

The common narrative is that AI can now allow previously non-technical users to interact with the raw data. It removes the need to understand SQL. This is true but in a complex enterprise environment, there are challenges and hurdles to overcome if you want to achieve this at scale.
The old way
The traditional way to access data is SQL. SQL (Structured query language) has been around since the 1970s. It is a language used to talk to data. It’s not a natural language like English but a formal rule-based language for databases. Traditionally it has been technical staff who understand SQL and use it to interact with data.With the advance of LLMs and MCP servers, SQL is no longer the only way to talk to data. Today you can ask your agent of choice a question in natural language, it can understand the question and translate it to SQL and execute the statement directly on the database and return the data you want. The database is not changing. This now can make everyone a user of the raw data.
Is it this easy?
Not quite! Enabling this in large organisations is not as simple as giving users a chat interface with the latest model and pointing it at every database. The models have been trained on large datasets taking months to fine tune. It has not been trained on the data within the organisation so to provide business centric value it needs access to the data. In many organisations, that data is stored and managed in a range of different systems, such as SaaS platforms, Data Warehouses, legacy on-prem databases, object stores such as S3, Excel spreadsheets etc… Providing access to this data will still present the same access and privacy requirements with accessing the data directly or via SQL but the scale is dramatically increased.
What are The challenges
Providing user logins
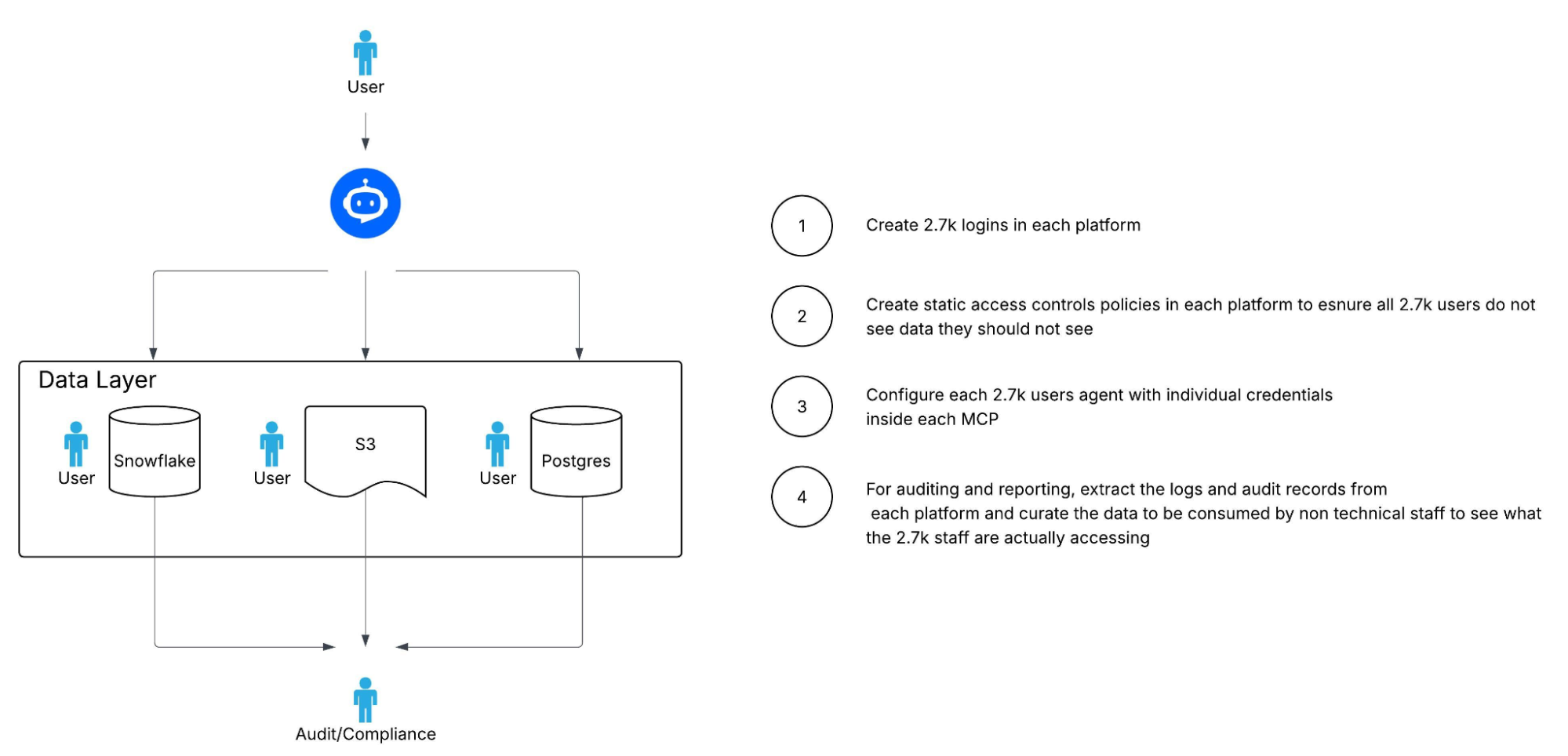
Databases and any data store (i.e. S3) have built-in access controls that govern who can access data. Traditionally, these are managed by mapping user logins to system specific roles. So now for every user that wants to chat to the data will need a login to all the different databases and data stores. This requires significant involvement from your IAM team to create these accounts and then manage the governance around this.
