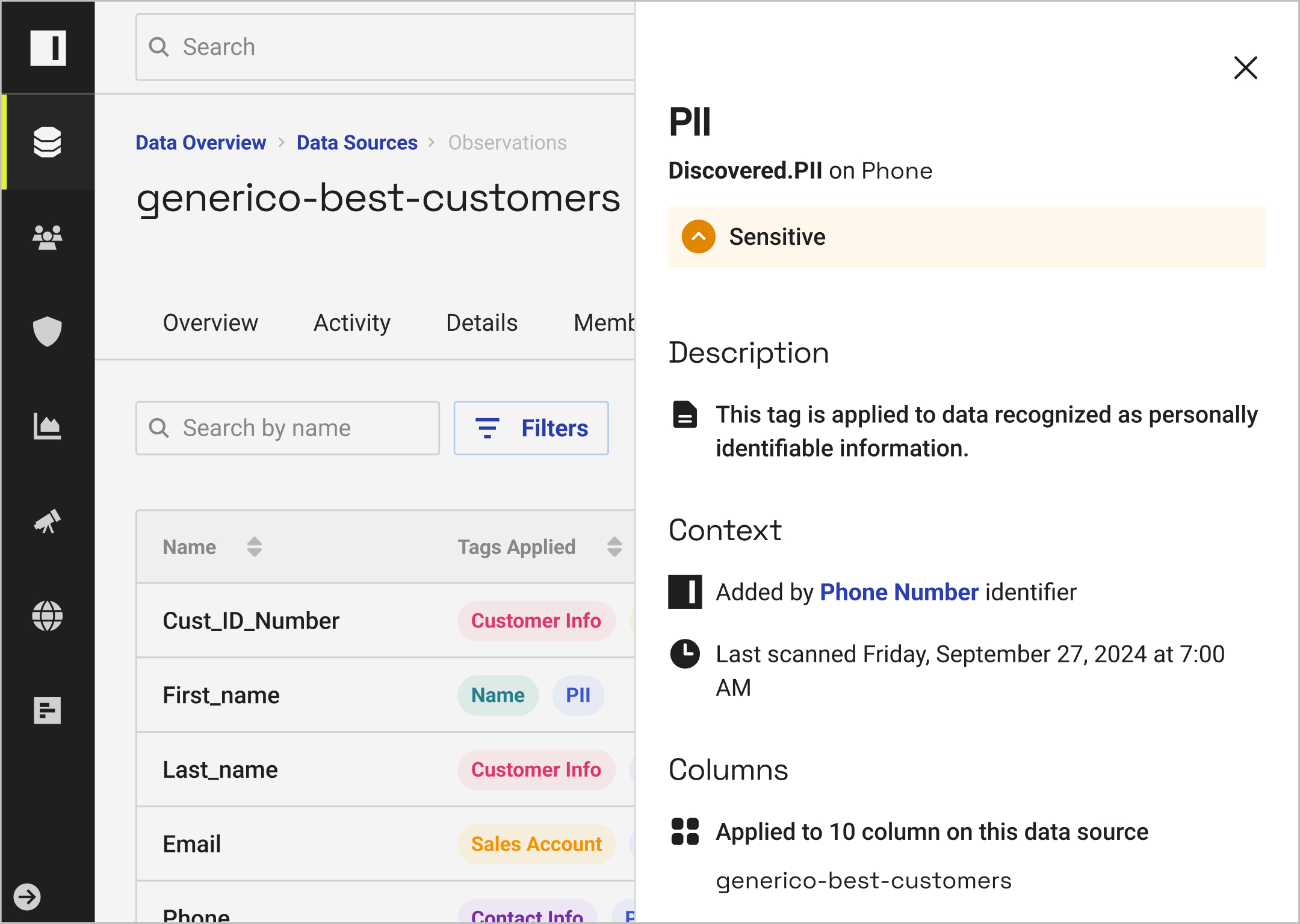
Automatically classify data and data products to drive policy enforcement and search — and manage tag integrations with other catalogs.

