Introduction
Most “AI on your data” demos quietly run the agent under a single service role, which means every user of the agent inherits the same view of the data, and row-level and masking policies go out the window. In this blog I want to show how you can keep fine-grained access control intact through a managed agent runtime, in this case Snowflake’s Cortex Agent, without falling back to a single service role. The pattern has three parts:
- A custom vector table instead of Cortex Search, so row-level policies apply at the data layer itself.
- Immuta on-behalf-of (OBO), so each user session gets a temporary Snowflake role that reflects that user’s permissions, not the agent’s.
- A role-restricted programmatic access token (PAT): the bridge credential that lets the Cortex Agent execute under the vended role.
The problem: RAG is easy until authorization matters
It is easy to build an AI agent that can search documents. Give the agent access to a document index, let it retrieve the top matching chunks, and ask an LLM to write an answer.
That is not enough for enterprise data.
In a real organization, the question is not only:
Can the agent find the right document?
The harder question is:
Is the agent allowed to show this document to this specific human?
That distinction matters a lot for RAG. A retrieval tool is effectively a data access path. If the tool can retrieve every document, then the agent can leak every document, even if the user behind the chat experience should only see a subset.
RAG & Cortex Search – in a nutshell
If you already build RAG systems, skim this section. If you don’t: retrieval-augmented generation is the trick that lets a language model answer questions about documents it has never seen during training. There are three moving parts.
1. Parse documents into clean text
LLMs read text, not PDFs. A scanned file, an email exported as pdf, a picture of a document: none of these are directly readable. Before anything else happens, every document has to be normalized into Markdown.
In Snowflake that’s one function call:
SELECT AI_PARSE_DOCUMENT(
TO_FILE('@PDF_STAGE', 'HARBORLIGHT_2026_02_loss_run_report.pdf'),
OBJECT_CONSTRUCT('mode', 'LAYOUT', 'page_split', TRUE),
TRUE
);
-- returns: { pages: [ { index: 0, content: "# Loss Run Report ..." }, ... ] }
AI_PARSE_DOCUMENT handles extraction, OCR for scanned pages, and layout reconstruction, so a multi-column PDF comes out the other end as well-ordered Markdown with headings, paragraphs, and tables intact. This is the same parser Cortex Search uses under the hood; you’re just calling it yourself so you can decide what happens next.
2. Embed every chunk
Once you have text, you turn each chunk into a fixed-length vector: a list of floating-point numbers, in our case. The crucial property: two pieces of text that mean the same thing produce vectors that point in almost the same direction. We measure that with cosine similarity.
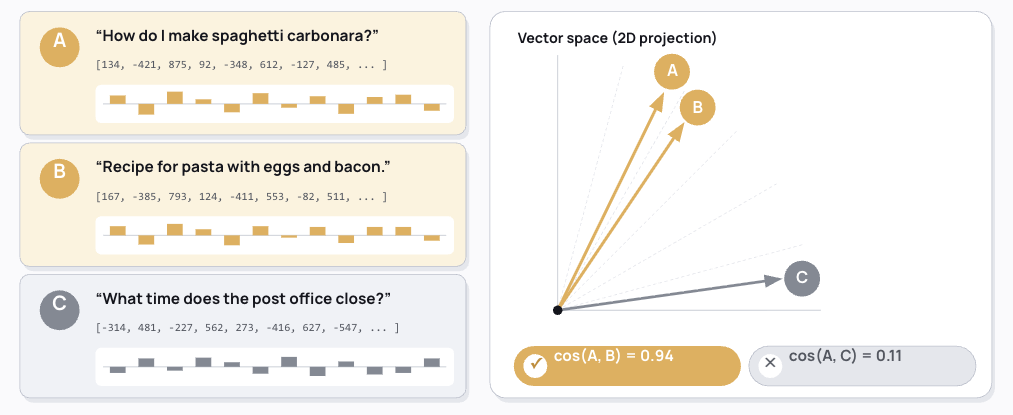
That’s the entire mathematical claim behind semantic search. Embed the text you want to make searchable. In Snowflake you can use the AI_EMBED function. Then embed each new question on the fly, sort by cosine similarity, return the top K results.
3. Let an agent call retrieval as a tool
The last piece is what makes this agentic: the LLM doesn’t pre-load every document. It receives the user’s question, decides retrieval is needed, calls a search function as if it were any other tool, search_docs(...), reads the returned chunks, and writes the final answer grounded in them.