Standing privileges
In most systems, the role contains the authorization not the login. This means the role associated with the user will determine what data they can access. Since the new set of users will ask questions (i.e. show me all customers that have not purchased in the last 3 months) rather than constructing a logic SQL based on a deeper understanding of the data, the task will be to try and predict or hard-code all permutations of access for all users. This is what is termed a standing privilege, a set of predefined and static rules.
Gaining User adoption
Ensuring that the new AI Agent provides benefit and returns meaningful contextual relevant data is paramount to gaining adoption. This requires that the agent can access meaningful data in real time and provides the end user with a simple and intuitive process to request access to more data if existing access controls restrict access to certain data.
Audit and regulatory requirements
The requirements for audit and regulatory are still the same however now you need to manage it across a wider range of users and different systems. Each system has a unique way of maintaining logging and audit records. To get a consistent view will require pulling all this information and trying to provide a unified view.
Better organizing of data ownership
With the increase of users accessing data, the number of requests for access to the data will increase dramatically. Simply routing this to a central IT team to manage and provision access will overwork the IT and slow adoption.
The scale challenge with putting it all together
Consider a mid size organization with 3K staff. Traditionally 10% of the staff had direct access to the data layer. To fully enable the remaining 2.7K staff to chat to the data will require significant onboarding and advanced planning to ensure they do not get access to data they should not.
Why can't OAuth or user impersonation solve this?
This still requires pre-defining the scope/role in advance, rather than having role bloat, now it will also have scope bloat. OAuth scope was designed for broad actions (i.e. create meeting) rather than granular access to data. In addition, assigning these hundreds of scopes to a single shared service account is brittle, difficult to manage at scale and opens the possibility of security blind spots.
Impersonation can make it much harder to understand who actually did something, which is one of the main reasons security and governance teams are cautious about it. This leads to muddy audit trails. You still need to have a login to where the data lives to be able to set up user impersonation.
Even if you manage to build this, if an agent hits a semantic or permission wall and can’t go any further, there is no avenue to easily grant access without having to create a new scope/role and wheeling that out.
Using pre-defined service accounts is basically like sharing a login, all users will get the same access, either it is too broad which provides over provisioned access or it is too narrow and does not provide any value. Plus from an audit perspective, it is impossible to understand who ran the query.
How does Immuta solve this?
Immuta’s agentic provisioning is a fundamentally different operating model that allows humans and AI agents to work together quickly and safely.
Context + Policy
Building upon the core offering of Immuta, you define your global policies across all your platforms (i.e. Managers and Directors should only ever be able to see their direct staff’s salary information). This ensures that when granting access to a broader range of users that they will not get access to data they should not have.
Onboard all your users from your identity systems into Immuta and centralize their groups and attributes (i.e. who is this person’s manager)
Onboards all agents who will be fetching the data from the different data stores on behalf of the human users
This builds the secure data governance base to ensure that neither the human or AI Agent will get access to data they should not have access.
Question Time Planning
The human user will ask a question to the chat interface, the agent will analyze the question and understand who is asking the question and where the data lives (i.e. table x in data platform Y). Immuta will instruct the agent on whether the user has access to data as per the policies, if they do have access Immuta will vend a short lived role that will allow the agent to fetch the data on behalf of (OBO) the user.
This solves the problem of having to create the user in each data platform, as the agent will fetch the data but on behalf of the user
Exception Based Access
If a user asks a question and Immuta understands that the user should not have access to the data, Immuta can provide a workflow that the agent can guide the user through to request time bound access to the data. This workflow will prompt the user to document the need for the data and how long they will need access to. The request will be routed to the appropriate approvers. If the request is approved, then Immuta will vend a short lived role that allows access to that set of data required to answer the users question.
This solves the problem of having to pre compute standing privileges in advance and will allow greater adoption as users are now able to easily ask for data in a unifed and easy to understand way.
AI Review Assist
It is expected that the number of exception based access requests will rise and will move the workload from the IT team to grant access to the data approvers. To assist with this, Immuta has built an AI Review assist. Using LLM, Immuta will train the model on previous approved/denied requests. This tracing will provide the approvers with a risk rating from low to high to highlight how risky each request is. This can be extended to provide automatic access. For example if a request is rated as low risk, then policies can be created to auto approve access.
Compliance made simple
As Immuta has integrations into the data layer that allows the extraction of audit information, this audit information will be overlayered with the policy logic and user profiles to provide a single place for all staff whose job it is to ensure compliance to come ask questions. For example, they could ask the question “Who has accessed PII data in the EMEA region in the past 7 days and why they were able to access it”
This is leveraging the Immuta Comply app and this can be trained per organization depending how they conduct compliance. This solves the issue of managing auditing/compliance for Users/Agents across many different data platforms.
FAQs
Why can’t I use shared service accounts to grant agents access to my data?
Using pre-defined service accounts is basically like sharing a login, all users will get the same access, either it is too broad which provides over provisioned access or it is too narrow and does not provide any value. Plus from an audit perspective, it is impossible to understand who ran the query.
What are vended roles and why do they matter?
A vended role is a short lived role that contains the authorization to access the data that is needed to answer the question. The agent will use this role to fetch the data on behalf of the user. The vended role solves many problems but the biggest benefit is that it allows a dynamic way to provision data and break away from hard coding all access rules in advance.
Is this just a technical solution?
No, this is a fundamental shift in the way to provision access to data. It will require organizing your data into domains and identifying data owners and approvers. This removes the dependency on a single team to manage all access plus provides the foundation to allow question based data access.