

Immuta has enhanced the functionality of our Starburst data access control integration by allowing users to avoid having to use a catalog in Starburst to query Immuta-protected tables. This change simplifies data governance policy enforcement in Starburst, making Immuta even more transparent, and in most cases completely invisible to data consumers.
In this blog, we’ll investigate how this integration works, its benefits, and some of the additional features Immuta provides to Starburst users to enable dynamic and scalable data security controls.
Creating a Data Governance Policy in Starburst
By protecting the base objects in Starburst, Immuta simplifies data access patterns. Consider the screenshot below of sample catalogs before Immuta is activated:
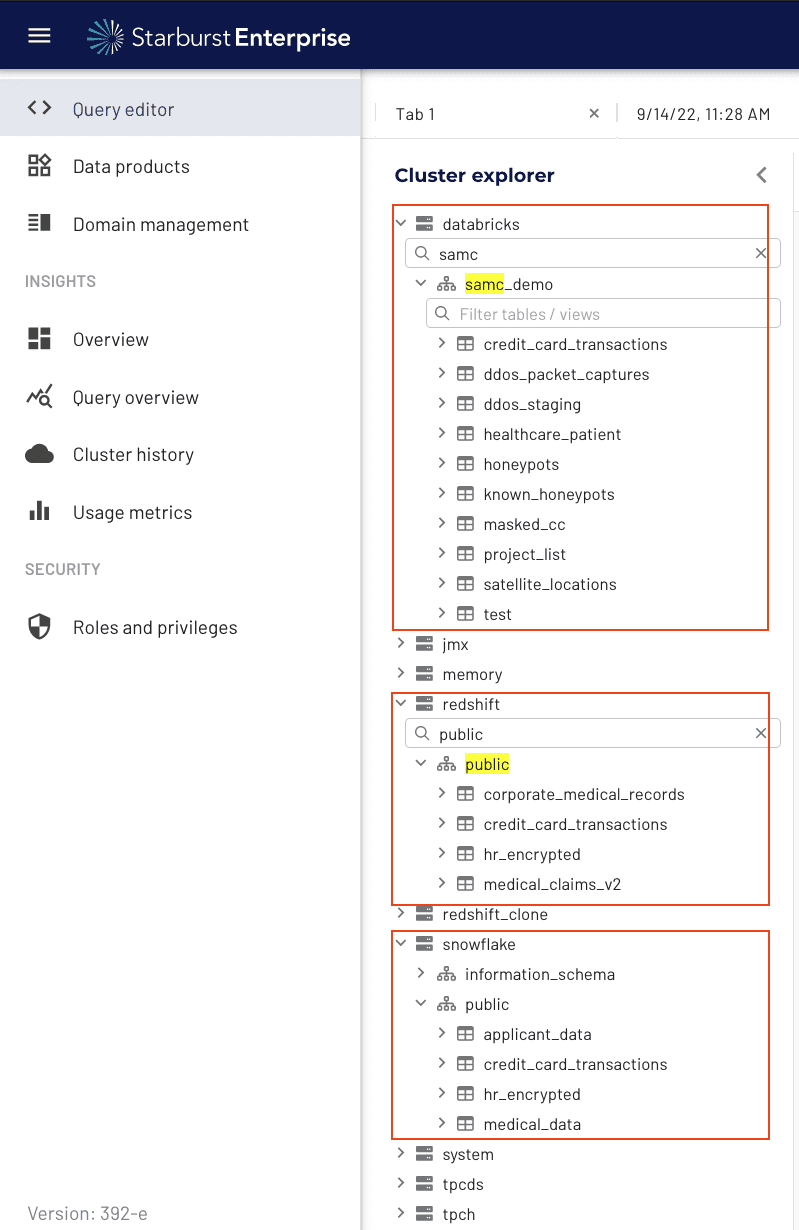