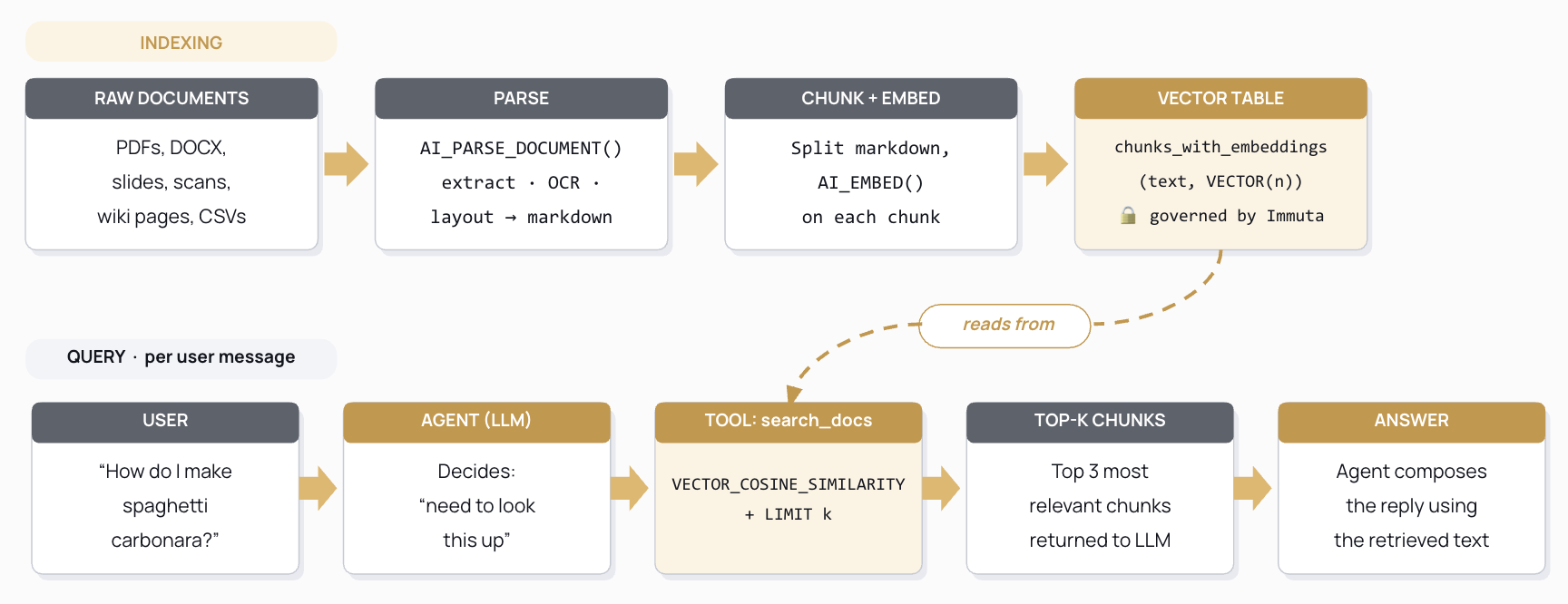
That’s RAG. If you’ve seen Cortex Search, you’ve seen a managed version of all three steps glued together behind one CREATE CORTEX SEARCH SERVICE.
The governance gap in Cortex Search
Cortex Search is a perfectly good retrieval service. It does parsing, chunking, embedding, and indexing in one declarative object. For prototypes, I reach for it first. But it has one property that disqualifies it from the use case I care about:
Access to a Cortex Search service is governed by USAGE on the service, not by row-level policies on the underlying data.
If you can call the service at all, you can retrieve any chunk it indexed. There is no way to say “this user should only see non-sensitive data” without splitting the corpus into multiple physical services and granting USAGE per persona. That isn’t fine-grained access control.
Now let’s take an insurance case as an example. We want to create an agent that can search insurance claim documents, such as broker correspondence, statements of value, FNOL forms, and loss-run reports with paid claim amounts. The same agent should be callable by a customer service employee and a financial analyst, but each role should only see the documents it is allowed to see.
Option A · Managed
Cortex Search
- Fastest path to a working RAG prototype: one
CREATEstatement. - No vector or chunking code to maintain.
- Parsing handles common formats out of the box.
- Governance limitation: access is controlled by
USAGEon the service, not row-level policies. - Fixed extraction pipeline: no VLM, no custom OCR, no special cases.
- Less control: chunk boundaries, embedding model, and metadata columns are managed for you.
Option B · Build it yourself
Custom vector table + UDF
- Governance-aware metadata: add sensitivity, financial, owner, or document-type columns that drive row-level policy.
- Immuta policies apply automatically: the LLM only sees authorized rows.
- Choose your extractor per document type: VLM, custom OCR, layout-aware parsing, or Snowflake-native parsing.
- Decide what gets embedded: full pages, chunks, titles, summaries, or a mix.
- Tradeoff: more upfront engineering. You build it, and you maintain it.
To summarise, move to your own vector table the moment row-level access, custom extraction, or rich metadata starts to matter.
Insurance example in Snowflake
In the following section I will be showing an example on how you can setup your own search tool and RAG agent in Snowflake. The source documents are a synthetic insurance corpus with fictional businesses, policies, and claims.
The documents are example insurance files such as:
- broker submission emails
- loss run reports
- statements of values
- policy schedules
- certificates of currency
- insurance applications
- FNOL forms
- claim reports
Insurance is a useful domain for explaining governed RAG because not every employee should see every document. Some files contain claims history, personal data, or financial information. Other files are routine email correspondence.
