
Unity Catalog gives you the primitives to enforce access. It doesn’t give you the system to manage access — at scale, across platforms, for humans and agents. That gap is the case for Immuta. Here it is, in detail.
Let’s be precise about what Unity Catalog already does, because it’s a lot. It enforces table-, row-, and column-level access natively — grants on securables, row filters, and column masks expressed as SQL functions and applied right where your data lives. It carries tags and lineage. It logs activity to system tables. If you’re enforcing a handful of rules on a handful of tables, you may not need anything else.
The trouble starts at scale. The hard problem in data access was never enforcing one rule on one table — it’s managing thousands of rules, across thousands of datasets, tens of thousands of users, dozens of regulations, and now a fast-growing population of AI agents — and keeping all of it correct as data, people, and purposes change. That is not a control you switch on. It’s an operating system for authorization: who gets what data, for what reason, for how long, who approved it, and how you prove it afterward.
Unity Catalog gives you the enforcement primitives. It does not give you that operating system. This post walks through, concretely, where the native line is — and what Immuta does past it. We’ll stay fair to Databricks: the point is not that Unity Catalog is missing features, it’s that policy management, request workflow, purpose, cross-platform consistency, agent coordination, and attributed audit are a different layer of the stack. That layer is the authorization layer, and it’s what Immuta is.
The layer Databricks didn't have to build
Immuta is the authorization layer
Think of Immuta as the coordination point that sits between every requester and your data. A human analyst, a data scientist, a BI tool, a Genie Space, a third-party agent like Claude, ChatGPT, or Glean — they all want data that lives in Databricks. Immuta is the layer that decides, in real time, what each of them is allowed to see, and then makes Databricks enforce it natively.
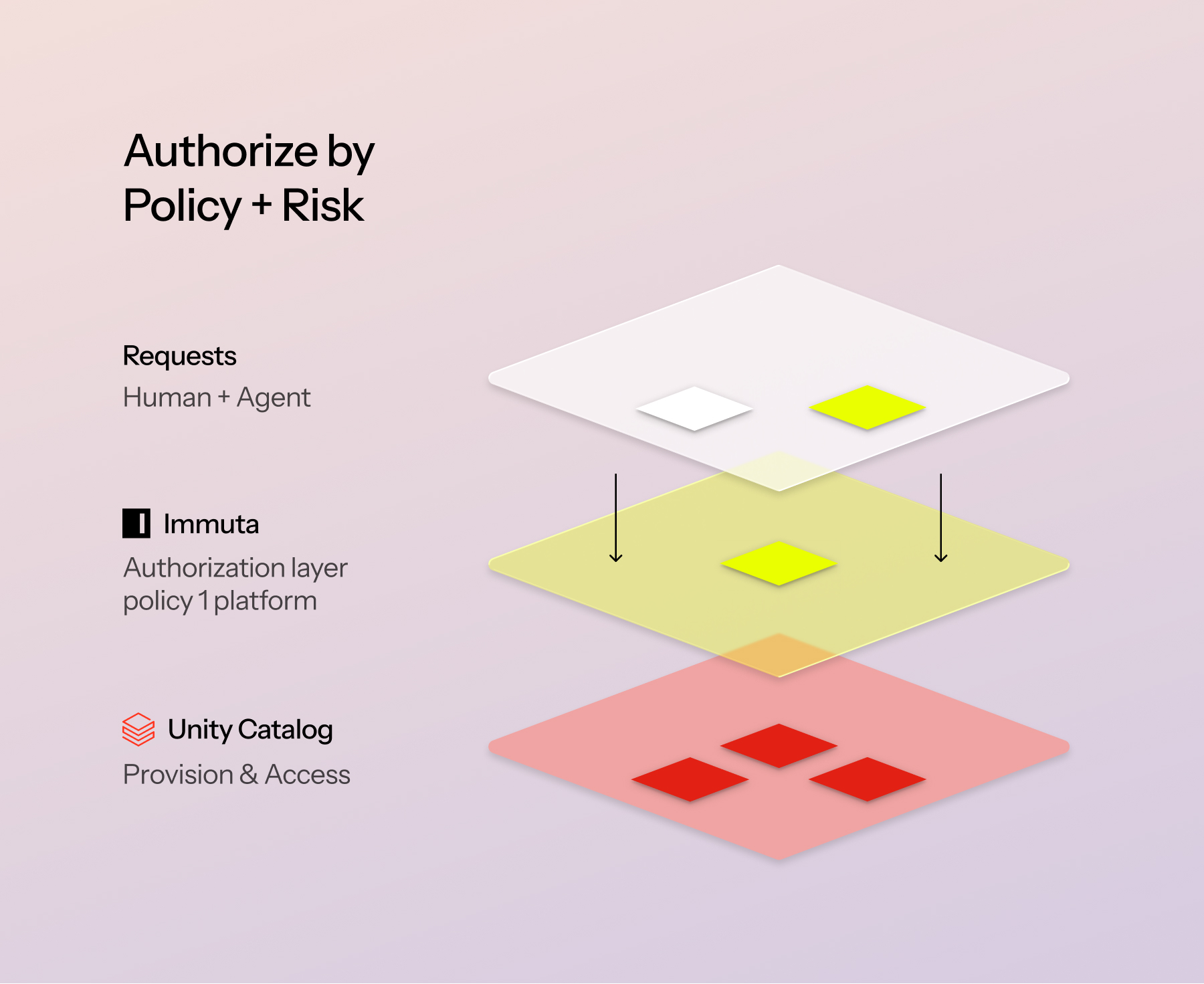
Immuta sits between every requester and your data — abstracting policy from platform, authorizing by policy and risk.
The phrase that matters there is policy abstracted from platform. Databricks is where your data lives and where enforcement happens. Immuta is where policy is decided — independently of any one platform’s syntax, and consistently across every platform you run. That separation is what makes the rest of this story possible.