You can see there are many catalogs and tables available to users. With Immuta, you can build a policy that allows you to control access across all the tables and views within Starburst using understandable policy logic. For example, let’s say you want to build a policy telling Starburst that only users in the Finance or Analytics Departments can see Financial data sets containing a credit card number:
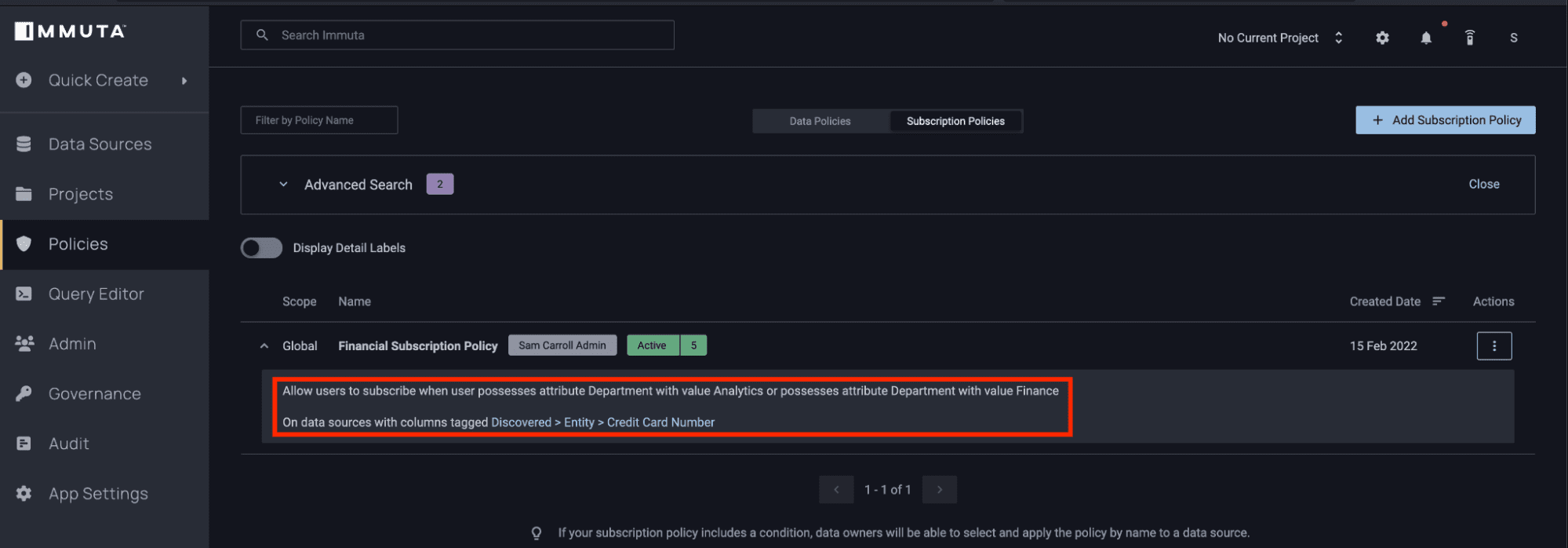
Previously, this would have required creating a view in an “Immuta” catalog in Starburst that revoked access to the base catalog tables or views. With the enhanced integration, however, you will notice that the user in the Analytics group is now only able to see the tables in these catalogs that contain credit card information:
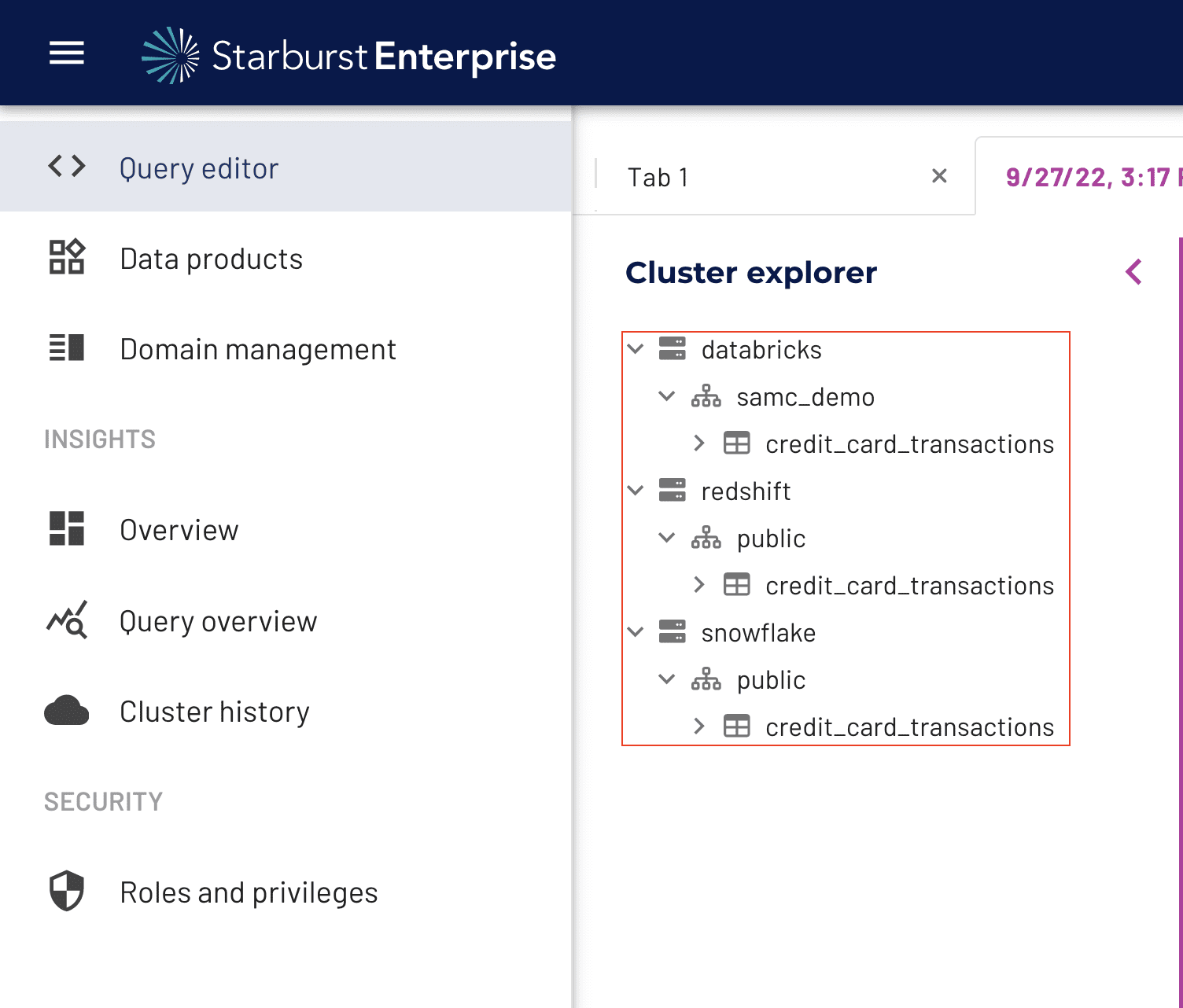
Masking Sensitive Data with a Starburst Data Governance Policy
Now that the users have access to tables, you can build a data governance policy that masks the sensitive data in the tables:
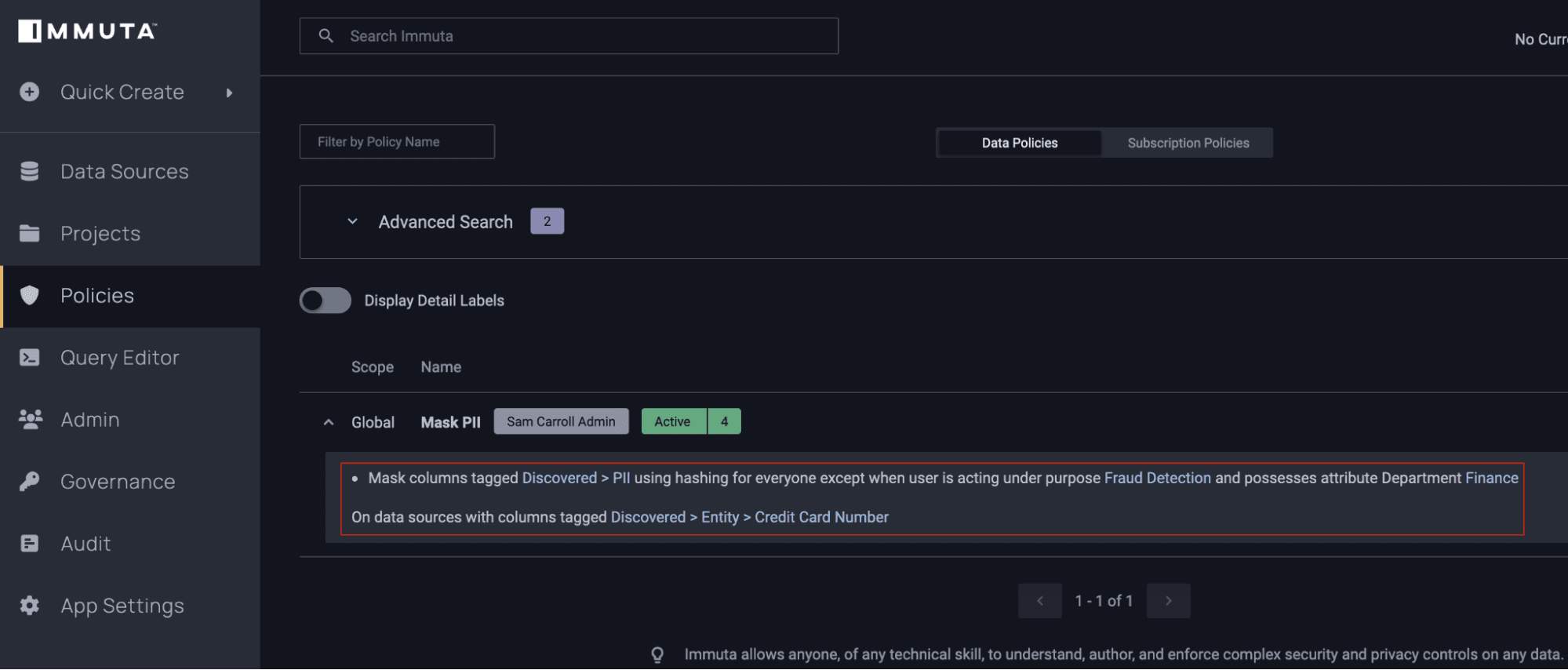