The final vector table includes both text and metadata:
| Column | Purpose |
|---|---|
relative_path |
Link back to the staged PDF |
document_type |
Filter by business document type |
insured_business_name |
Business context for answers |
insured_industry |
Additional business context |
insurer_name |
Carrier or underwriter context |
sensitivity_classification |
Human-readable governance label |
contains_financial_data |
Policy input |
contains_claim_data |
Policy input |
contains_person_name |
Policy input |
page_markdown |
Parsed page text |
page_embedding |
Vector used for semantic retrieval |
Example rows:
| relative_path | document_type | insured_business_name | financial? | sensitivity |
|---|---|---|---|---|
| pdfs/HARBORLIGHT_2026_01_broker_submission_email.pdf | broker_submission_email | Harborlight Facilities Group Pty Ltd | FALSE |
INTERNAL |
| pdfs/HARBORLIGHT_2026_02_loss_run_report.pdf | loss_run_report | Harborlight Facilities Group Pty Ltd | TRUE |
RESTRICTED_CLAIMS |
| pdfs/HARBORLIGHT_2026_04_policy_schedule.pdf | policy_schedule | Harborlight Facilities Group Pty Ltd | TRUE |
CONFIDENTIAL_UNDERWRITING |
That metadata is what makes row-level filtering possible. Using those documents, we can set up a pipeline in Snowflake that transforms the documents into a usable vector table with metadata that allows us to set row-level filter policies on it. The full flow then would look as follows:

Five named objects, three of them (dynamic) tables, one of them governed. Let’s walk through each.
Stage and manifest
Documents go into an internal stage. A small manifest table gives every file a deterministic document_id derived from its relative path. That MD5(relative_path) trick is what keeps the rest of the pipeline idempotent.
CREATE OR REPLACE STAGE <Database>.<Schema>.PDF_STAGE
DIRECTORY = (ENABLE = TRUE)
ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE');
CREATE OR REPLACE TABLE <Database>.<Schema>.STAGED_PDFS AS
SELECT
MD5(RELATIVE_PATH) AS document_id,
RELATIVE_PATH AS relative_path,
FILE_URL AS stage_file_url
FROM DIRECTORY(@<Database>.<Schema>.PDF_STAGE)
WHERE LOWER(RELATIVE_PATH) LIKE '%.pdf';What that table looks like for our insurance corpus:
| document_id | relative_path | stage_file_url |
|---|---|---|
| 7d3e94a1… | pdfs/HARBORLIGHT_2026_01_broker_submission_email.pdf | sfc://stage/PDF_STAGE/… |
| e5f6b3c2… | pdfs/HARBORLIGHT_2026_02_loss_run_report.pdf | sfc://stage/PDF_STAGE/… |
| a1b2c3d4… | pdfs/HARBORLIGHT_2026_03_statement_of_values.pdf | sfc://stage/PDF_STAGE/… |
| 9f8e7d6c… | pdfs/NORTHSTAR_2026_01_broker_submission_email.pdf | sfc://stage/PDF_STAGE/… |
| 4c5d6e7f… | pdfs/NORTHSTAR_2026_04_fnol_form.pdf | sfc://stage/PDF_STAGE/… |
Metadata is what makes governance possible
Each document contains metadata that either is derived from the source or could be classified/extracted using AI/ML. In my example I will be using a METADATA table with derived boolean flags that classify each document for governance purposes. Those flags are what row-level policies later filter on.
CREATE OR REPLACE TABLE <Database>.<Schema>.METADATA AS
SELECT
pdf_filename,
document_type,
insured_business_name,
insured_industry,
insurer_name,
-- the governance flags --
IFF(document_type IN ('loss_run_report', 'fnol_form', 'claim_report'),
TRUE, FALSE) AS contains_claim_data,
IFF(COALESCE(annual_revenue, premium, total_declared_value,
total_incurred, total_paid) IS NOT NULL,
TRUE, FALSE) AS contains_financial_data,
CASE
WHEN document_type IN ('loss_run_report', 'fnol_form') THEN 'RESTRICTED_CLAIMS'
WHEN COALESCE(annual_revenue, premium, …) IS NOT NULL THEN 'CONFIDENTIAL_UNDERWRITING'
ELSE 'INTERNAL_SYNTHETIC'
END AS sensitivity_classification
FROM <Database>.<Schema>.RAW_METADATA;And what comes out:
| pdf_filename | document_type | insured_business_name | fin? | claim? | sensitivity |
|---|---|---|---|---|---|
| HARBORLIGHT_2026_01_broker_submission_email.pdf | broker_submission_email | Harborlight Facilities Group | FALSE |
FALSE |
INTERNAL |
| HARBORLIGHT_2026_02_loss_run_report.pdf | loss_run_report | Harborlight Facilities Group | TRUE |
TRUE |
RESTRICTED_CLAIMS |
| HARBORLIGHT_2026_03_statement_of_values.pdf | statement_of_values | Harborlight Facilities Group | TRUE |
FALSE |
CONFIDENTIAL_UNDERWRITING |
| NORTHSTAR_2026_01_broker_submission_email.pdf | broker_submission_email | Northstar Recreation Pty Ltd | FALSE |
FALSE |
INTERNAL |
| NORTHSTAR_2026_04_fnol_form.pdf | fnol_form | Northstar Recreation Pty Ltd | TRUE |
TRUE |
RESTRICTED_CLAIMS |
Notice the structure: every row carries its own policy hints. contains_financial_data is the column we’ll use later to keep loss runs out of the customer service employee’s results.