Authentication got solved. Authorization didn't.
Where Immuta fits — and where Databricks sits in it
Most enterprises have spent a decade investing in authentication: SSO, MFA, identity providers, directories. That answers who are you? — and it’s essential. But it doesn’t answer the question that actually governs risk: what should this human or agent be allowed to do, with this data, for this purpose, right now? That’s authorization, and until recently it lived in fragments — roles here, tickets there, scripts, review meetings, and per-platform SQL. Immuta turns it into a single control plane.
Here’s the architecture — and the part that matters most to a Databricks customer: Immuta doesn’t sit in front of Databricks intercepting traffic. It pushes policy down into Unity Catalog’s native enforcement. Databricks stays the enforcement plane and runs at full speed; the authorization layer sits above it, makes the decision, and lets the platform do what it does best.

One policy engine separates policy from platform, then enforces natively — into Databricks first, and across every other place data lives.
Two things to take from that picture. First, the four capabilities running down the middle — policy authoring and enforcement, request workflows, just-in-time agentic access, and Comply — aren’t separate products. Together they are the authorization layer, and the rest of this post is a tour of each one as it lands on Databricks. Second, Databricks is highlighted because it’s the focus here, but it’s one enforcement target among several: the same engine pushes the same policy into your other data platforms, cloud storage, APIs, and SaaS. Which means the access rules you write for Databricks aren’t a silo. If Databricks is your whole world today, that’s future-proofing; if it isn’t, it’s a consistency you simply cannot get from any one platform’s native controls.
What Unity Catalog does — and the line where it stops
Native enforcement vs. the authorization layer
First, the scope. Unity Catalog is the unified governance layer built into Databricks, and it spans far more than this post covers — discovery and Catalog Explorer, data lineage, data classification, quality monitoring, data sharing, and AI governance, alongside access control. It’s a lot, and most of it is excellent. This post is deliberately narrow: we’re looking only at access, request, and audit — the three places where, at enterprise scale, teams reach for an authorization layer on top. Everything else Unity Catalog does stands on its own.