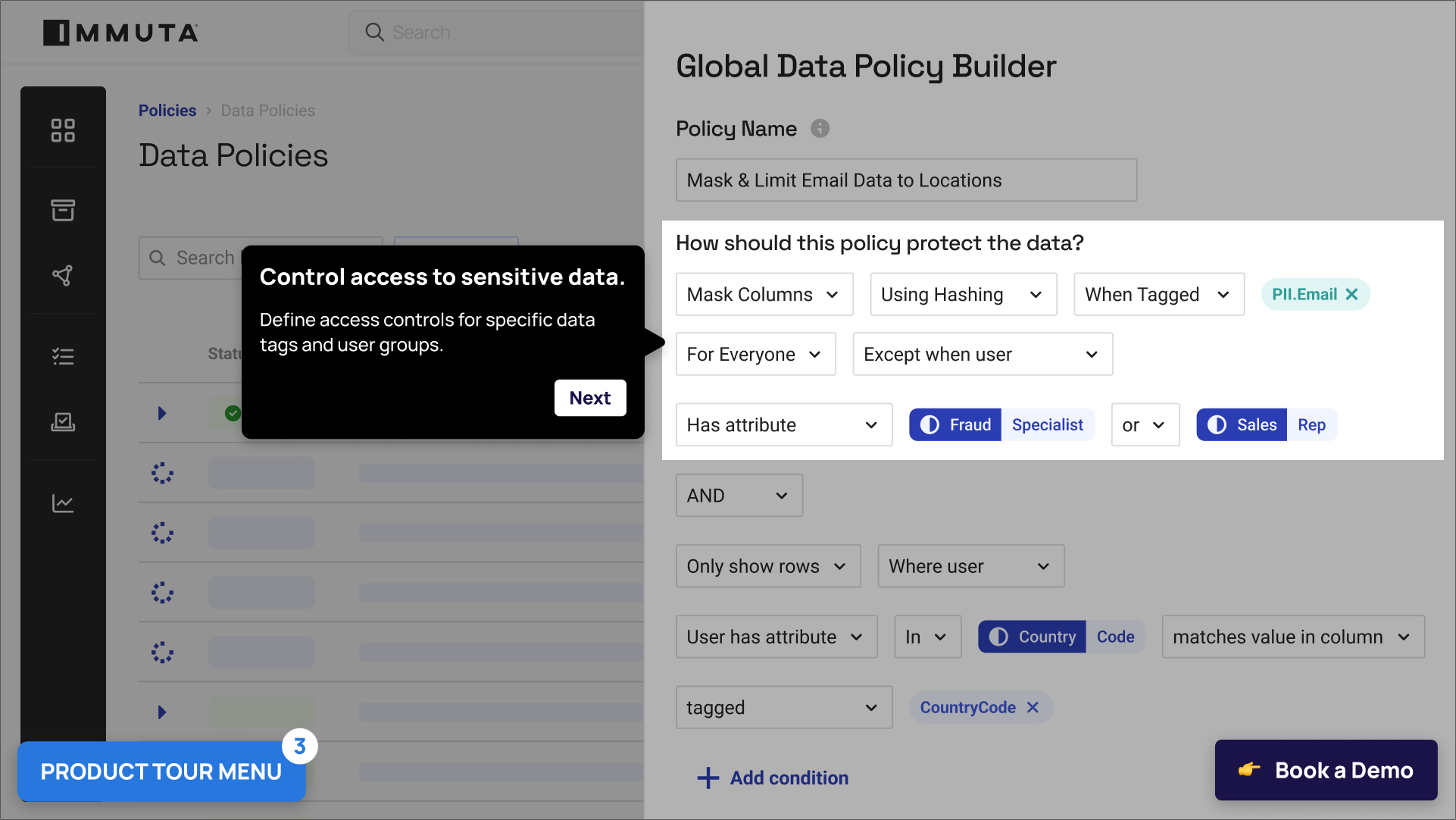
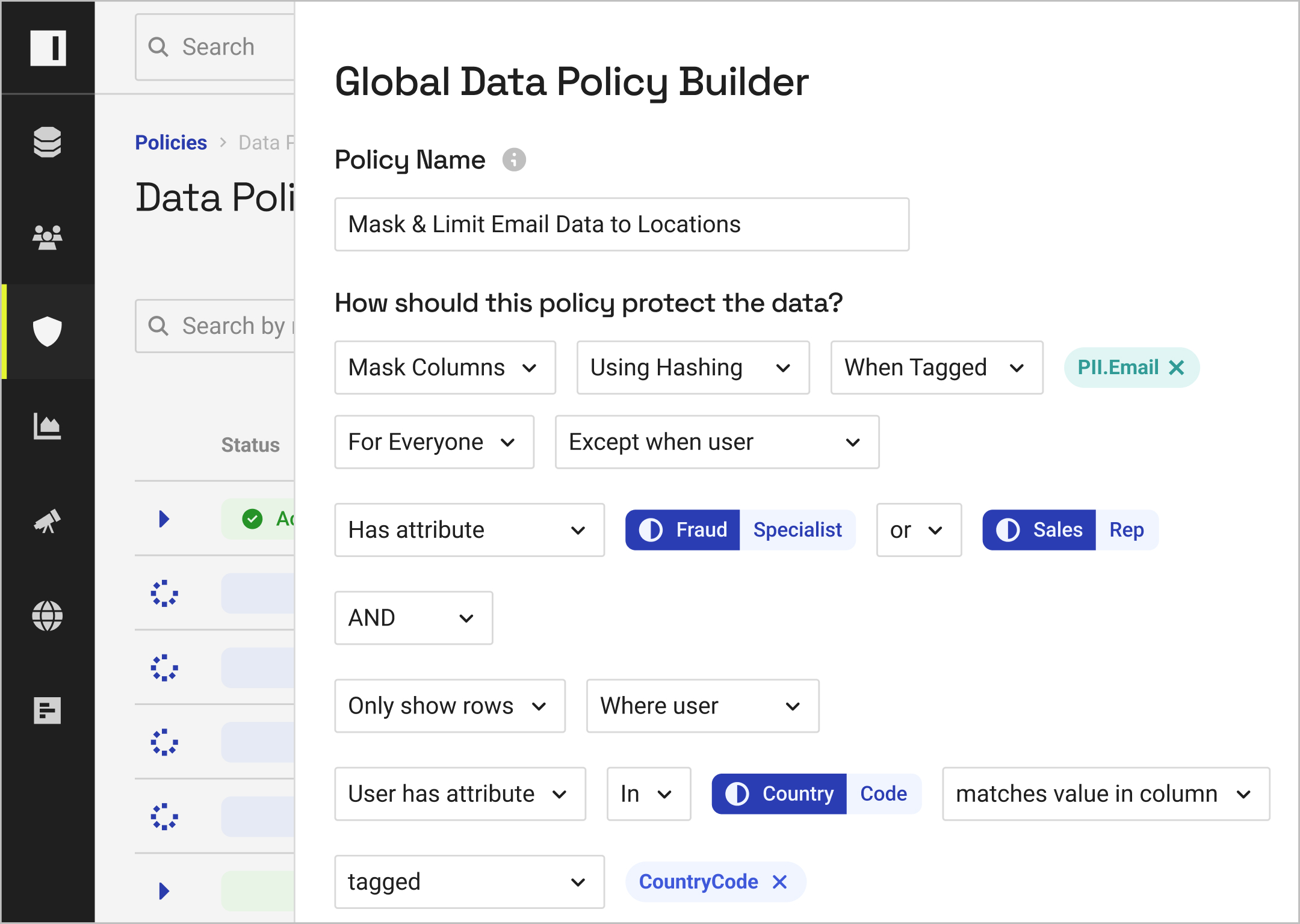
With the ability to test and build cross-platform data access policies in natural language, you can resolve policy bloat and reduce platform-specific efforts.