Parse, embed, and join in two dynamic tables
The first dynamic table parses each PDF into page-level Markdown. The second embeds every page and joins in the metadata. I deliberately kept it page-level instead of chunk-level: it’s easier to explain, it maps cleanly to AI_PARSE_DOCUMENT‘s output, and for short documents one page is the right retrieval unit. Smarter chunking is a production concern, not a tutorial concern.
CREATE OR REPLACE DYNAMIC TABLE <Database>.<Schema>.DT_VECTOR_TABLE
TARGET_LAG = '1 day'
WAREHOUSE = <Warehouse>
REFRESH_MODE = FULL
AS
SELECT
MD5(CONCAT(p.document_id, ':', p.page_index::STRING)) AS vector_row_id,
p.document_id,
p.relative_path,
md.document_type,
md.insured_business_name,
md.insured_industry,
md.insurer_name,
md.sensitivity_classification,
md.contains_claim_data,
md.contains_financial_data,
md.contains_person_name,
p.page_index,
p.page_markdown,
AI_EMBED('snowflake-arctic-embed-l-v2.0', p.page_markdown) AS page_embedding
FROM <Database>.<Schema>.DT_PARSED_DOCUMENT p
LEFT JOIN WIM_DEMO.INSURANCE_DEMO.METADATA md
ON SPLIT_PART(p.relative_path, '/', -1)
IN (md.pdf_filename, md.scanned_pdf_filename);This is the table everything else hangs off. One row per PDF page, original Markdown alongside its embedding, every governance flag inherited from METADATA. This is also the table Immuta will attach row-level policies to.
| vector_row_id | document_type | insured_business_name | page | page_markdown preview | page_embedding | fin? | claim? |
|---|---|---|---|---|---|---|---|
| a3f9… | broker_submission_email | Harborlight Facilities Group | 0 | # Renewal submission · Harborlight Facilities Group Pty Ltd… | [0.124, -0.087, 0.412, …] | FALSE |
FALSE |
| b7c1… | loss_run_report | Harborlight Facilities Group | 0 | # Loss Run Report · Period: 2020-2025 · 4 incidents… | [0.211, 0.103, -0.067, …] | TRUE |
TRUE |
| b7c2… | loss_run_report | Harborlight Facilities Group | 1 | | Date | Description | Paid | Incurred | … 2023-02-28 … | [0.198, 0.142, -0.051, …] | TRUE |
TRUE |
| c4d8… | statement_of_values | Harborlight Facilities Group | 0 | # Statement of Values · Total declared value: USD 3,615,000… | [0.156, -0.034, 0.289, …] | TRUE |
FALSE |
| d2e5… | broker_submission_email | Northstar Recreation Pty Ltd | 0 | # Target inception 02/12/2025 · Atlas Risk Advisors to Meridian Mutual… | [0.087, -0.134, 0.376, …] | FALSE |
FALSE |
| e9f1… | fnol_form | Northstar Recreation Pty Ltd | 0 | # First Notice of Loss · Reporter: M. Vale · Estimated loss: USD 26,750… | [0.223, 0.094, -0.018, …] | TRUE |
TRUE |
Why this matters
Because the embeddings, the page text, and the governance flags all live on the same row, any row-level policy expressed on contains_financial_data or sensitivity_classification automatically filters retrieval. The agent has no special path around the policy; it can only retrieve rows that SELECT * would return for the current session.