Databricks also keeps adding native capability — attribute-based access controls among them — so treat what follows as a snapshot of the architecture, not a list of features that will never change. The durable distinction is operational: within access, request, and audit, Unity Catalog is the catalog and the enforcement engine; Immuta is the system that authors, coordinates, and proves policy on top of it.
| Capability | Unity Catalog, natively what you get in the box | With Immuta the authorization layer |
|---|---|---|
| Policy model | Grants on securables, plus row filters and column masks written as SQL functions and attached per object. Attribute-based controls are emerging but are still authored and maintained per securable. | Attribute- and tag-based policy authored once in plain language and applied dynamically to every matching dataset — current and future. |
| Who authors it | Platform engineers writing and maintaining SQL and grants. | Governance leads, stewards, and domain owners — no SQL, no code. |
| Behavior at scale | Roles, grants, and per-object functions multiply with every table, user, and edge case — the classic role-explosion problem — and humans maintain them as things change. | One policy spans thousands of tables and stays in sync automatically as data, users, and attributes change. No role explosion. |
| Purpose / intent-based access | No native concept of access scoped to a declared purpose. | Access granted on the basis of why data is needed — the same mechanism that justifies an agent’s request. |
| Access requests & approvals | Not a native capability — handled by tickets or a system you build and maintain yourself. | Self-service requests inside the catalog, policy-driven approval routing, and time-bound grants. |
| Exceptions (unmask a column, see unfiltered rows) | An administrator manually edits the policy. | A governed, time-bound exception request with full audit — no standing change to the policy. |
| Across other platforms | Governs Databricks. | One policy definition enforced natively across Databricks, Snowflake, and more. |
| AI agents | Service principals and tokens — a standing identity with standing access. | Per-agent identity, just-in-time session-bound access that inherits the human’s entitlements, with dual-identity audit. |
| Audit & attribution | Raw system tables you query and assemble yourself. | Policy-aware, attributed audit — which agent, on behalf of which human — with a conversational interface. |
Read top to bottom, the pattern is consistent: the left column is enforcement and storage; the right column is management, workflow, and proof. The rest of this post takes the rows that matter most and shows the mechanics.
Anyone can author policy — no SQL, no code
Policy-based access control
The first thing the authorization layer has to do well is let the right people write the rules. Not just engineers — the governance leads, data stewards, and domain owners who actually understand the data and the regulations around it.
With Immuta, they author policy in plain language, no SQL and no scripts:
- Subscription policies decide who can use a table or dataset in the first place.
- Data policies mask columns and filter rows so the same table shows different things to different people.
- Intent- and purpose-based policies grant access based on why the data is needed — the justification an analyst, or an agent, provides for the work at hand.
Because those policies are written against Unity Catalog tags and metadata rather than against individual tables, one rule can cover thousands of datasets — and keep covering new ones the moment they appear. And because Immuta holds the full context on every user and every dataset, the policies stay simple instead of multiplying into the thousands of brittle roles that role-based systems collapse under. Then Immuta integrates with Unity Catalog’s own services to push that enforcement through Databricks’ native primitives, so queries run at full platform speed.
Why you can’t just do this natively
Native row filters and column masks are SQL functions attached to objects, and access is a grant to a principal or group. That model works beautifully for one table. Across a real estate it produces the failure mode every platform team knows: a new column, a new region, a new contractor class, a new regulation — each spawns more functions, more groups, more grants to write and reconcile by hand. The math is unforgiving: roles grow with the product of users, data, and exceptions. ABAC inverts that — one attribute-based rule covers every case that matches — but only if something holds the user and data context and orchestrates the native primitives for you. That orchestration layer is the product. It isn’t a setting you enable in the catalog.
