The adoption of the Data Lakehouse architecture is soaring across various industries, as the new and open paradigm combines the best elements of data lakes and data warehouses. Open file formats with transaction support, combined with low cost storage and wide adoption, enable new ways of working with data pipelines and machine learning workloads.
Azure’s data platform center of gravity is Azure Data Lake Storage with Delta file format. Clear storage and compute separation allows users to choose the data engine best suited for a particular use case. Customers might use Azure Synapse for data warehousing workloads, and Databricks for advanced analytics and ad hoc data exploration. Both platforms can run on top of the same data stored in Azure Data Lake.


While Azure Lakehouse architecture enables new ways of working and the flexibility to select the right tool for the job, Azure data access control and data management becomes even more complex.
[Tip] Learn more about the evolution of data access control in RBAC vs. ABAC: Future-Proofing Access Control.
Data Access Requirements for Modern Data Platforms
A modern data platform should provide capabilities to control who can use what data and why. Technically speaking, such a data platform should:
- Provide object-level access
- Enable column-level security
- Mask sensitive columns
- Enable row-level security
- Provide time-bound access
- Document access purposes
- Control access management lifecycle
- Automate the above with data attributes
- Provide audit reports
Satisfying Databricks SQL Analytics and Azure Data Access Control Requirements
Data access control in Azure Synapse or Databricks SQL Analytics requires a wide range of techniques. Depending on how data is stored and modeled, a developer might need object-, column-, or row-level access methods. Each of these methods require different, platform-specific approaches. Overall, a very deep technical and platform-specific knowledge is necessary.
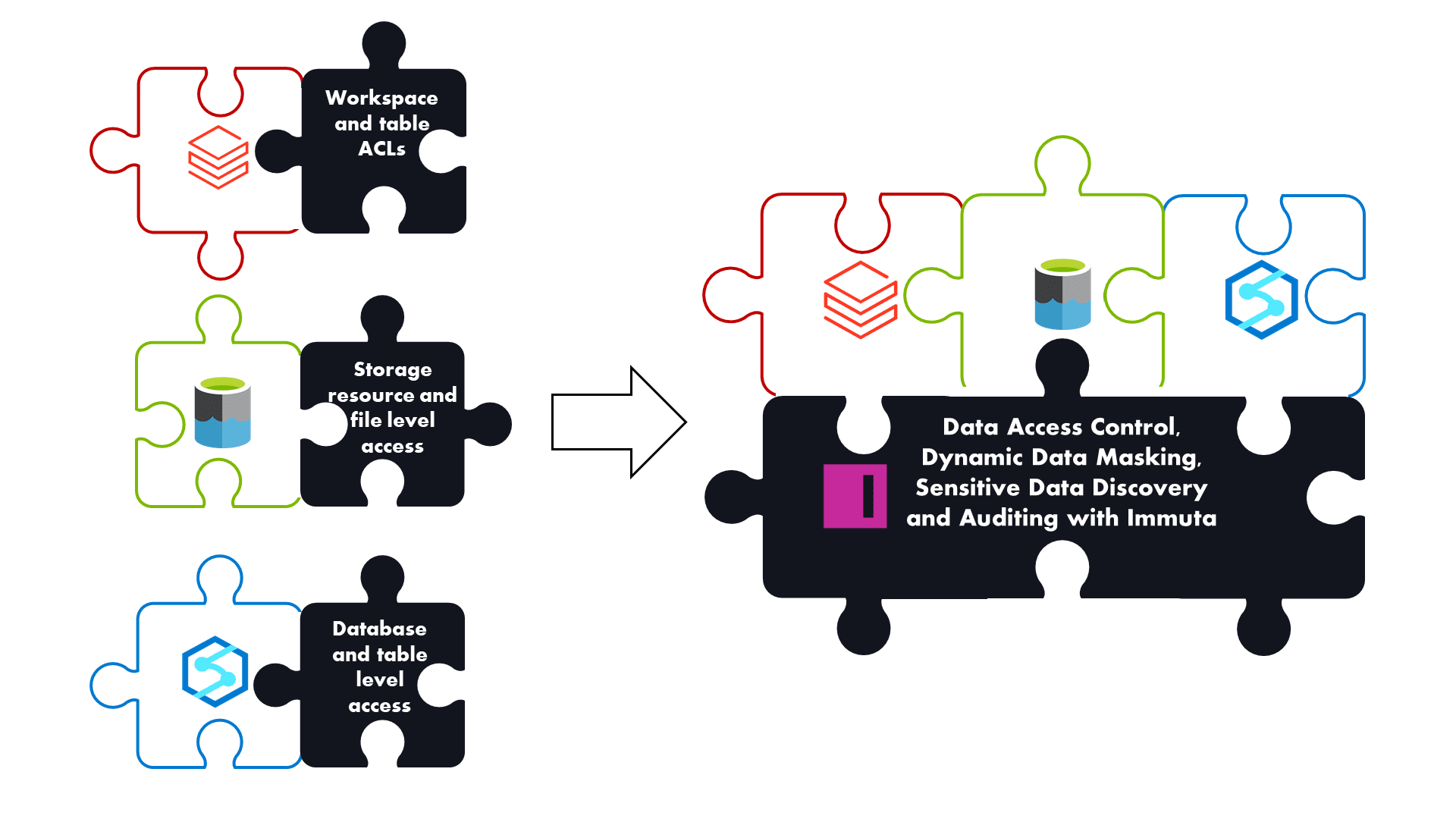
The first half of this article explores the access policy creation process within Azure Synapse and Databricks SQL Analytics, and the second half presents an alternative access management approach with Immuta. Immuta’s latest upgrades for Azure Synapse and Databricks SQL Analytics provide automated data access controls and a unified solution for Azure Lakehouses.
Satisfying Data Access Control Requirements with Immuta
Immuta takes access management capabilities to a new level. A wide range of connectors to storages and compute engines creates a security layer on top of your data ecosystem. This eliminates the need for platform-specific data access control solutions and reduces complexity.
Immuta’s access control policies also include advanced privacy enhancing technologies (PETs) — such as dynamic data masking, differential privacy, k-anonymization, and randomized response. These capabilities help ensure data is protected without the need to copy or move it, further strengthening access control across the lakehouse environment.
Finally, Immuta provides a single pane of glass to manage the data access lifecycle, including access approvals, automatic audit reports, and purpose-, attribute-, and time-based access controls.
A Few Words About Prerequisites
Our showcased examples use the TPC-DS data set. TPC-DS models contain business information, such as customer, order, and product data to mimic a real retail data warehouse. Databricks SQL Analytics accesses the data directly from Azure Data Lake Gen 2, while Azure Synapse Pool has a preloaded copy.
Azure Synapse and Databricks are Azure-managed services with native Azure Active Directory integrations. Immuta runs on Azure Kubernetes Service (AKS) and requires Azure Active Directory configuration, which takes less than 30 minutes to complete.
Azure Lakehouse Data Access Control without Immuta
Object-Level Access
Databricks and Synapse satisfy object-level access requirements, but use different ACL syntaxes. Additionally, the access policies are duplicated across the two platforms.
Enable Access to All Tables with Azure Synapse Pools
Azure Synapse uses well-refined data access control mechanisms that should be familiar to SQL Server professionals. It supports Azure Active Directory users and groups.
Assuming the required users and/or AD groups are already available in a database, it’s possible to provide read access to all database objects without masking. Data access using Azure Synapse Serverless External Tables requires additional access grants on Azure Data Lake Gen 2. Managed Identity is the recommended solution that eliminates the need of Service Principals and keys.
Enable Access to All Tables with Databricks SQL Analytics
Databricks table access control lets users grant and revoke access to data from Python and SQL. Table ACL provides tools to secure data on object level.