Retrieval, as a UDF
With the vector table in place, retrieval is only one SQL query: embed the user’s question, score every row by cosine similarity, sort, take the top K. I wrote it as a table function so it can be used as a tool for my agent. I even added a variable DOCUMENT_TYPE_FILTER that allows my agent to filter on specific document types, making the search capability more complex
CREATE FUNCTION <Database>.<Schema>.SEARCH_INSURANCE_DOCUMENTS(
"QUERY" VARCHAR,
"TOP_K" NUMBER,
"DOCUMENT_TYPE_FILTER" VARCHAR
)
RETURNS TABLE (
relative_path VARCHAR,
document_type VARCHAR,
insured_business_name VARCHAR,
insured_industry VARCHAR,
insurer_name VARCHAR,
page_index NUMBER,
similarity FLOAT,
page_markdown VARCHAR
)
AS
$$
WITH scored AS (
SELECT
relative_path,
document_type,
insured_business_name,
insured_industry,
insurer_name,
page_index,
VECTOR_COSINE_SIMILARITY(
page_embedding,
AI_EMBED('snowflake-arctic-embed-l-v2.0', "QUERY")
) AS similarity,
page_markdown
FROM <Database>.<Schema>.DT_VECTOR_TABLE
WHERE UPPER("DOCUMENT_TYPE_FILTER") = 'ALL'
OR document_type = "DOCUMENT_TYPE_FILTER"
)
SELECT
relative_path,
document_type,
insured_business_name,
insured_industry,
insurer_name,
page_index,
similarity,
page_markdown
FROM scored
QUALIFY ROW_NUMBER() OVER (ORDER BY similarity DESC) <= "TOP_K"
ORDER BY similarity DESC
$$;The FROM DT_VECTOR_TABLE clause runs under the current session’s role, so whatever row-level policy Immuta has attached to that table fires before the cosine similarity is even computed. The agent doesn’t “rank then redact.” It never sees the redacted rows in the first place.
Calling it looks like this:
SQL · calling the UDF
SELECT *
FROM TABLE(WIM_DEMO.INSURANCE_DEMO.SEARCH_INSURANCE_DOCUMENTS(
QUERY => 'claims history for Harborlight Facilities Group',
TOP_K => 5,
DOCUMENT_TYPE_FILTER => 'ALL'
));And the results, ranked by similarity:
Result · search ranked by cosine similarity (executed as a privileged role, no policy applied)
| # | relative_path | document_type | insured_business | page | similarity |
|---|---|---|---|---|---|
| 1 | pdfs/HARBORLIGHT_2026_02_loss_run_report.pdf | loss_run_report | Harborlight Facilities Group | 0 | 0.781 |
| 2 | pdfs/HARBORLIGHT_2026_02_loss_run_report.pdf | loss_run_report | Harborlight Facilities Group | 1 | 0.762 |
| 3 | pdfs/HARBORLIGHT_2026_01_broker_submission_email.pdf | broker_submission_email | Harborlight Facilities Group | 0 | 0.428 |
| 4 | pdfs/HARBORLIGHT_2026_03_statement_of_values.pdf | statement_of_values | Harborlight Facilities Group | 0 | 0.366 |
| 5 | pdfs/NORTHSTAR_2026_04_fnol_form.pdf | fnol_form | Northstar Recreation Pty Ltd | 0 | 0.241 |
The two loss-run pages dominate the ranking. That is exactly what you’d want for that question, and exactly what you don’t want a customer service employee to see. Hold that thought.
Creating the Cortex Agent
The Cortex Agent stays thin: it decides when to search, calls Search_insurance_docs, and writes the answer from the returned document pages. The retrieval logic stays in Snowflake SQL.
The agent tool has three required inputs. When no document filter is needed, the agent passes ALL.
{
"query": "email conversations about claims and renewals",
"top_k": 10,
"document_type_filter": "broker_submission_email"
}
A compact agent specification looks like this:
{
"models": {
"orchestration": "auto"
},
"instructions": {
"orchestration": "You are an insurance support agent. Use Search_insurance_docs to retrieve document pages. Only answer from returned tool results."
},
"tools": [
{
"tool_spec": {
"type": "generic",
"name": "Search_insurance_docs",
"description": "Searches embedded insurance document pages.",
"input_schema": {
"type": "object",
"properties": {
"query": { "type": "string" },
"top_k": { "type": "number" },
"document_type_filter": { "type": "string" }
},
"required": ["query", "top_k", "document_type_filter"]
}
}
}
],
"tool_resources": {
"Search_insurance_docs": {
"type": "function",
"identifier": "<Database>.<Schema>.SEARCH_INSURANCE_DOCUMENTS_AGENT",
"execution_environment": {
"type": "warehouse",
"warehouse": "<Warehouse>"
}
}
}
}Create or replace the agent with that specification:
CREATE OR REPLACE AGENTThe agent receives only the wrapper function as a tool. It does not get direct table access and it does not use Cortex Search. Retrieval always goes through the UDF path reading DT_VECTOR_TABLE, where Immuta policies can filter rows.
The governance problem with agents
Stop and look at what we’ve built. We have a UDF that respects row-level policies. We have an agent tool that wraps that UDF and we have a Cortex Agent that can use that UDF. Good. But how does the agent connect to Snowflake? The default answer is to give the agent a service account, slap a “service-role” role on it, grant that role SELECT on the vector table, and call it a day. The problem with that pattern is straight-line obvious once you see it:
If the agent is always the same role, then every user of the agent gets the same view of the data. Row-level policy is functionally bypassed.
Your customer service employee inherits the financial analyst’s view. Your auditor sees “agent_service_user ran 47,000 queries last week” with no human attached. Every governance investment you made upstream evaporates the moment a model starts driving the queries. The fix is to keep the human as the security anchor and let the agent borrow their context.