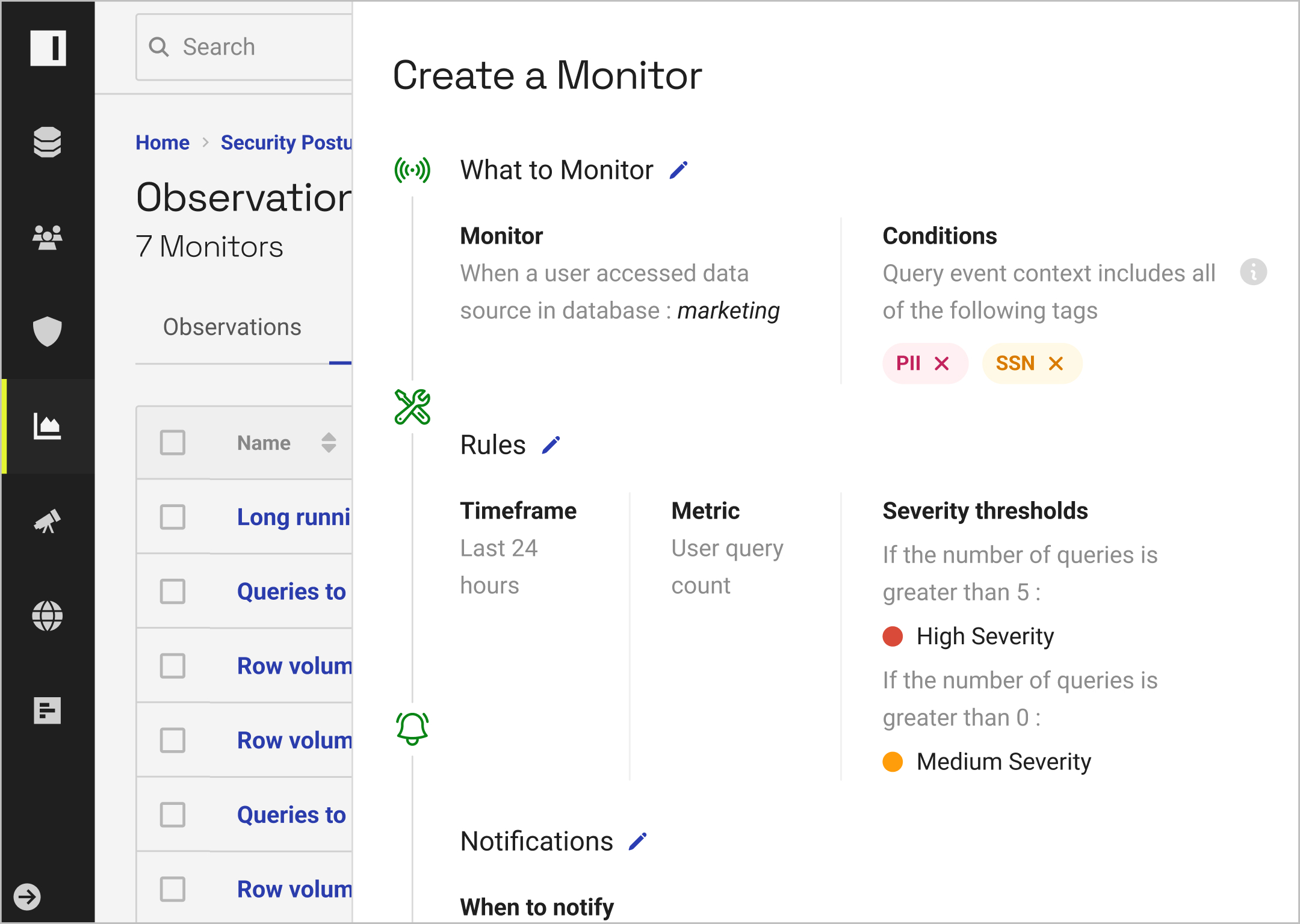
With real-time monitoring and unified reporting, you can understand how data is being accessed at any time.