Column-Level Access
Only Synapse satisfies column-level access requirements, as Databricks ACL requires permission logic in the body of a view definition. It is not possible to implement column-level access control on Azure Data Lake Storage.
Limit Access to Selected Columns with Azure Synapse Pools
A user can implement column-level security with the GRANT T-SQL statement. This approach doesn’t need data copies or dedicated views.
Limit Access to Selected Columns with Databricks SQL Analytics
Databricks includes functions that enable column- and row-level permissions in the body of a view definition.
current_user(): returns the current user name.
is_member(): determines if the current user is a member of a specific Databricks group (not Azure Active Directory group!)
Databricks Unity Catalog minimizes the need for permission logic in the body of a view.
Data Masking Implementation
Synapse and Databricks have basic functionality to provide data masking capabilities. Neither platform supports Active Directory attributes, so dedicated AD groups are required. However, it is not possible to implement data masking on Azure Data Lake Storage.
Mask PII columns in Customer table with Azure Synapse Pools
Azure Synapse uses dynamic data masking to hide sensitive data. Data masking can be configured on database fields to hide sensitive data in the query results. The data in the Azure Synapse database remains unchanged.
There are four types of masks available:
- Default – full masking
- Email – exposes the first letter of an email address and the domain suffix
- Random value – replaces a record with a random value that is unrelated to the data
- Custom string – exposes the first and last letters and adds a custom padding string in the middle
Mask PII Columns in Customer Table with Databricks SQL
Databricks ACL provides masking functionality that can satisfy only basic requirements, as the masking logic should be defined in views. The number of views and CASE statements might skyrocket if applied at an enterprise level, becoming unmanageable and hindering an organization’s ability to efficiently scale data access and use.
Row-Level Access
Only Synapse satisfies row-level access requirements, as Databricks ACL requires dedicated views. Row-level access is not possible to implement on Azure Data Lake Storage.
Show Only Allowed Rows with Azure Synapse
Azure Synapse provides functionality to implement row-level security by using the T-SQL security policies. It requires a complex function and predicate approach.
Show Only Allowed Rows with Databricks SQL
Again, Databricks ACL for row-level access is achievable only via views and CASE – WHEN statements.
Attribute-Based Access Control
Azure Synapse and Databricks SQL Analytics have native Azure Active Directory integrations, but neither platform can use AD attributes outside of email and group.
Azure Synapse has sensitive data discovery and classification, but the functionality is not linked with dynamic data masking or row-level access control. The required functionality is not available out-of-the-box and requires custom implementation.
Databricks does not currently have attribute-based access control. Databricks Unity Catalog introduces minimal functionality to tag columns as PII and manage access.
Databricks SQL Analytics and Azure Data Access Control Challenges
Both Azure Synapse and Databricks provide foundational access control capabilities to manage table access similar to relational database systems. However, this is impractical in a cloud lakehouse environment because:
- Data is stored in external cloud storages with no column- or row-level security mechanisms
- Administrators have to use platform-specific techniques to set up access, and not all capabilities are equal or mature in all the platforms
- Administrators need to duplicate access policies across all platforms
- Administrators might need to duplicate access policies across even in the same platform (in case of multiple Databricks Workspaces)
- Every new view/copy increases the complexity of access management
- Attribute-based access control is not possible and leads to dedicated user groups, and eventually role bloat
- Another solution is required to satisfy audit and data access lifecycle management requirements
Just like the big data era required separation of compute from storage, the lakehouse era requires the separation of policy from compute. This allows you to define policy externally from the platform and execute enforcement live in the platforms for greater efficiency, scalability, security, and auditability.
Azure Lakehouse Data Access Control with Immuta
Configure Azure Active Directory and Enable Attribute Synchronization
Immuta requires Azure Active Directory setup to enable single sign-on and user attribute synchronization. This well-documented process takes you through a dedicated Azure Enterprise Application creation process and how to link it with Immuta. The configuration takes less than 30 minutes to complete.
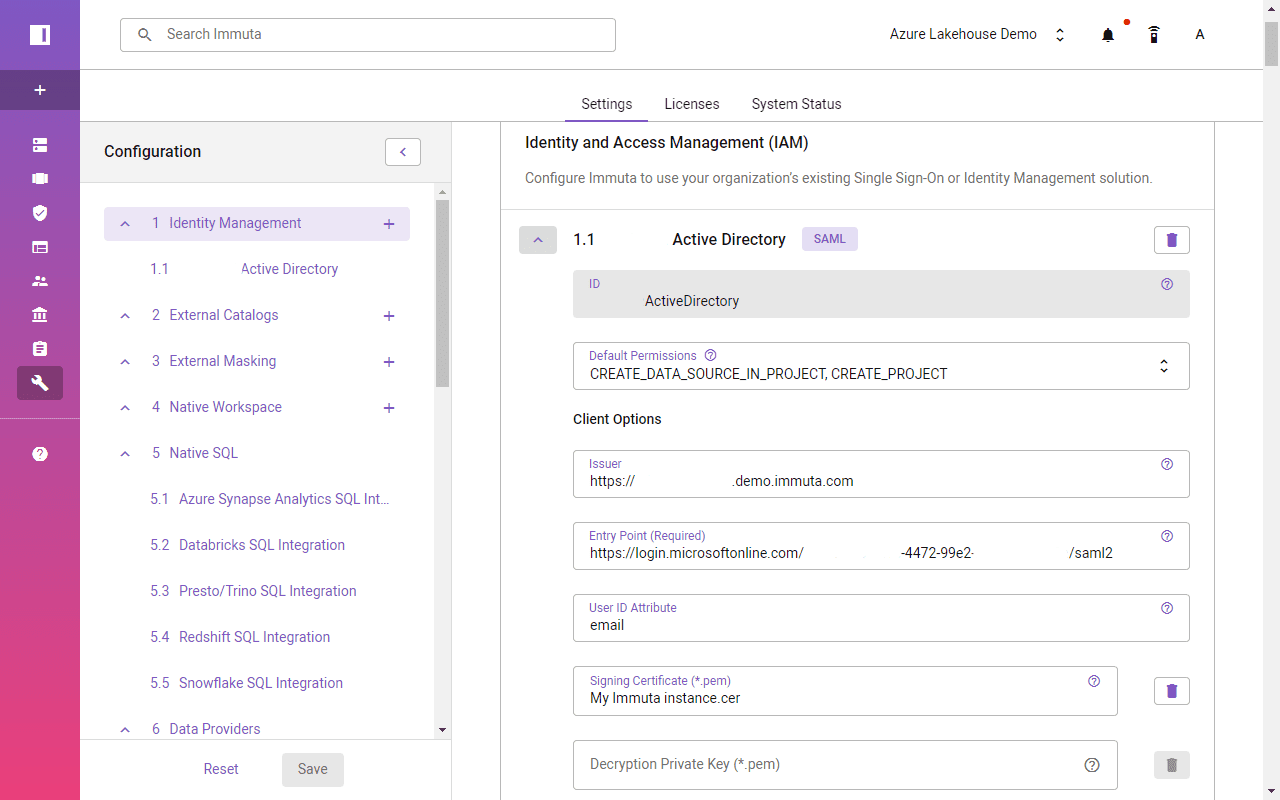
A dedicated Azure Enterprise Application will be used to enable Azure Active Directory as an IAM over SAML 2.0. In the User Attributes & Claims section, you can specify which user attributes should be synchronized between Active Directory and Immuta.