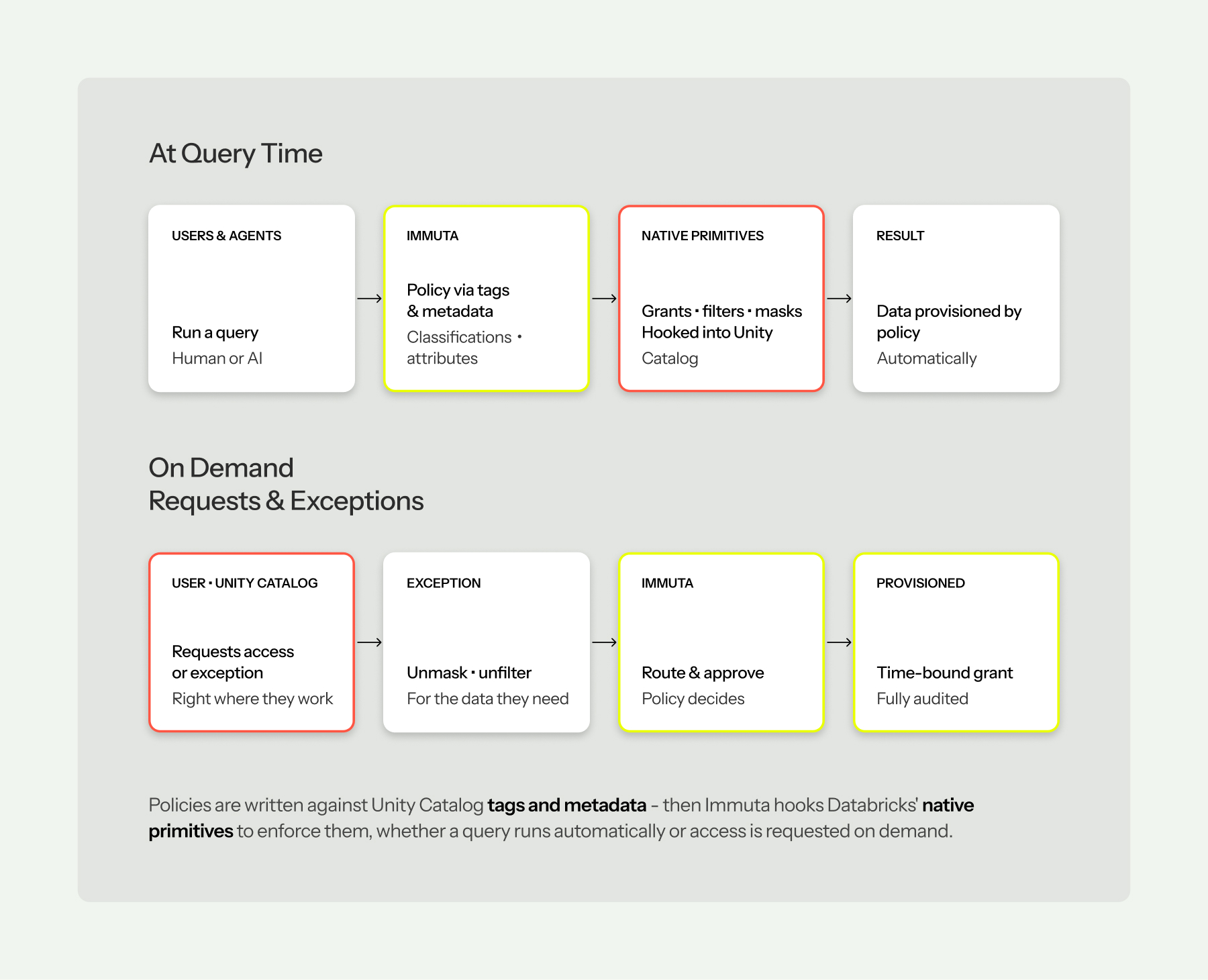
One policy model, two motions: automatic enforcement at query time, and self-service when someone needs more.
Access on demand, without the ticket queue
Data request workflows & exceptions
Standing policy answers most access questions automatically. But people always need data they don’t yet have — and the traditional answer is a support ticket, an email thread, and a three-week wait.
Immuta puts the request right where people work, inside Unity Catalog. A user finds a dataset, requests access on the spot, and policy decides: birthright entitlements grant day-one access, subscription policies auto-approve what they can, and anything that needs a human goes through a governed approval workflow. Crucially, requests go beyond table access — a user can request a policy exception, like unmasking a specific column or seeing unfiltered rows for a defined purpose, and receive a time-bound grant that expires on its own. Every request, approval, and expiration is recorded.