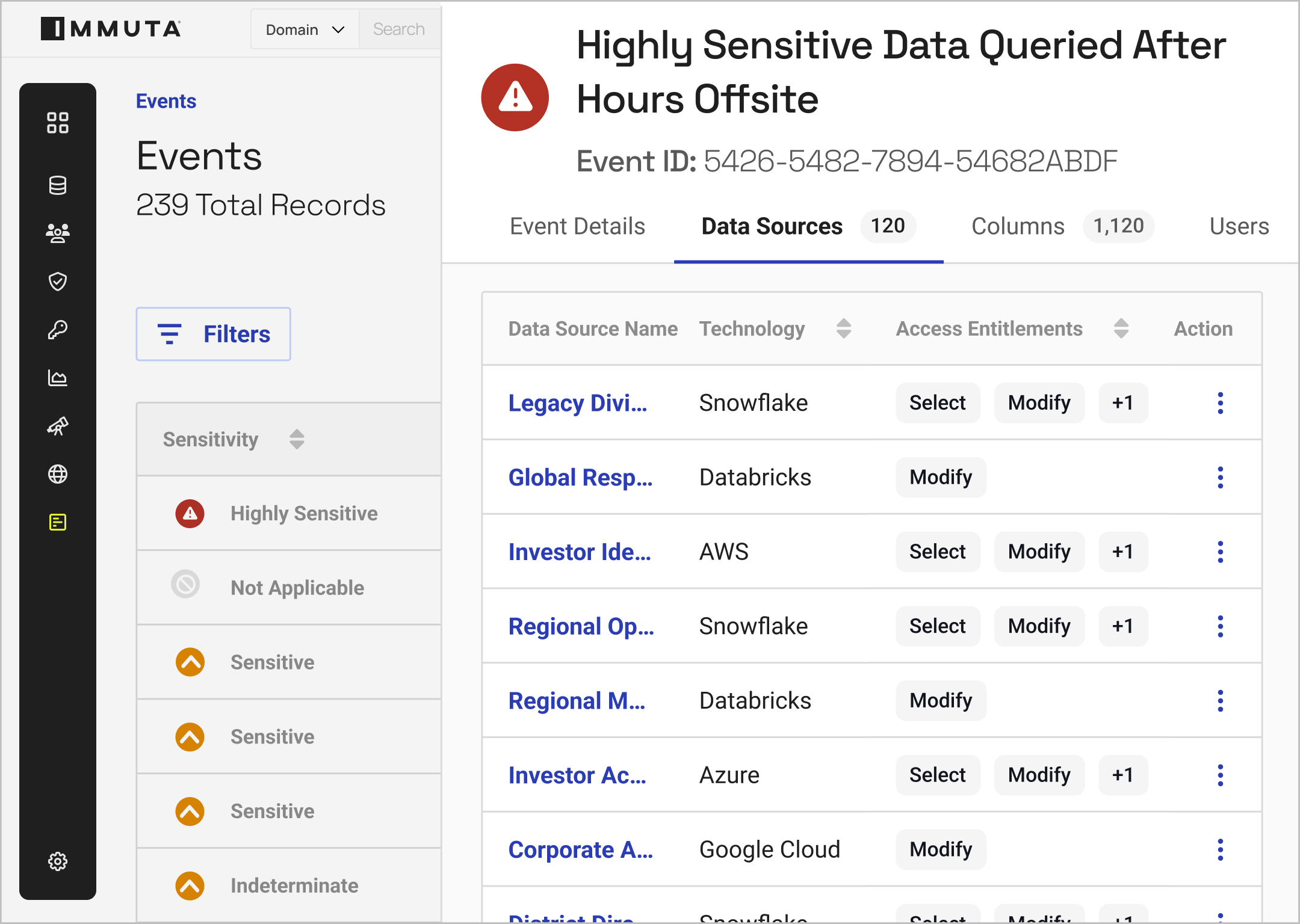

By building reports based on policy outcomes and user activity, you can streamline compliance.