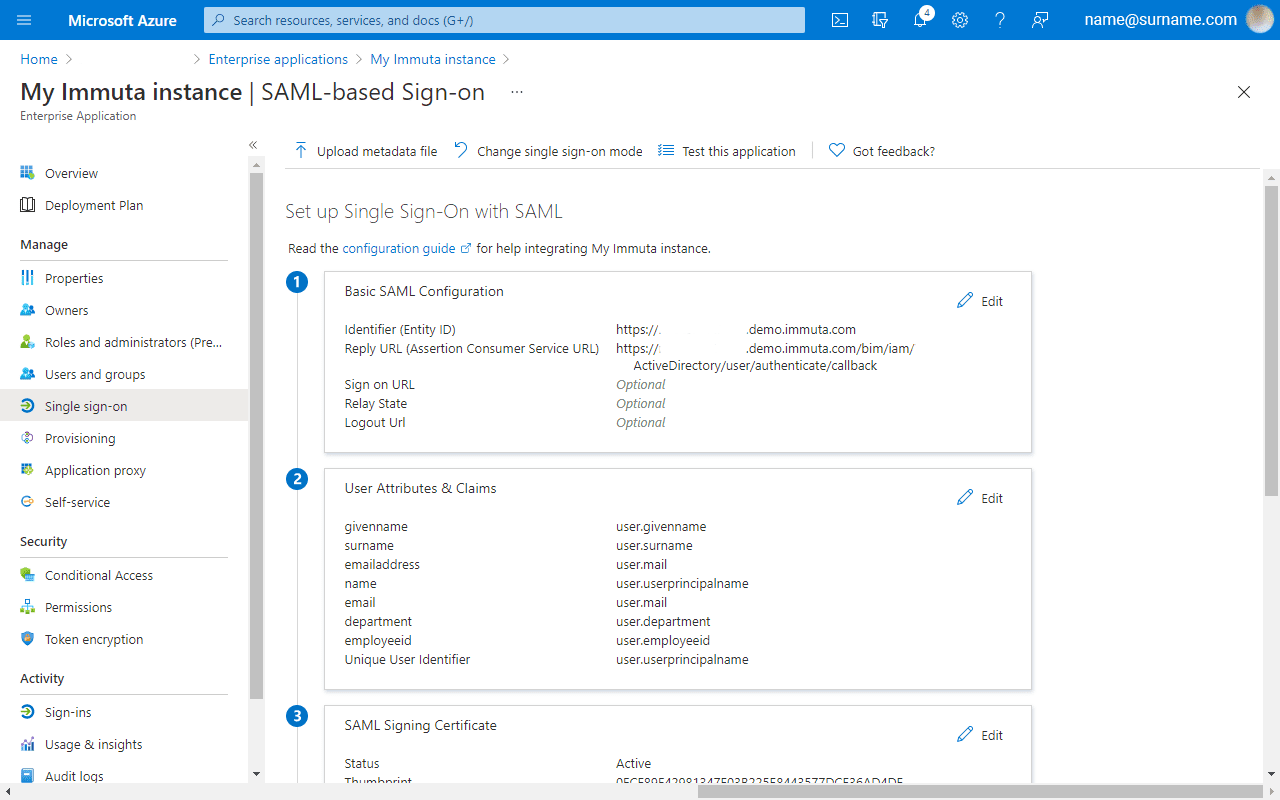
Immuta requires a few entries to connect with Azure Active Directory, such as application SAML 2.0 URL, certificate, and user ID attribute name.
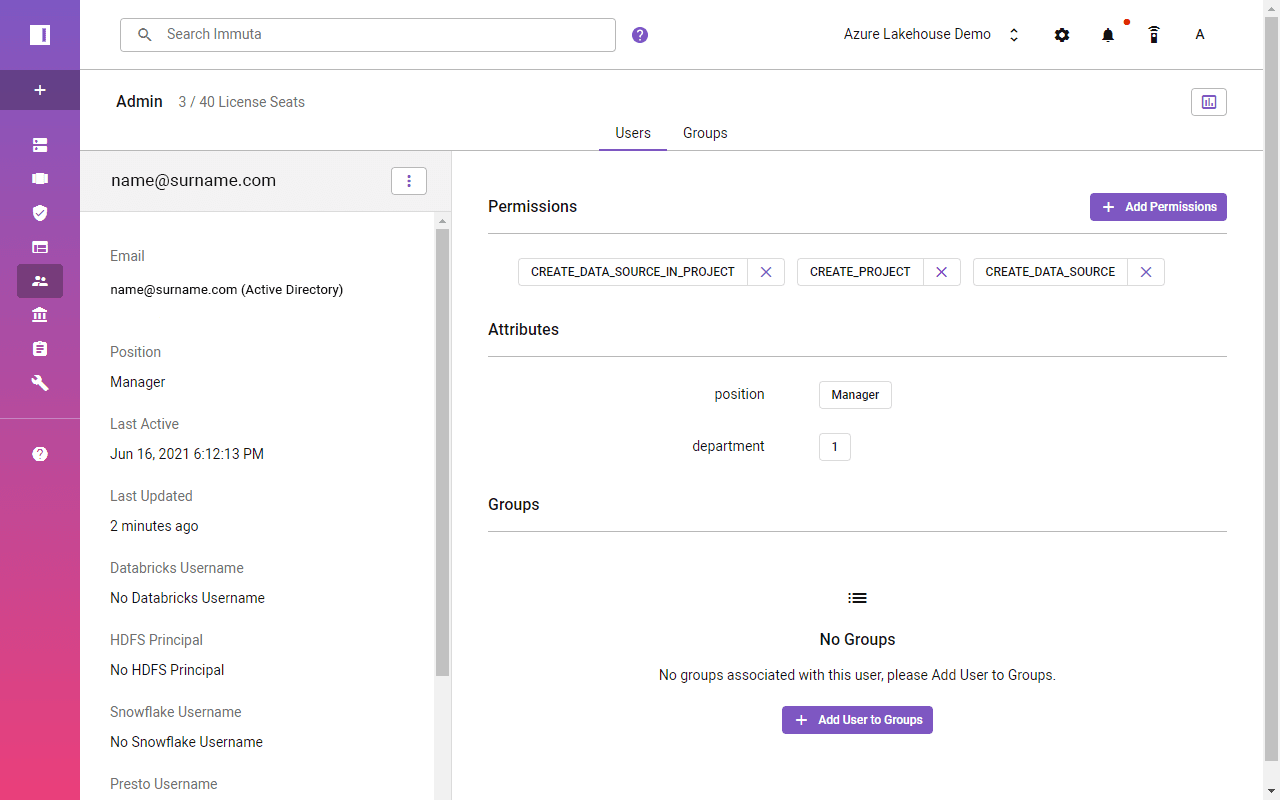
In order to use Active Directory attributes in Immuta’s access policy definitions, you must map Azure Active Directory user attributes to corresponding Immuta attribute keys.