This easy-to-understand policy will apply to tables based on the sensitivity of the data contained within them, allowing Immuta to build scalable policies by decoupling them from the platform. Ultimately, this greatly simplifies policies and reduces risk of duplication.
Now if a user runs a query in Starburst, any personally identifiable information (PII), including credit card numbers, will be masked:
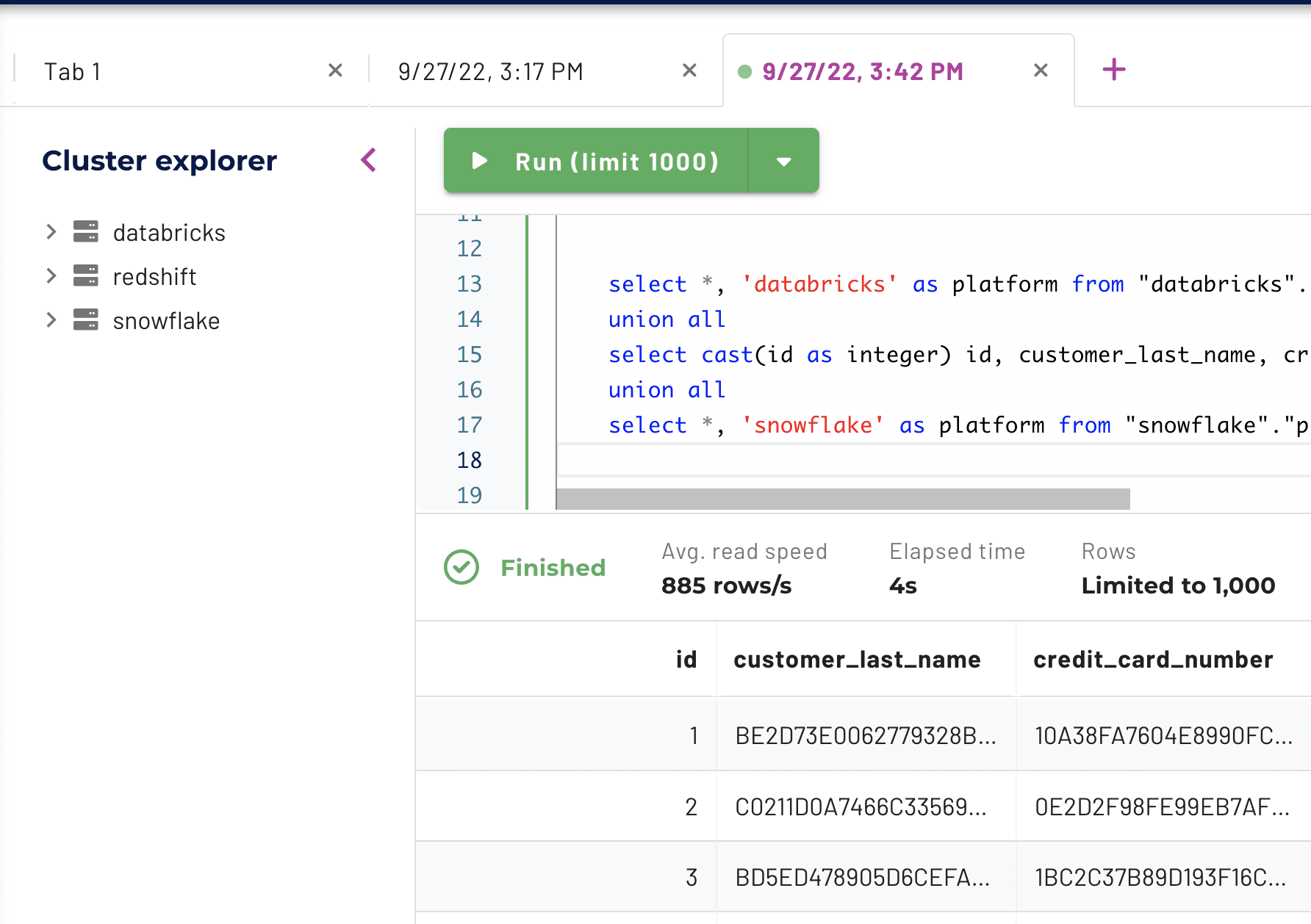
Now that you’ve enabled a masking policy, you’re able to look at the uniqueness of credit cards across systems in your tech stack:
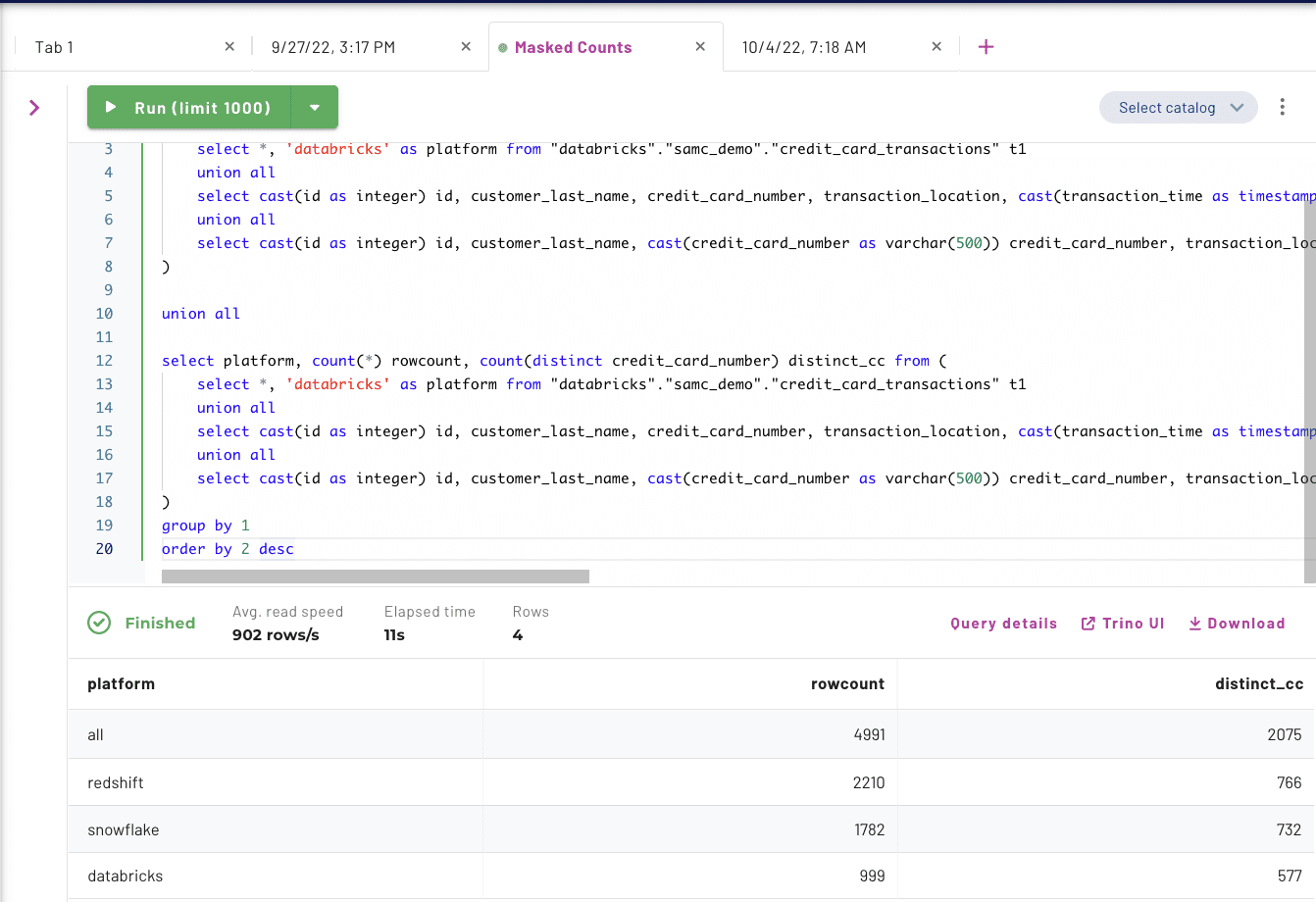
The counts of distinct credit cards from Redshift, Snowflake, and Databricks add up to 2,075 different numbers. Immuta uses a randomized SHA256 hash on these values to mask each credit card number, but that doesn’t account for the same number existing in more than one table.
How do you figure out if this is the case? Since the data is sensitive, simply unmasking it is not an option. And, if you try to see whether a credit card exists in both Databricks and Snowflake, you won’t get any matches because of the unique salt used when hashing for each column in the data set:

Creating a Purpose-Based Data Governance Policy with Immuta
Let’s imagine a scenario where you might need a join on the masked credit card value to do further analysis. Generally, users don’t actually need to see the masked column value; they just need to ensure referential integrity when doing the join. In other words, they don’t care what the credit card number is, they just need to know if it shows up in another system so they can get aggregate information or gather additional details about a transaction.
This is where Immuta projects come into play. A project is a logical grouping of data sets that can be associated with a user’s intent or purpose.