Agents are your fastest-growing data consumers
Just-in-time agentic data access
Here’s the shift that’s making authorization urgent. Your people are already pointing Claude, ChatGPT, and Glean at your data, and Databricks’ own Genie Spaces are bringing natural-language analytics to everyone. Agents are about to become the highest-volume consumers of enterprise data — and the old playbook of handing a bot a shared service account is a security disaster waiting to happen.
Immuta treats agents as first-class, governable participants. Every agent gets its own identity — no borrowed human logins. When an agent acts on behalf of a person, Immuta makes a real-time decision: if the human is entitled, it grants just-in-time, session-bound access scoped to that person’s policy; if not, it routes a data-access request through the same workflow your people use. And because Immuta sits at the authorization layer, every action is captured in a dual-identity audit trail — you can always see exactly which agent acted on behalf of which human.
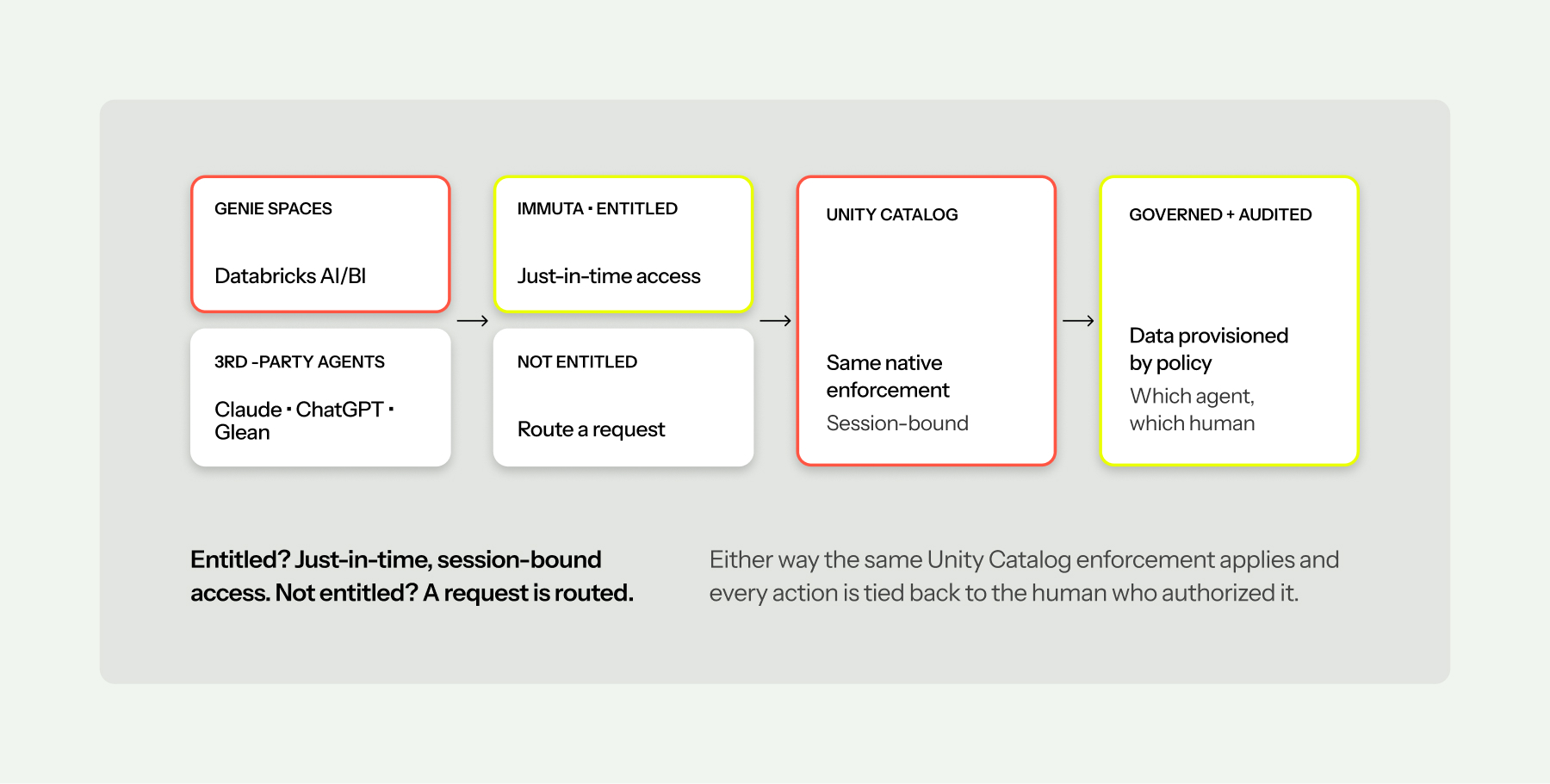
Genie Spaces or third-party agents — every AI consumer lands on the same authorization layer. One policy model, not two.