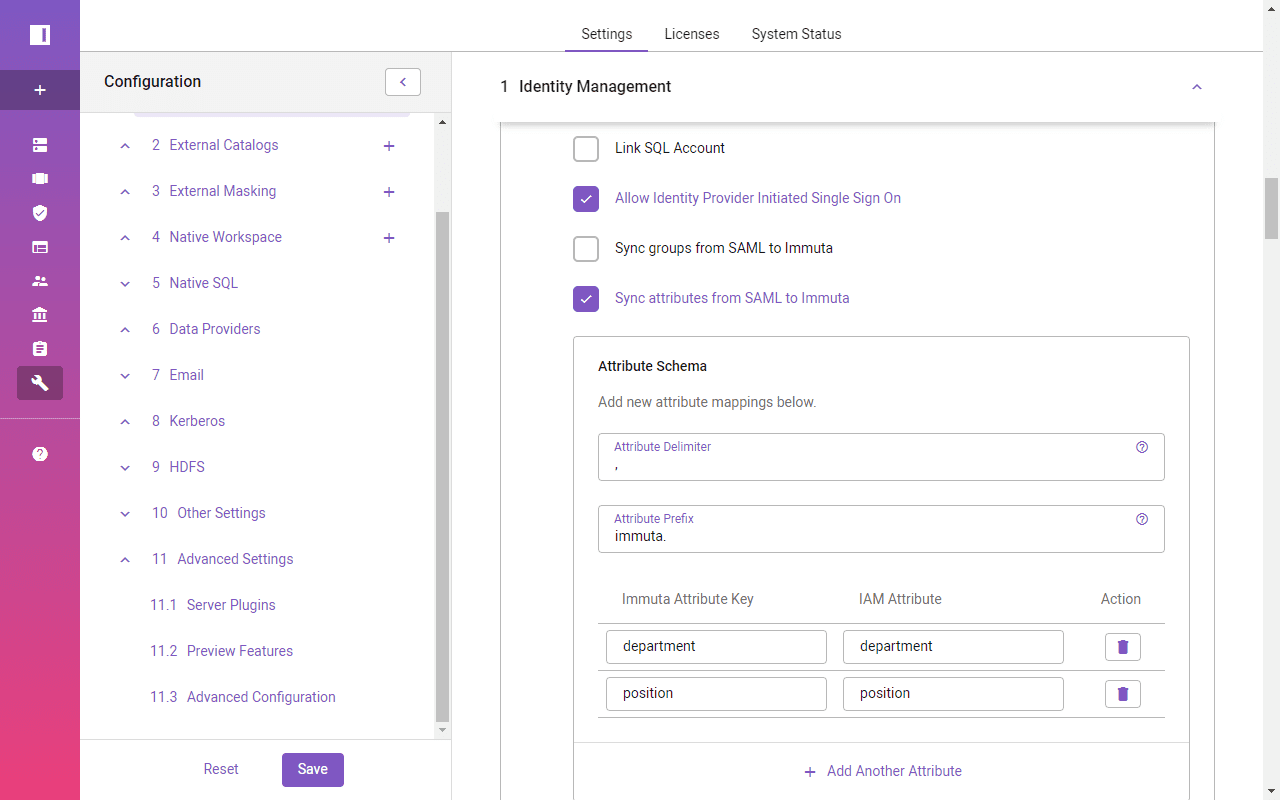
In the below profile, the user’s job title and department should be synced with Immuta. Department value will be used later to create a row-level access policy.
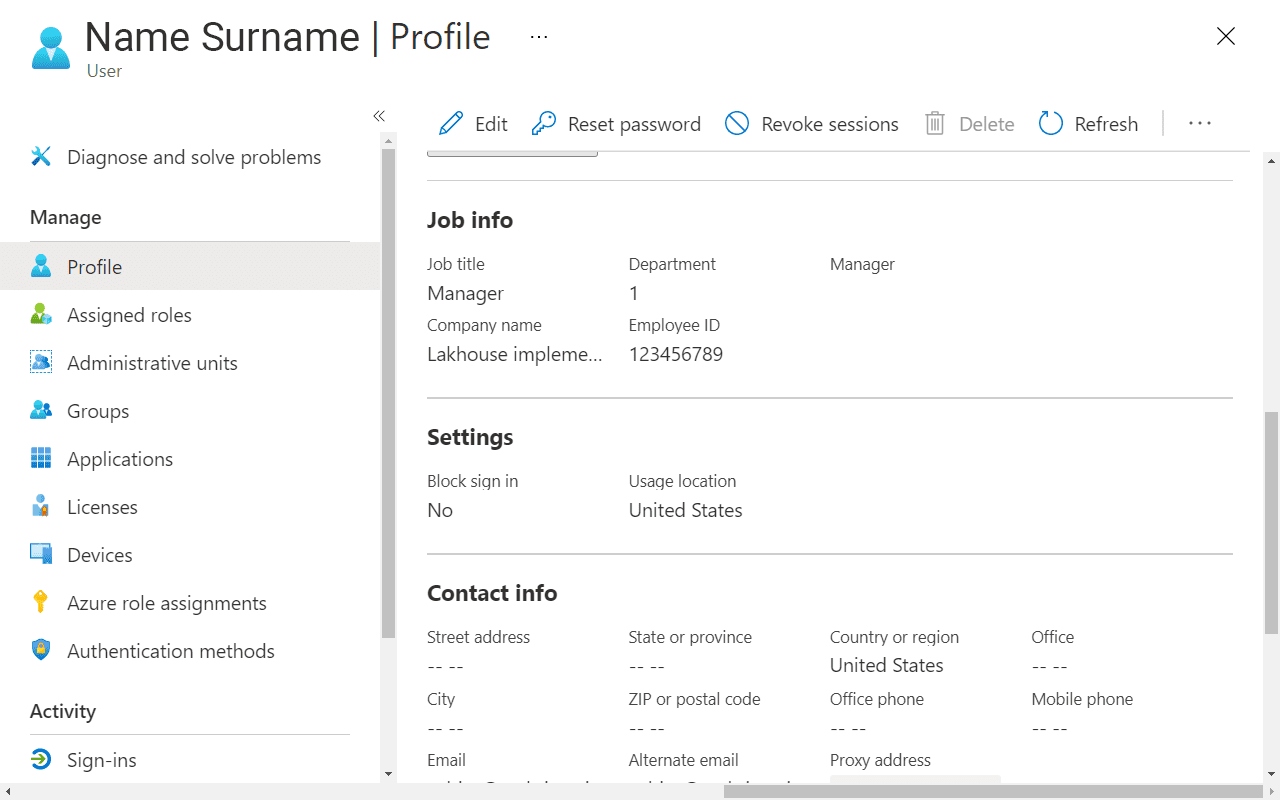
The same user attribute values should become visible in the user’s profile in Immuta. It’s important to remember that user attributes will be populated when users log in.
Register Azure Synapse and Databricks SQL Analytics
Immuta’s latest native SQL connectors for Azure Synapse and Databricks SQL Analytics enable end users to continue using the tool of their choice to access data. Immuta’s policies work even with native Azure Synapse or Databricks workspaces with no extra package installation required.
First you must register Azure Synapse and Databricks SQL Analytics instances in Immuta. The configuration is straightforward and requires inputting server names, database name, and credentials with proper accesses.
An automatic process creates an IMMUTA schema in Azure Synapse and immuta_sqlanalytics database/schema in Databricks SQL Analytics. End users will find their data under these objects.
Next, you add Azure Synapse and Databricks databases as data sources and allow Immuta to ingest required metadata.
Databricks and Azure Synapse Analytics tables will become visible in the Data Sources view. The next step is to configure data access policies.