In this example, you will define a specific reason someone could request a standard salt to be used when joining data sets. Below is an example of a project in Immuta:
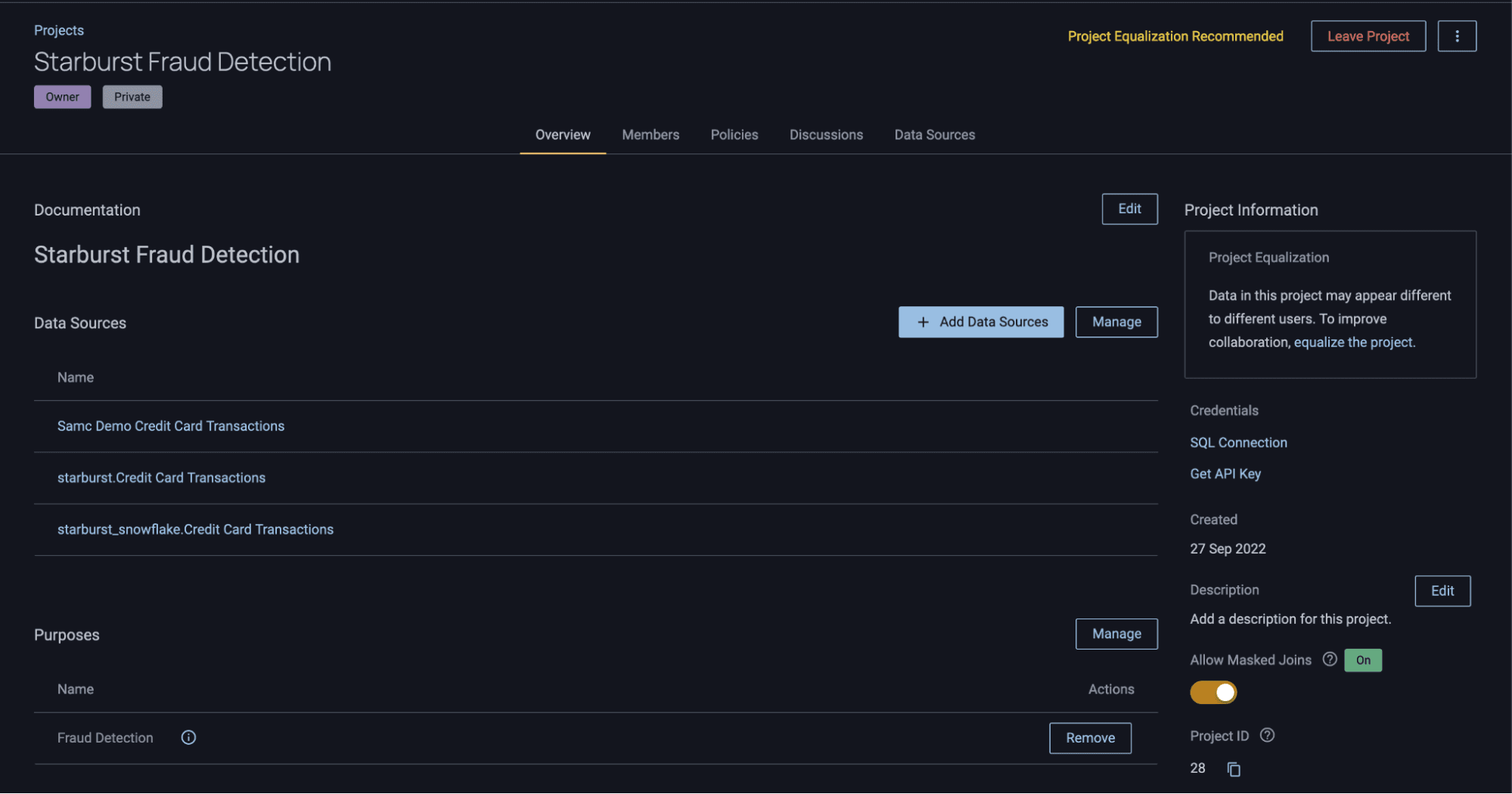
In this project, there are three tables, each of which is derived from different catalogs in Starburst: Databricks, Redshift, and Snowflake. You’ve also created what’s called a “Purpose” for the project, which is an agreement or attestation that users must follow when accessing the data. Purpose-based access control allows you to associate a user’s intention with their ability to access data, giving you greater flexibility and control over how that data is used. It is also fully customizable, audited, and enforceable through Immuta.
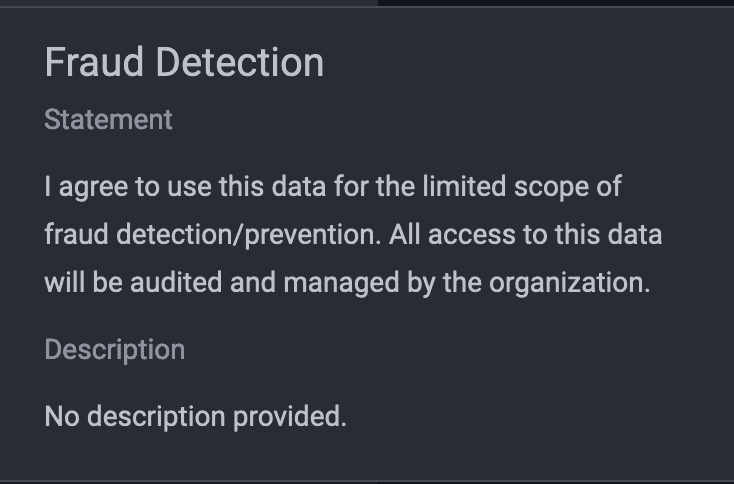
The purpose in this project reads as follows:
Next, notice the “Allow Masked Joins” toggle in the lower right of the project UI:
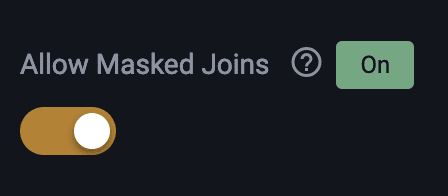
As mentioned above, this toggle tells Immuta to use the same salt when hashing columns in these source systems. As a result, you can ensure that referential integrity will stay intact while operating under this specific project context.