That’s exactly what Immuta on-behalf-of is for. The flow:
- The user authenticates to the chat application. Their Immuta user-id is now known to the backend.
- The backend calls Immuta’s OBO endpoint with the agent’s API key and the human’s user-id, asking for a temporary Snowflake role.
- Immuta vends a short-lived Snowflake role that reflects exactly that user’s policy context, including masking and row filtering.
- The backend creates a Snowflake PAT for the service user, restricted to the vended role.
- The backend calls the Cortex Agent over REST, authenticating with that PAT.
- The Cortex Agent executes the search tool as the service user, but under the role-restriction, so every
SELECTis evaluated under the vended role and Immuta’s policies fire.
The middle two steps are the interesting bit. Immuta gives you a temporary Snowflake role; Snowflake gives you a way to bind that role to a credential. The role-restricted PAT is the engineering glue between them.
The role-restricted PAT, in detail
Snowflake PATs support ROLE_RESTRICTION, which specifies the role used for privilege evaluation and object creation. Snowflake also notes that secondary roles are not used for a role-restricted PAT:
https://docs.snowflake.com/en/sql-reference/sql/alter-user-add-programmatic-access-token
The PAT creation SQL looks like this:
ALTER USER IF EXISTS <agent_service_user>
ADD PROGRAMMATIC ACCESS TOKEN <token_name>
ROLE_RESTRICTION = '<vended_role>'
DAYS_TO_EXPIRY = 1
COMMENT = 'Immuta OBO Cortex Agent PAT';
For a service user, Snowflake requires a role restriction by default unless authentication policy settings change that behavior. Snowflake’s PAT documentation also calls out that service users need a network policy to generate or use PATs by default:
https://docs.snowflake.com/en/user-guide/programmatic-access-tokens
That makes the PAT more than just a token. It becomes a short-lived, role-constrained handoff artifact between:
- Immuta as the policy and OBO system
- Snowflake as the data platform
- Cortex Agent as the managed agent runtime
Required Snowflake setup details
These are the practical setup details that mattered.
1. PAT admin privilege
The backend service role needs permission to create PATs for the service user:
CREATE ROLE <pat_admin_role>;
GRANT ROLE <pat_admin_role> TO USER <agent_service_user>;
GRANT MODIFY PROGRAMMATIC AUTHENTICATION METHODS
ON USER <agent_service_user>
TO ROLE <pat_admin_role>;Snowflake documents MODIFY PROGRAMMATIC AUTHENTICATION METHODS as the privilege needed when generating a PAT for another user or service user.
2. Network policy
In order to be able to use the PAT token, we have to set a network policy. For quick validation, a permissive user-level network policy may be enough:
CREATE OR REPLACE NETWORK POLICY <agent_service_user>_ALLOW_ALL
ALLOWED_IP_LIST = ('0.0.0.0/0')
COMMENT = 'Allow-all policy for service-user PAT auth';
ALTER USER <agent_service_user>
SET NETWORK_POLICY = <agent_service_user>_ALLOW_ALL;An allow-all network policy is not a production recommendation. In production, restrict the allowed network ranges.
3. Default role and warehouse
Cortex Agent execution also depended on the service user having:
- a default role
- a default warehouse
- usage on the Agent, database, schema, and function
Calling the Cortex Agent
This is the step that most “OBO for agents” architectures handwave past. The Cortex Agent :run endpoint is an authenticated Snowflake REST call, so it needs a credential. Immuta gives you a temporary role, not a temporary credential. So you build the credential yourself. The OBO request itself is a single POST:
HTTP · Immuta OBO role vending POST
POST https://<tenant>.hosted.immutacloud.com/bim/agent/obo/roles
Authorization: Bearer <AGENT_ACCESS_TOKEN>
Content-Type: application/json
{
"userid": "[email protected]", // the human
"technology": ["snowflake"],
"ttl": "5m"
}This POST is triggered by your agent service or backend, not by Cortex Agent itself. A typical sequence is: the human user logs into your chat application, your backend maps that session to the user’s Immuta identity, and just before calling Snowflake it asks Immuta to vend an OBO role for that specific agent-and-user session.
Note the separation: the agent is identified by the Bearer token, which is the API key for the registered Immuta agent. The human is identified by the userid in the payload. Immuta responds with the name of the freshly vended Snowflake role, for example IMMUTA_OBO_CS_EMPLOYEE_a1b2c3. That role is the value you carry into Snowflake as the PAT ROLE_RESTRICTION. The role has already been granted to your agent service user and already represents the policy context Immuta calculated for that human and that agent.
SQL · creating the role-restricted PAT
ALTER USER agent_service_user
ADD PROGRAMMATIC ACCESS TOKEN alice_session_token
ROLE_RESTRICTION = 'IMMUTA_OBO_CS_EMPLOYEE_a1b2c3'
DAYS_TO_EXPIRY = 1
COMMENT = 'Immuta OBO session for alice.cs';
-- secret is returned exactly once in the result set; capture it now or never.That single SQL statement is the heart of the pattern. Three properties make it work:
- For service users,
ROLE_RESTRICTIONis required unless Snowflake authentication policy settings change that default. That makes it much harder to accidentally create an unrestricted PAT. - Privilege evaluation happens under the restricted role only. Secondary roles are not used, so there is no fallback to a broader role.