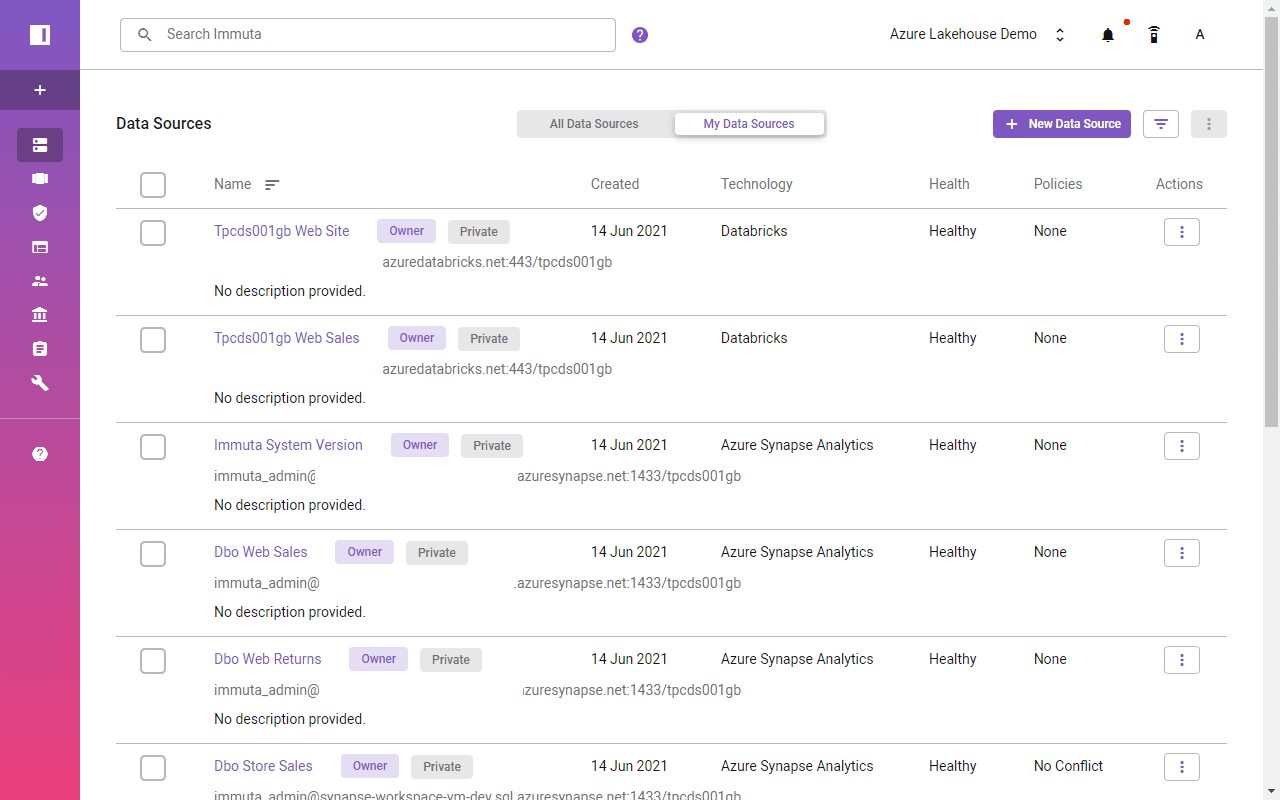
Enable Object-Level Access with Immuta
Registered Synapse data tables now have corresponding views under the IMMUTA schema. Similarly, the views in Databricks are in the immuta_sqlanalytics database. However, as no access was provided in Immuta yet, a user can’t see data.
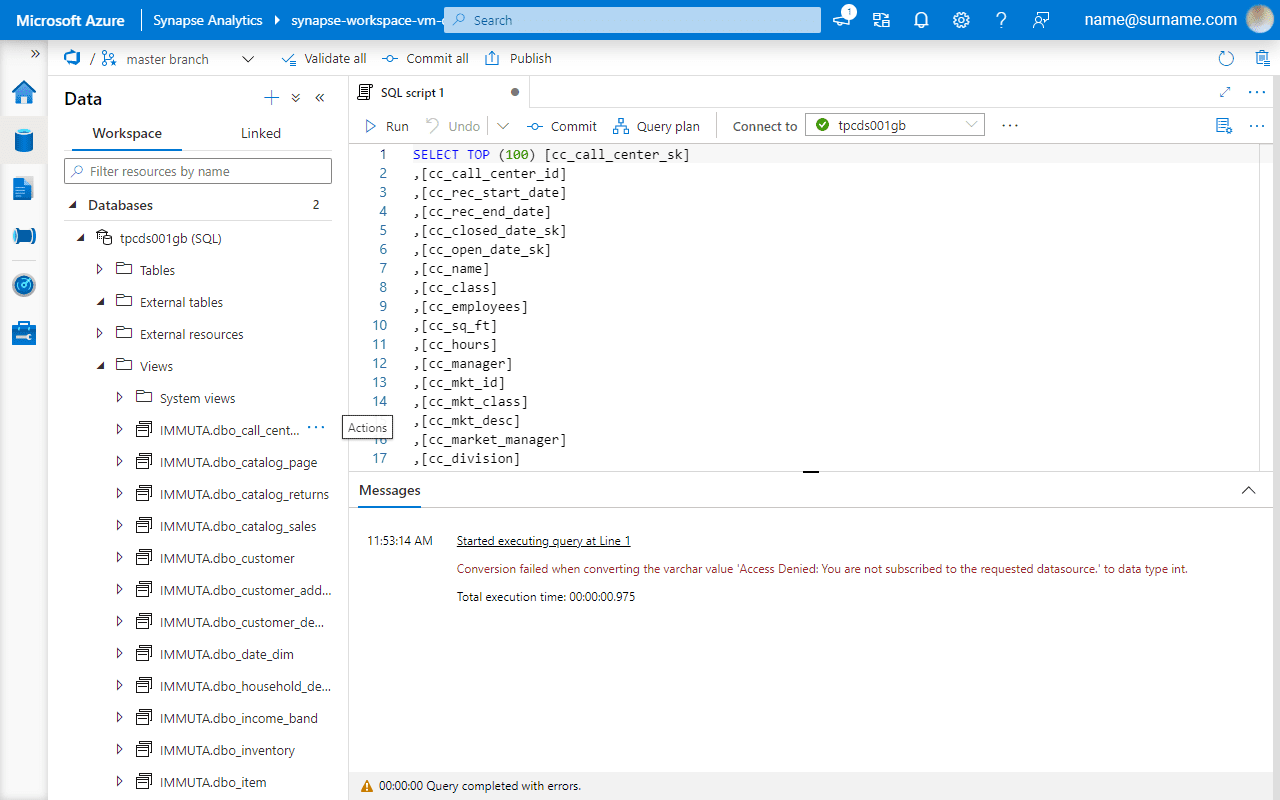
All tables by default have the most restricted policy enabled, so data source owners must manually add/remove users. This solves the simplest object-level requirement.