This is the heart of why the partnership matters right now. Enforcement at the data tier is deterministic — a prompt-injection attack can talk an agent into asking for anything, but it can’t talk Immuta’s policy into granting it. The model can be creative; the authorization can’t be fooled.
Why you can’t just do this natively
The native way to give an agent data is a service principal or a token — a standing identity with standing access. That’s the exact opposite of what agentic workloads need. There’s no native notion of an agent borrowing a specific human’s entitlements for a single task, no automatic expiry when the task ends, and no dual-identity record that ties the agent’s reads back to the person who authorized them. Build it yourself and you’ve built a small authorization system. That’s the system Immuta already is.
Make sense of all of it
The Comply app
The flip side of opening data access up is being able to answer, at any moment, who touched what. Immuta’s Comply capability ingests Databricks system tables to capture every access — every grant, query, exception, and the policy that governed it — and presents it through a conversational interface. The questions that used to take weeks of log archaeology become a sentence.
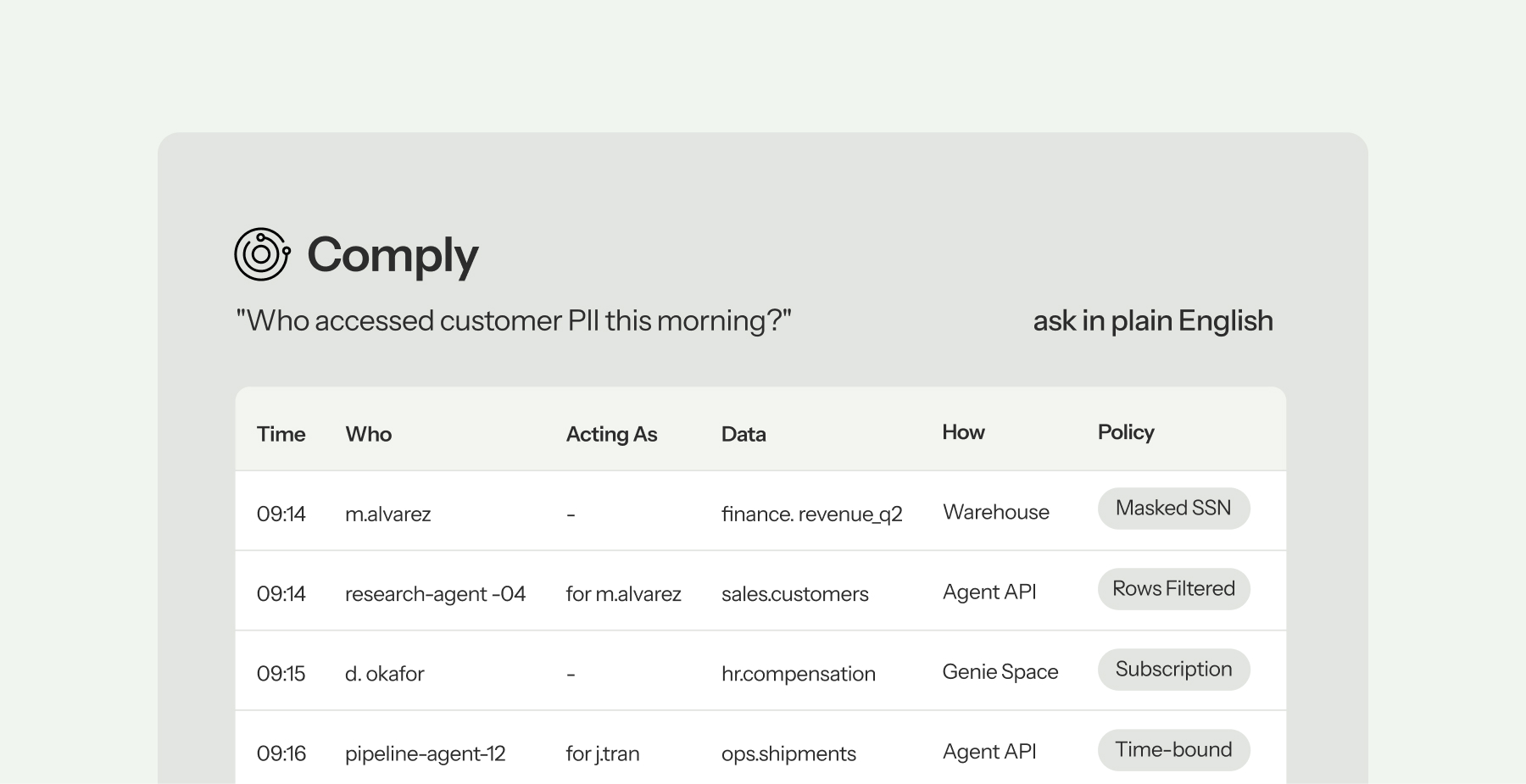
Every access — human or agent — attributed, with the policy that governed it. Ask in plain English.
Native by design — not a layer on top
How Immuta integrates with Databricks
None of this works if it slows the platform down or sits in the data path. It doesn’t. Immuta is the control plane; Databricks is the enforcement plane. No proxy, no gateway, no data ever moving through Immuta. Policies are authored centrally and pushed into Databricks as native objects, so queries run at full speed inside Databricks — and enforcement persists even if Immuta is disconnected. Specifically, Immuta integrates with:
- Unity Catalog — table, row, and column controls expressed as native grants, row filters, and column masks, with performance tuned for the largest tables and busiest workspaces.
- Databricks groups — access provisioned through native account-level groups, so entitlements follow identity, not tables.