Let’s see what happens when a user switches into this fraud detection context. The first step is to select the project in the top right corner of the Immuta UI:
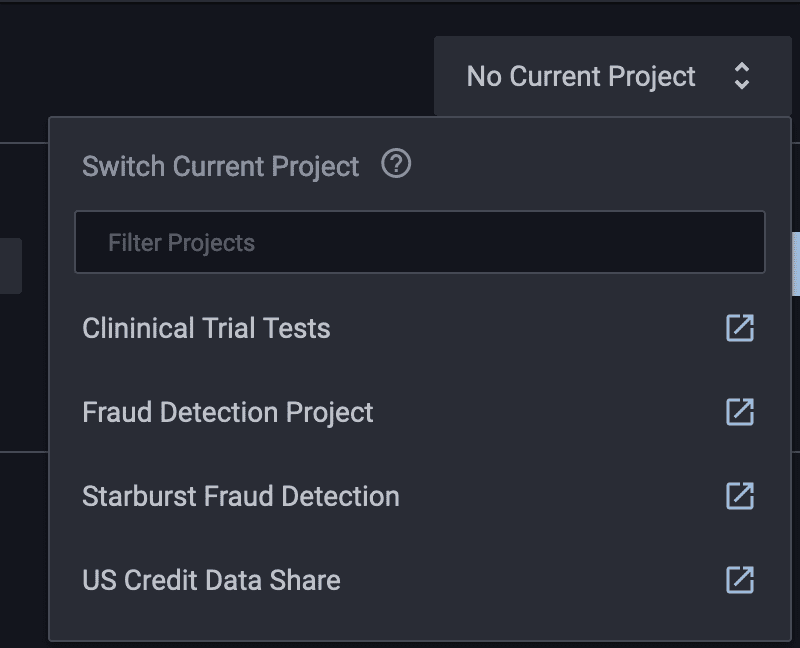
Once you’ve selected “Starburst Fraud Detection,” you can run a query in Starburst that will show the number of unique credit cards in each platform. When you ran the COUNT(DISTINCT_COLUMN) query earlier, you had a total of 2,075 different credit cards and no matches between Snowflake and Databricks. Now, after switching to the project context, you have 906 distinct credit cards.
Validating a Data Governance Policy for Starburst Queries
Next, you must verify that the data is, in fact, being masked correctly. To validate the hashing is working correctly, you’ll remove the hashing and find a specific credit card number to analyze before masking, after masking, and within a project context. This can be done by using some identifiers that you know will return the same credit card, as shown in the query below:
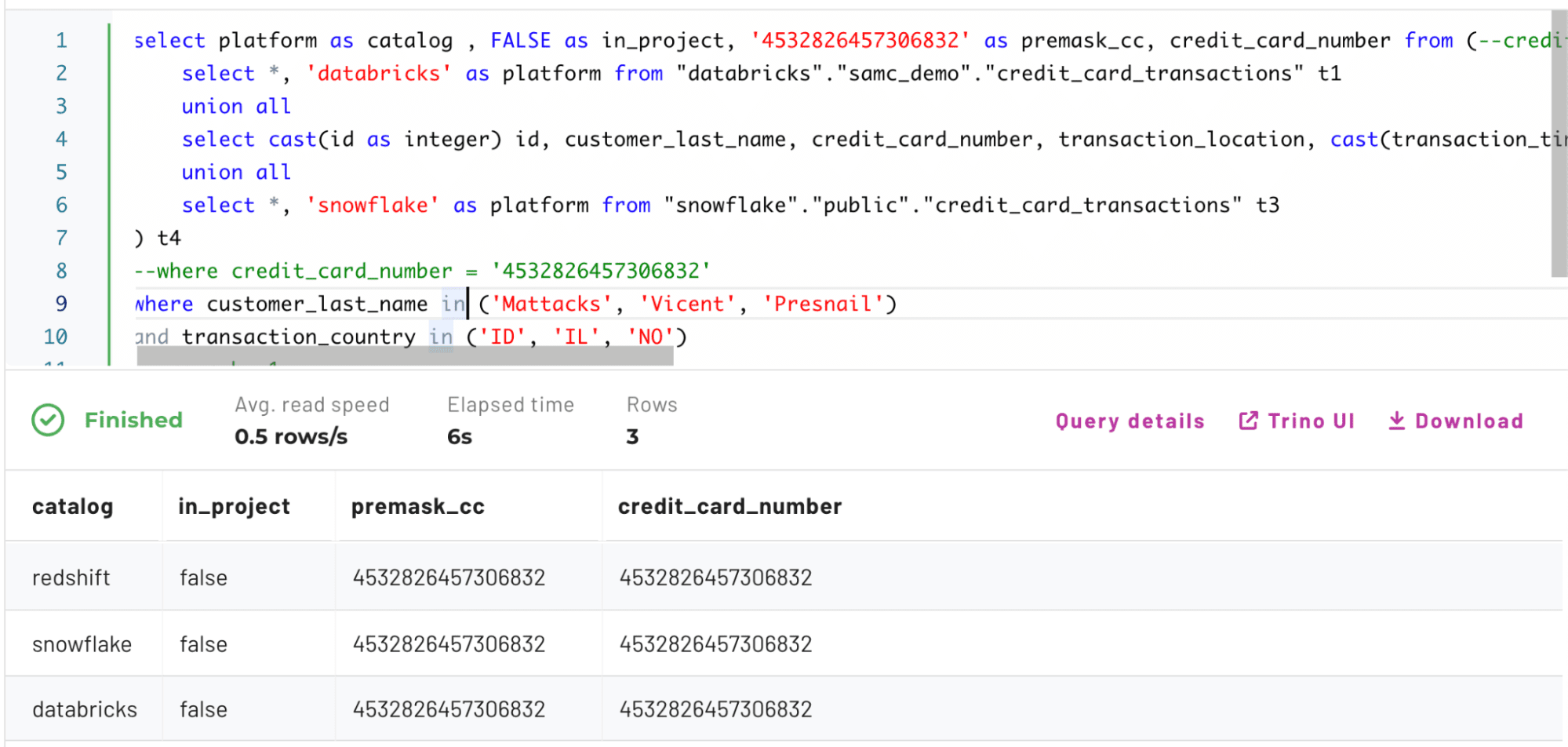
The output shows four columns: catalog, in_project, premask_cc, and credit_card_number.
The catalog column represents where the credit card number was found, in_project denotes whether you were operating under a project context, premask_cc is a hardcoded value for the credit card number before hashing so you can see how it has changed, and credit_card_number is the actual column value returned or modified by the Immuta policy.