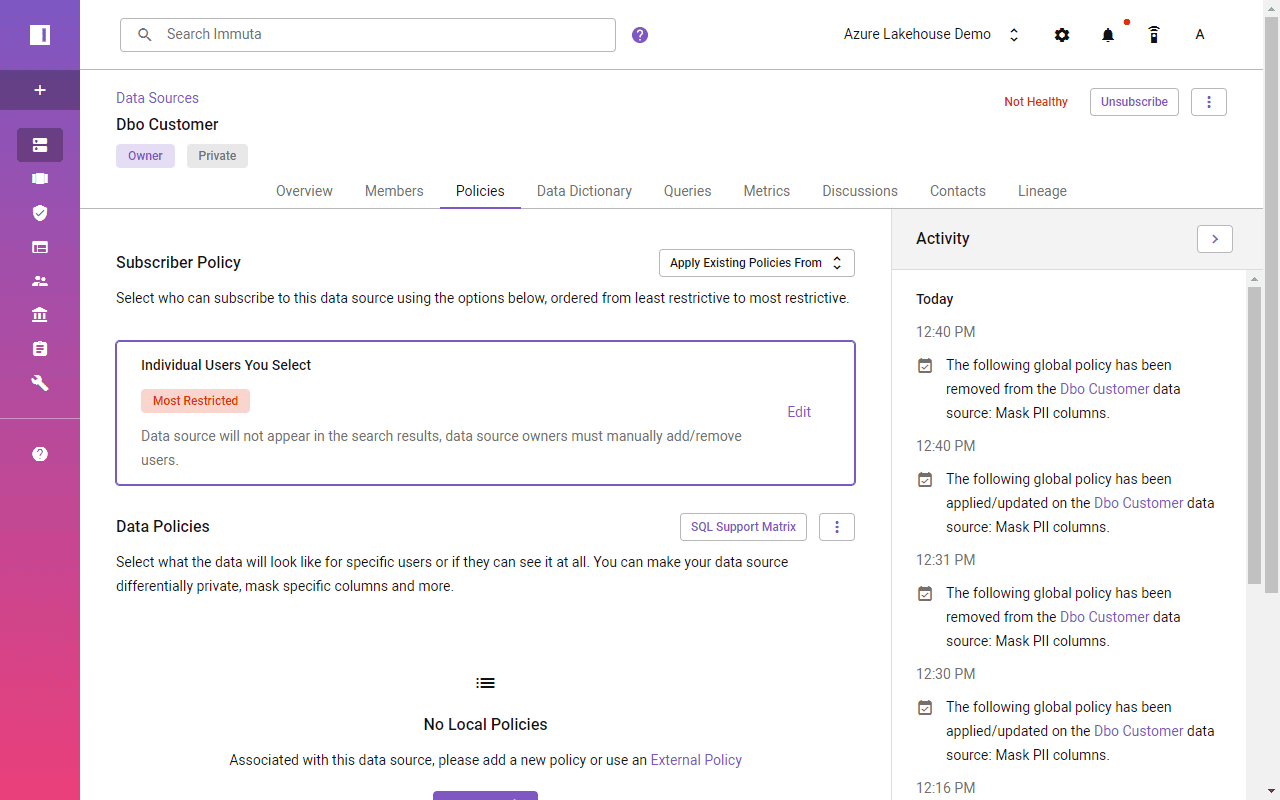
Enable Column-Level and Data Masking Implementation with Immuta
While Synapse and Databricks require a manual approach to identifying sensitive columns and creating dedicated functions and views, Immuta uses automated data classification and tagging with attribute-based access. Globally defined access policies across all data sources eliminate data access logic duplication.
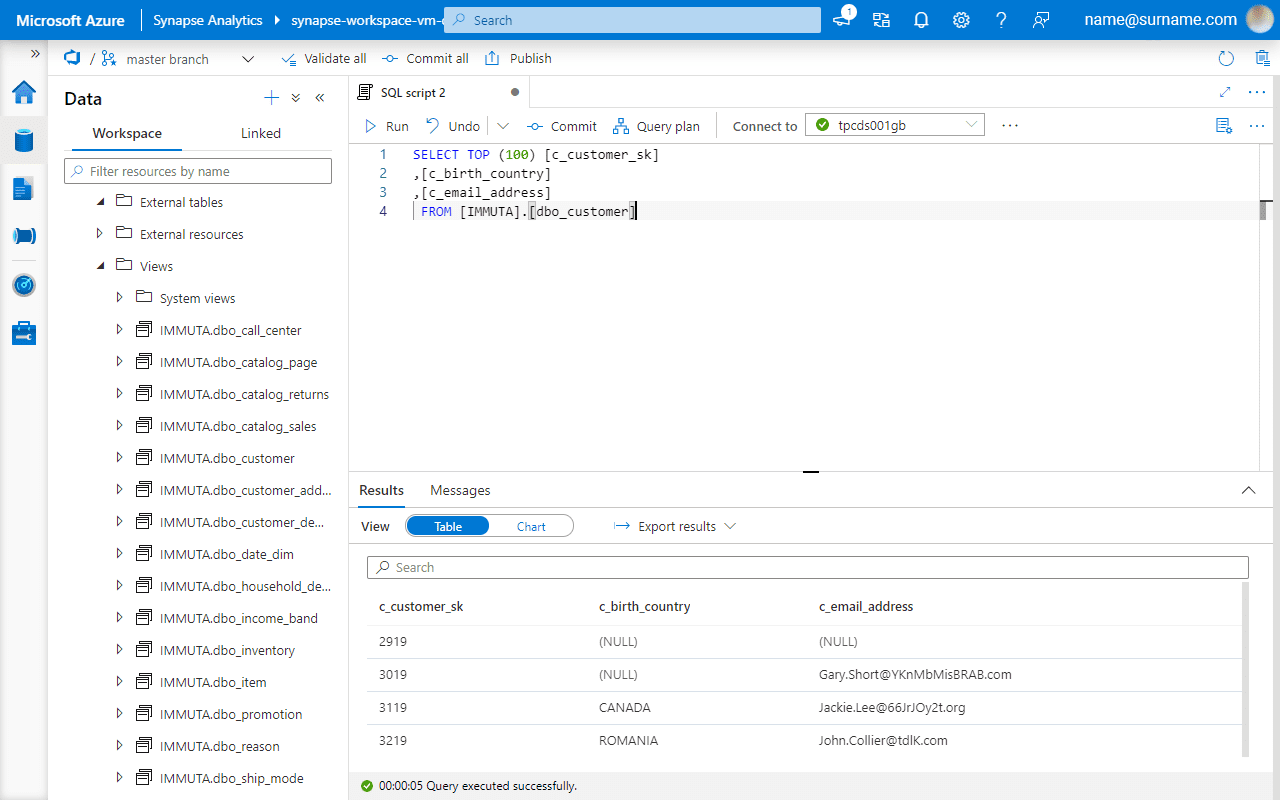
First, let’s verify if a sensitive email address column is visible before enabling a global PII masking policy.
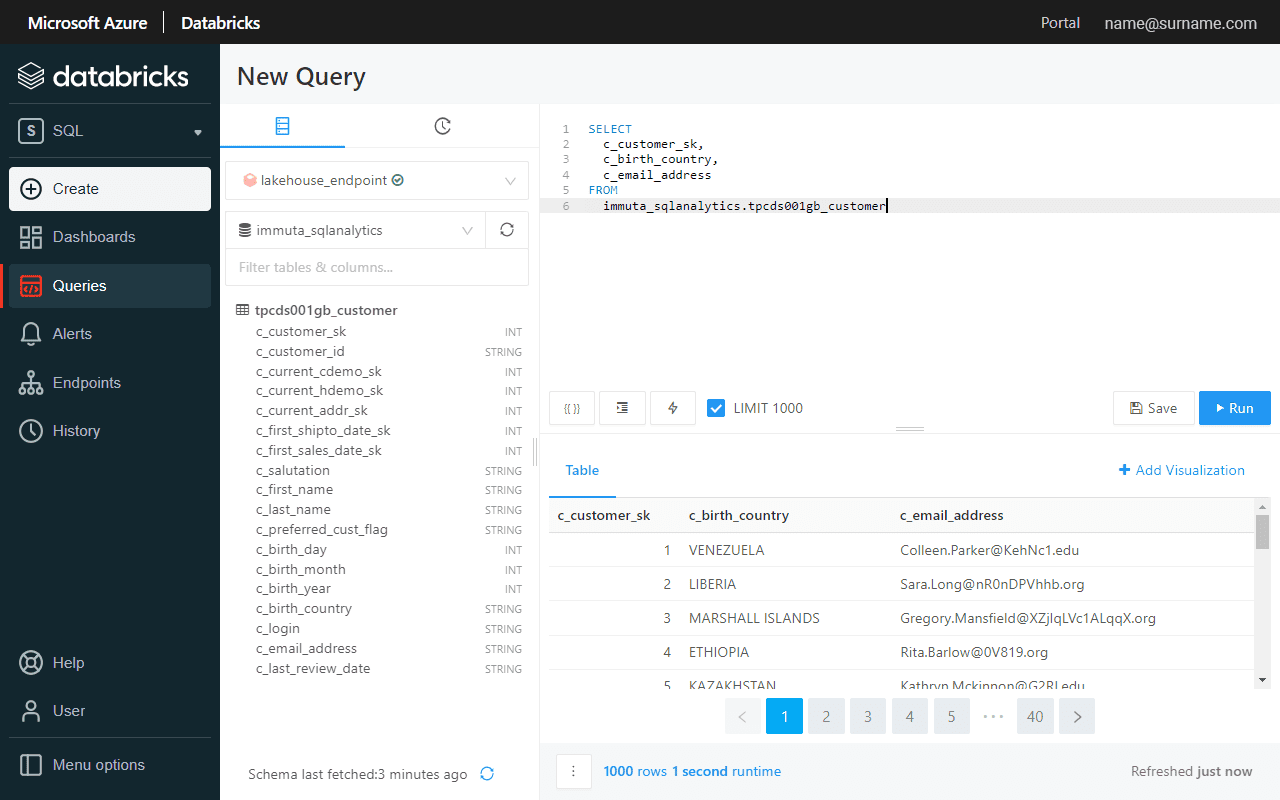
Databricks SQL Analytics and Azure Synapse return the same data for the customer table, and the email address remains unmasked.