- The role must already have been granted to the service user. The PAT does not elevate privilege; it scopes the service user down to the vended role.
Then call the agent:
HTTP · calling Cortex Agent with the PAT
POST https://<account>.snowflakecomputing.com/api/v2/cortex/agent:run
Authorization: Bearer <pat_secret>
Content-Type: application/json
{
"agent": "<Database>.<Schema>.INSURANCE_AGENT",
"messages": [{ "role": "user", "content": "Summarize Harborlight's claims history." }]
}The agent runs under agent_service_user, but every SELECT it issues, including the one inside our search UDF, is evaluated as if the session were IMMUTA_OBO_CS_EMPLOYEE_a1b2c3. Immuta’s row-level filter fires before cosine similarity is even computed.
One honest caveat. This is a pragmatic composition, not a “pure” OBO flow. The direct Snowflake connector OBO pattern is simpler and more canonical. The PAT-based pattern earns its keep when you want to keep the managed Cortex Agent runtime, including streaming SSE, tool orchestration, and citations, while still respecting per-user policy.
The Insurance Agent Example
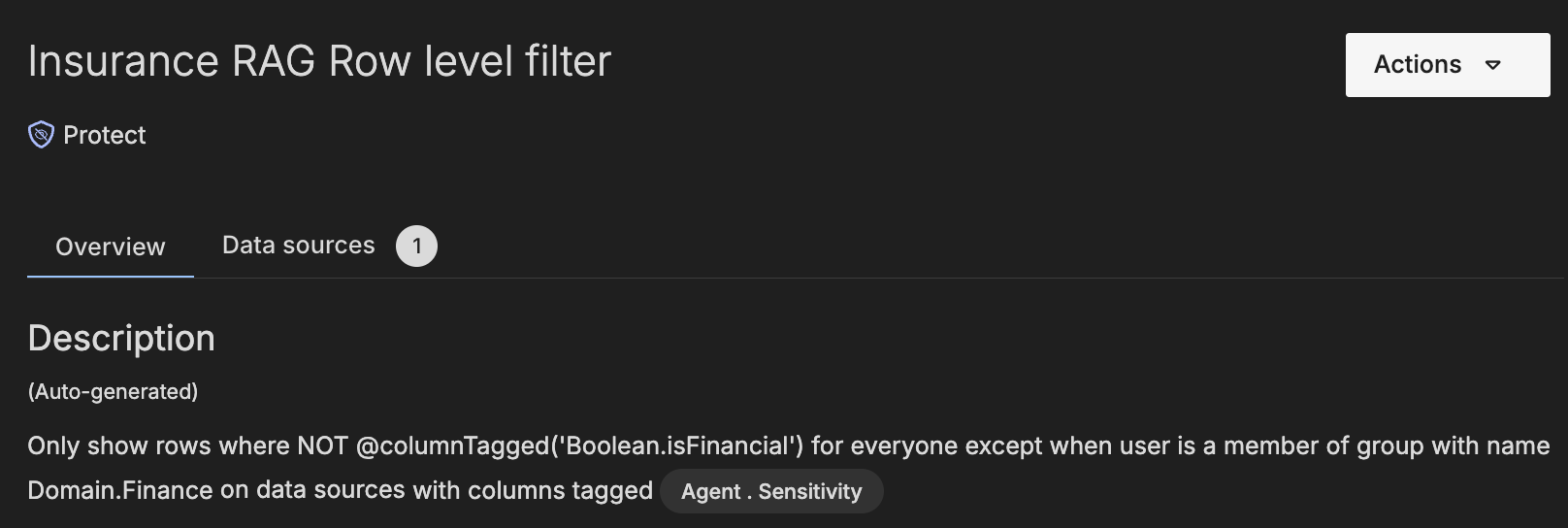
Time to close the loop. Imagine a row-level policy attached to DT_VECTOR_TABLE in Immuta that says, in plain English:
“If the current role is not in the finance group, only return rows where contains_financial_data = FALSE.“
That single policy is the whole game. Now, when Bob (a customer service employee) and Ben (a financial analyst) each ask the agent the same question, the OBO flow vends a different role for each, the PAT scopes the agent’s session accordingly, and the UDF returns a different result set per session before the LLM has written a single word.
Bob · Customer Service Employee
Customer Service · restricted
- Vended role: IMMUTA_OBO_CS_EMPLOYEE_a1b2c3
- Active policy: Hide rows where contains_financial_data = TRUE
- Question: “Summarize Harborlight’s claims history.”
- Found only non financial documents
Agent answer
“Based on the available documentation, here’s a summary of Harborlight Facilities Group Pty Ltd’s claims history:
Harborlight Facilities Group Pty Ltd (a facilities maintenance company based in Geelong, VIC) has 4 reported claims over the last 5 policy years, as noted in their broker submission for renewal effective 01/07/2026.