Now that you’ve confirmed there are three rows containing the same credit card number across Redshift, Snowflake, and Databricks, take a look at what happens to the base table after a masking policy is enabled:
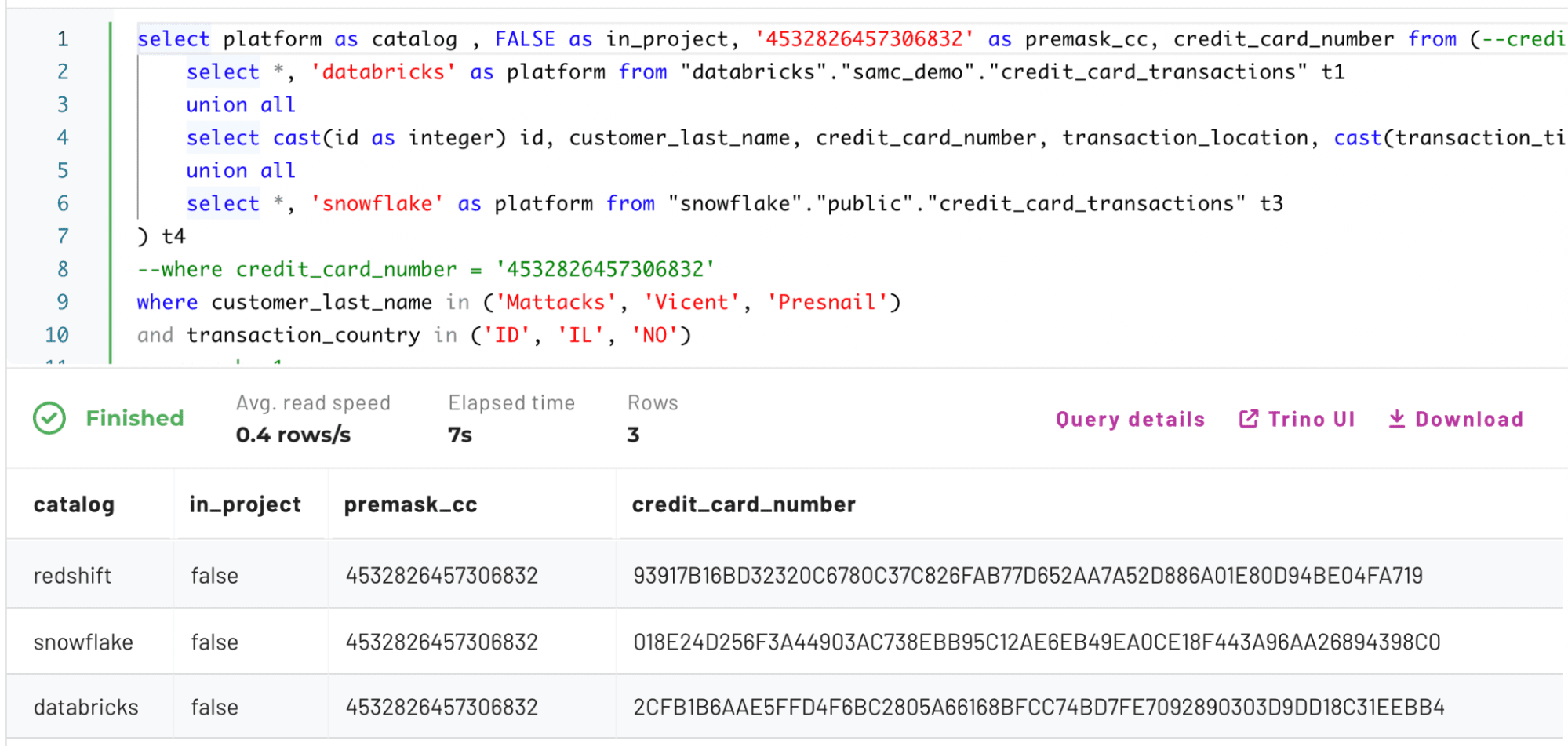
You can see how the credit_card_number has changed since enabling the hash. Each hash in this scenario is unique because of the hash + random salt mentioned earlier.
Now let’s switch context into the fraud project that enables masked joins:
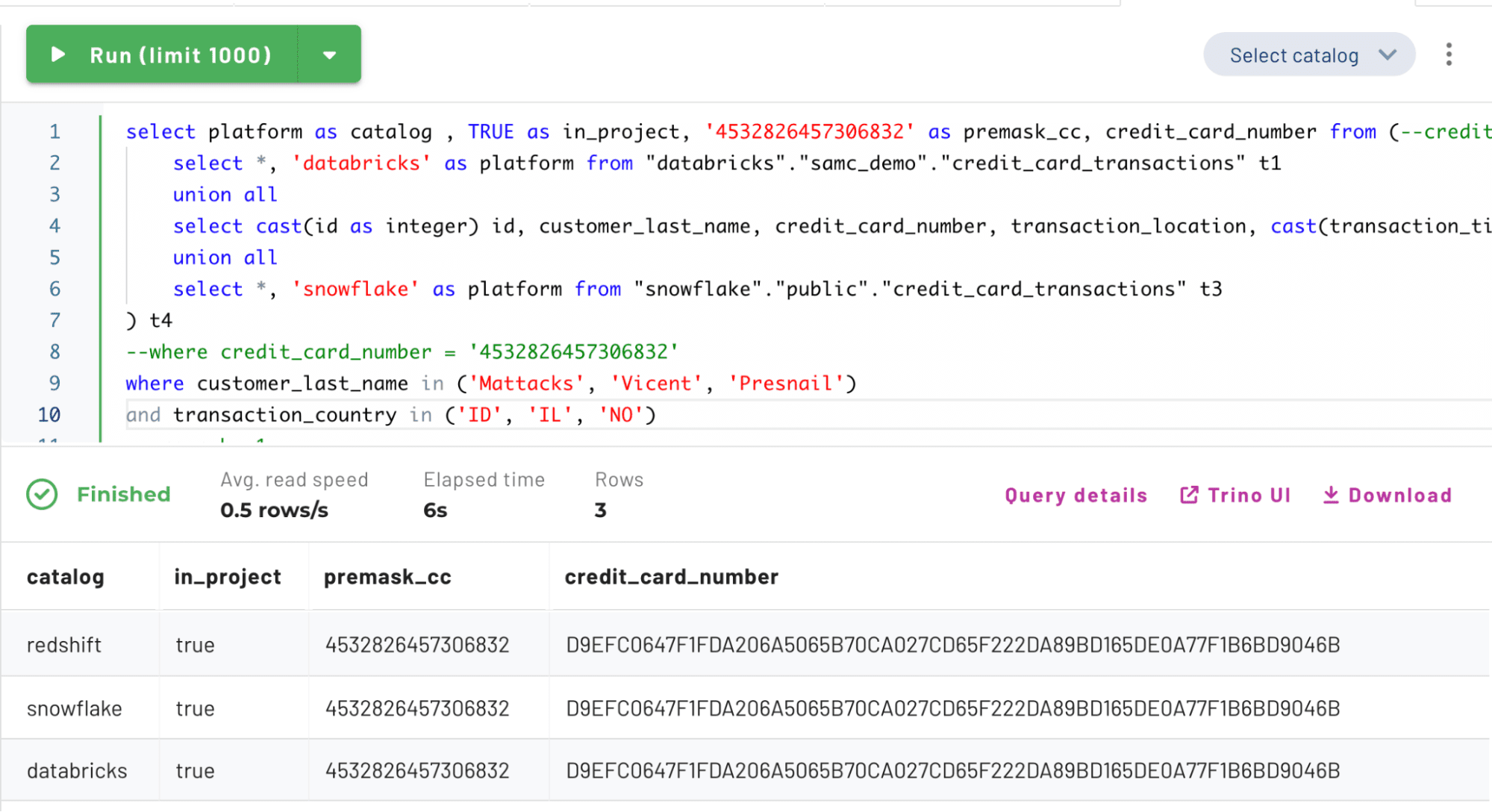
You can see how the credit_card_number column’s return value has changed to be the same hash value because a shared salt was used across the three tables in this specific project context. This project context gives users more fine-grained access control and greater flexibility when operating with sensitive data. Users can also gain or lose access to projects based on time or a subscription rule.