Immuta identified FirstName, LastName, or Email columns as PII across all the data sources. Automated tagging enables the use of the global policy across all the data sources to mask any PII data for selected users.
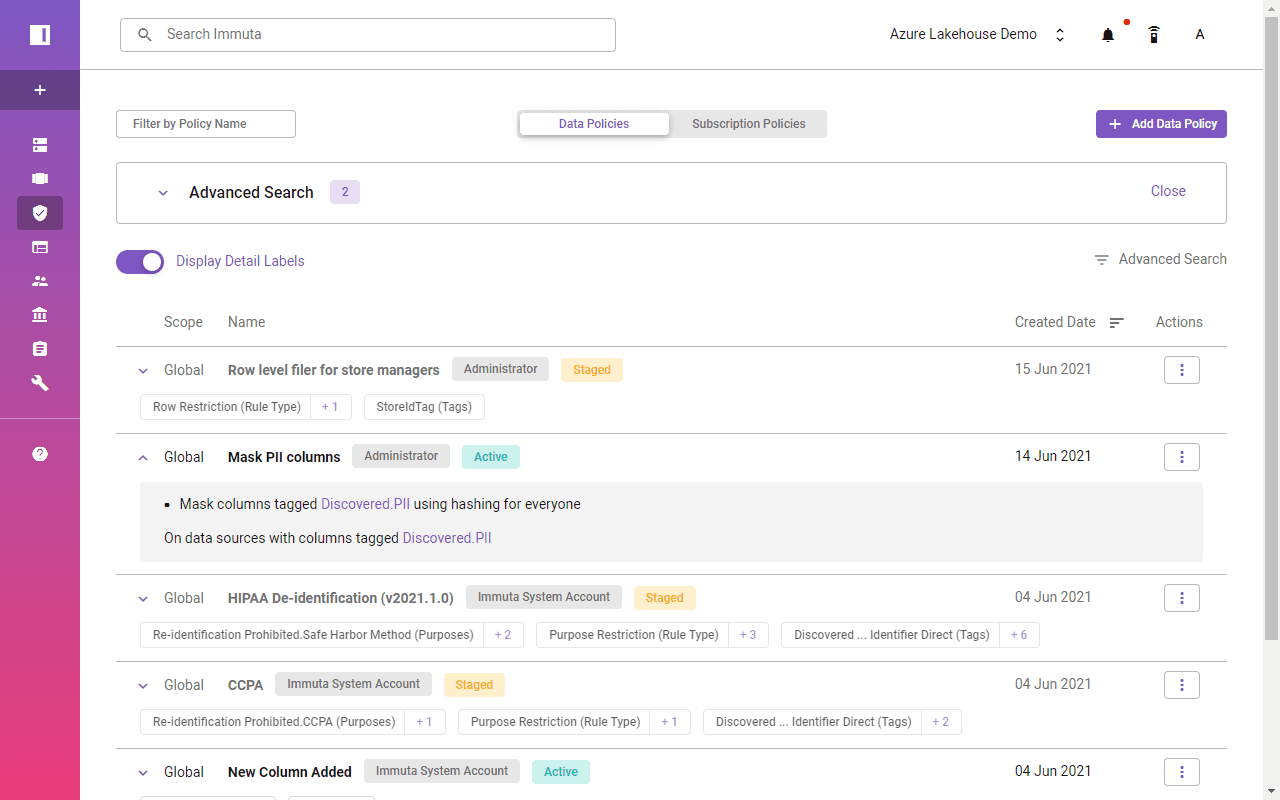
A single click turns on data masking across Azure Synapse and Databricks SQL Analytics. It’s a huge simplification, and at the same time enables more possibilities: The masking functionality and available scenarios with Immuta exceed Synapse’s and Databricks’ approaches.
Data now is masked directly in Databricks SQL Analytics and Azure Synapse portal, and consistently across both.