- System tables — ingested continuously so Comply can attribute every human and agent action.
- Genie & AI/BI, Delta Sharing, and Lakebase — the same authorization layer extends to natural-language analytics, governed external sharing, and the AI application data tier.
The relationship runs deeper than a certified connector. Immuta and Databricks engineer product-to-product, which is how policy enforcement keeps getting faster and how Immuta is ready on day one for each new Databricks capability — so governance is never the reason a rollout stalls.
Why spend money on Immuta?
Better together
Here’s the buying decision in one sentence: Databricks gives you world-class enforcement primitives, and Immuta is the system that operates them — across your whole estate, for every human and every agent, with the authoring, workflow, and attributed audit that turn raw enforcement into a governed, provable program. You can assemble a version of that yourself out of SQL, grants, tickets, scripts, and homegrown audit queries. Most teams that try end up maintaining a fragile internal product, on the platform team’s clock, that still doesn’t cover purpose, cross-platform, or agents. The question isn’t whether it’s possible without Immuta — it’s what that build-and-maintain costs you in engineering time, audit risk, and stalled access.

For the platform team, Immuta means getting out of the access-request and SQL-maintenance business. For security and compliance, it means deterministic enforcement and an answer to “who touched this?” — including which agent, for which human — in seconds rather than a forensic project. For the CDO, it means being able to say yes to more users, more data products, and more AI, because every yes is authorized by policy the moment it’s granted. And for anyone betting on agents, it makes Databricks the one place in the company you can safely point them.
That’s the better-together story, told straight: the most capable data and AI platform, plus the authorization layer that lets you open it up — at scale, across platforms, for humans and agents — without losing control or building it yourself.