“With the support of Immuta and our other core partners, we have significantly increased our ability to make timely, data-driven decisions, empowering our employees to best respond to the challenges of the global pharmaceutical sector. ”
Pierre Alexandre Fischer, Data Platform Product Line Lead, Rochesaved annually by improving analytics on stock inventory and rotation.
new data products published with more streamlined processes.








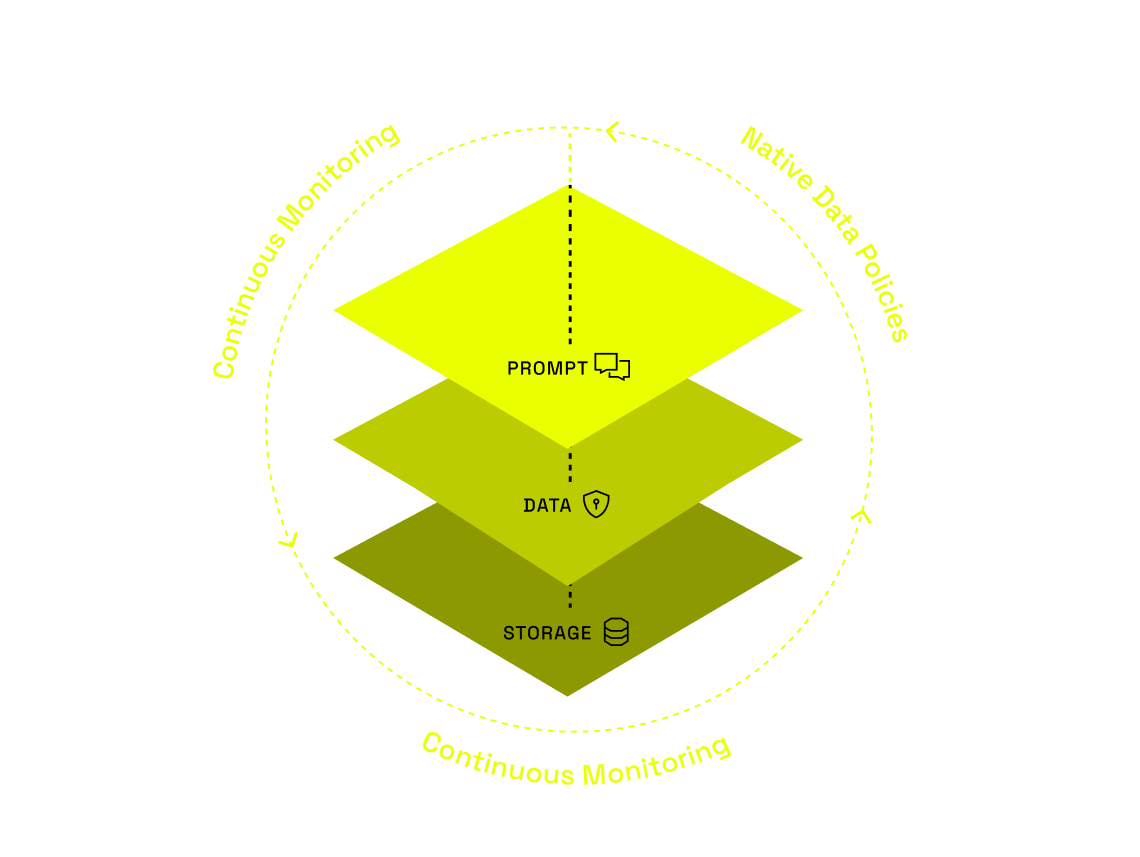
Immuta enforces access controls at the data layer, so you can build and deploy RAG-based GenAI applications quickly, securely, and confidently.