Auditing a Starburst Data Governance Policy
Now that you’ve seen how Immuta works on the base tables in Starburst, let’s take a look at how Immuta enables data monitoring and audit logs. If you switch into the Immuta audit UI, you can see user activity as well as the purpose/project under which they were operating:
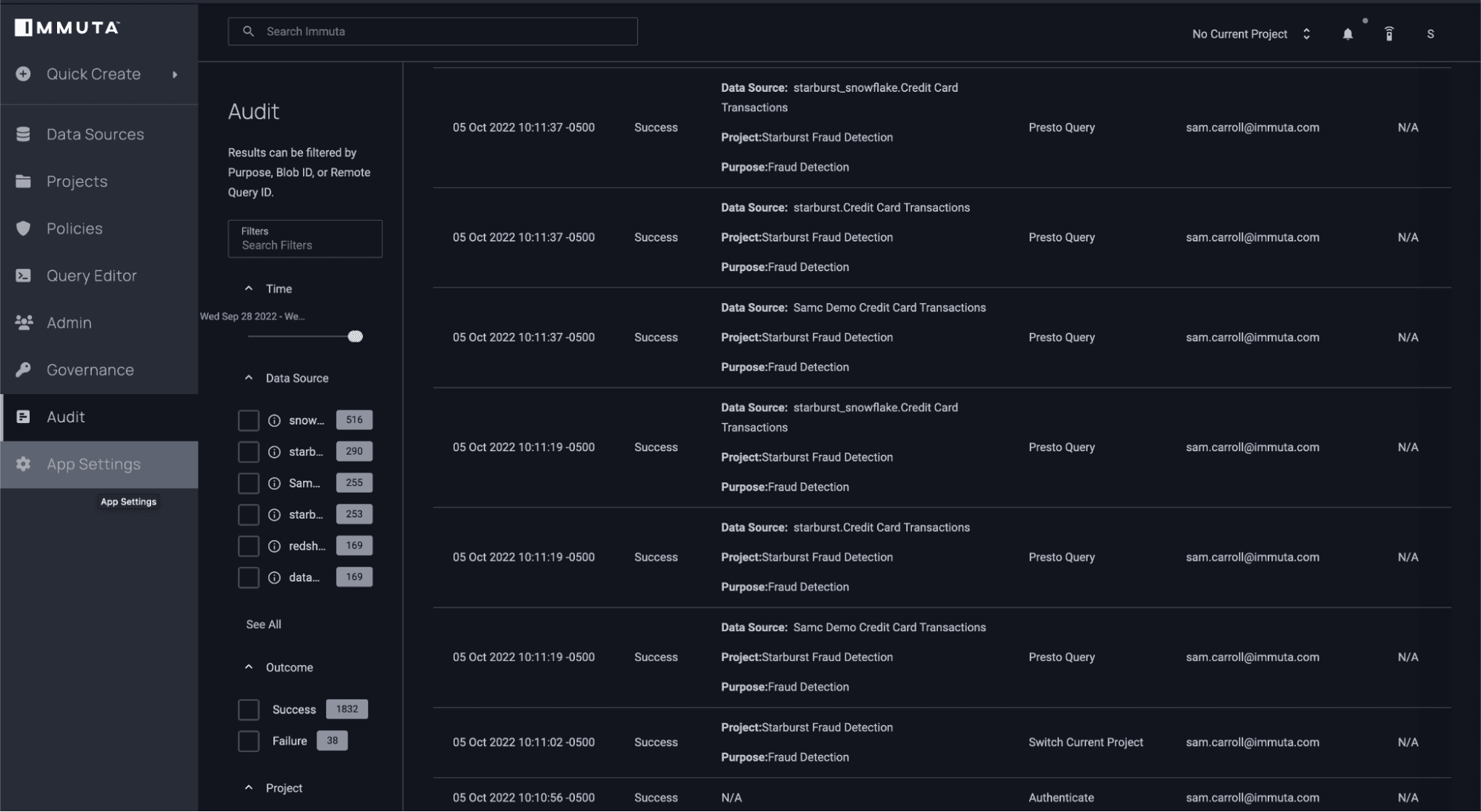
Immuta’s enhanced Starburst integration makes data access control and security scalable. Applying policy on the base catalog objects greatly simplifies and reduces access maintenance that has historically been associated with access control. This functionality, coupled with Immuta’s advanced security features, allows data users to secure data while quickly gaining valuable insights from it.
To see how this works in action, check out this video or schedule a demo with a member of our team.