Unfortunately, I’m unable to access the detailed loss run report or individual claim reports that would provide specifics on claim types, amounts, and outcomes. The submission references these as attachments, but I cannot retrieve them.
In summary, with 4 claims over 5 years for a business that has been operating for 18 years across 3 locations, the claims frequency appears moderate. If you need more detailed information on individual claim amounts or circumstances, I’d recommend requesting the loss run report directly.”
Ben · Financial Analyst
Financial Analyst · authorised
- Vended role: IMMUTA_OBO_FIN_ANALYST_d4e5f6
- Active policy: No restriction on financial or claim columns
- Question: “Summarize Harborlight’s claims history.”
Found financial documents
Agent answer
“Here’s a short summary of Harborlight Facilities Group Pty Ltd’s claims history:
Harborlight Facilities Group (a facilities maintenance company based in Geelong, VIC) has 4 claims on record spanning 2021 to 2024, with a total incurred cost of USD $142,985:
| Claim No. | Loss Date | Category | Status | Incurred |
|---|---|---|---|---|
| HFG-2021-18420 | 17/11/2021 | Water Damage | Closed | $18,920 |
| HFG-2022-50918 | 14/06/2022 | Equipment Damage | Closed | $34,775 |
| HFG-2023-73104 | 28/02/2023 | Public Liability | Closed | $61,430 |
| HFG-2024-26651 | 19/10/2024 | Storm Damage | Open | $27,860 |
Key observations:
- Three of the four claims are closed with no outstanding reserves.
- The largest single loss was a public liability incident in February 2023 (USD $61,430), which was investigated and subsequently closed.
- One claim remains open: storm damage from October 2024 (USD $27,860).
- The claim frequency is roughly one per year over the four-year period.”
What just happened, mechanically:
Inside the UDF · rows considered for ranking, by session
| Vector row | Document type | Page | Financial? | Claims? | Bob Customer Service |
Ben Financial Analyst |
|---|---|---|---|---|---|---|
| a3f9… | broker_submission_email | 0 | FALSE |
FALSE |
Visible | Visible |
| a3fa… | broker_submission_email | 1 | FALSE |
FALSE |
Visible | Visible |
| b7c1… | loss_run_report | 0 | TRUE |
TRUE |
Filtered | Visible |
| b7c2… | loss_run_report | 1 | TRUE |
TRUE |
Filtered | Visible |
| c4d8… | statement_of_values | 0 | TRUE |
FALSE |
Filtered | Visible |
| e9f1… | fnol_form | 0 | TRUE |
TRUE |
Filtered | Visible |
The agent didn’t refuse to tell Bob about the loss run. It never saw it. The cosine similarity computation in his session was performed over three rows, not six. His top-K was bounded by what his role could see; his LLM context was bounded by his top-K; his answer was bounded by his LLM context. Policy enforced at the data layer, propagated all the way to the response, with the managed Cortex Agent runtime sitting in the middle.
What I’d be honest about
Three things I’d want you to take away as caveats.
1 · You don’t always need a PAT token
A PAT is not a requirement of Immuta OBO itself. If you own the agent runtime, you can also connect to Snowflake directly with a Snowflake connector and service-principal or service-user credentials, then make sure the session uses the ephemeral role that Immuta vended for the human user. In that architecture you are not authenticating to Snowflake’s REST API, so you do not need a PAT.
The PAT becomes useful in this demo because I call the Cortex Agent over Snowflake’s REST API. That API needs a bearer credential, and a role-restricted PAT is a clean way to bind that credential to exactly one vended role. In return for the extra setup, you keep the managed Cortex Agent runtime, including streaming responses, tool orchestration, and citations.
2 · It works with any agent
It doesn’t matter whether your agent runs in Cortex, OpenAI, Azure, AWS, or locally. The idea behind this blog was to show how you can build a search tool for your agent that is governed by Immuta. You can give this tool to any agent, as long as the call path preserves Immuta’s OBO context and the SQL executes under the vended role. That is what makes sure the agent only uses the documents it is allowed to see.
3 · Auditability is essential
In some scenarios, we could also pass the user’s credentials directly into our connector and call the SEARCH_INSURANCE_DOCUMENTS function. The problem is auditability: it becomes harder to distinguish data accessed by the user directly from data accessed by an agent acting for that user. With Immuta’s on-behalf-of feature, Immuta can link the vended role back to the human user and the registered agent. That lets us distinguish between the user and the agent acting on behalf of that user. It also lets us define guardrail policies on agents, so the agent itself has a governed access envelope.
The takeaway
The interesting thing isn’t that an AI agent can answer questions over insurance documents. The interesting thing is preserving a governed, user-specific data access context all the way through a managed agent runtime. The exact setup depends on the use case, but this pattern shows one practical way to set up a governed RAG agent in Snowflake.