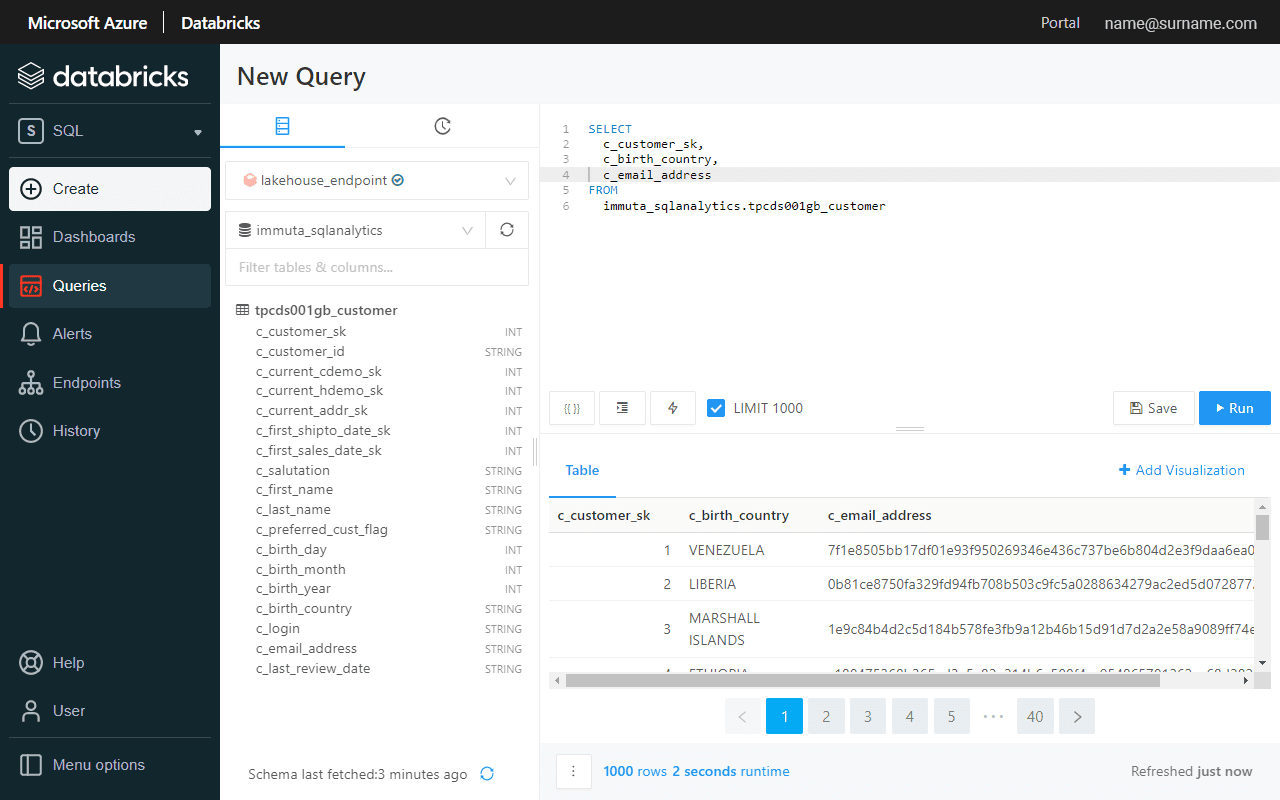
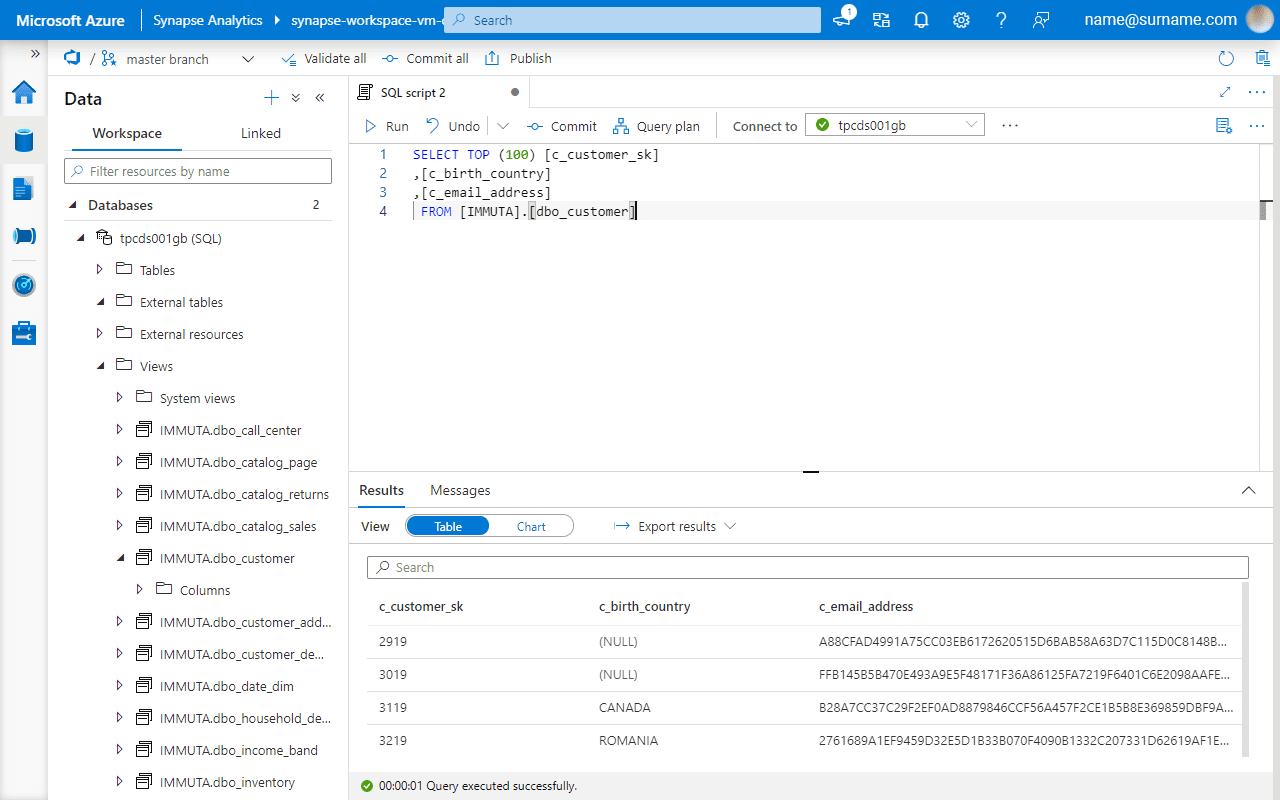
Enable Row-Level Access with Immuta
In a row-level access scenario, a retailer wants to share a data set of store performance, broken out by store. Earlier populated Active Directory user attributes will be used to limit accessible rows.
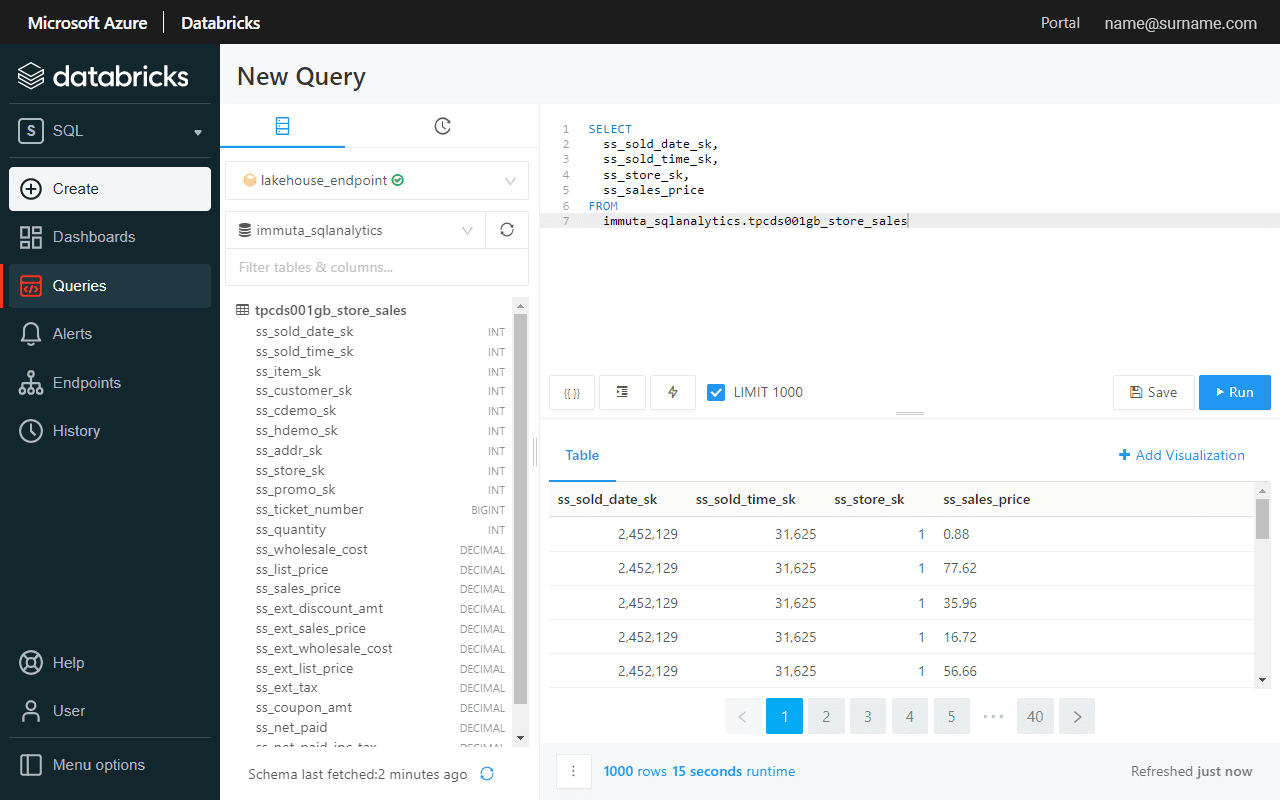
Before enabling Global PII row-level policy, let’s verify if the ss_store_sk column contains more than one value, which indicates that a user sees sales performance in all the stores.
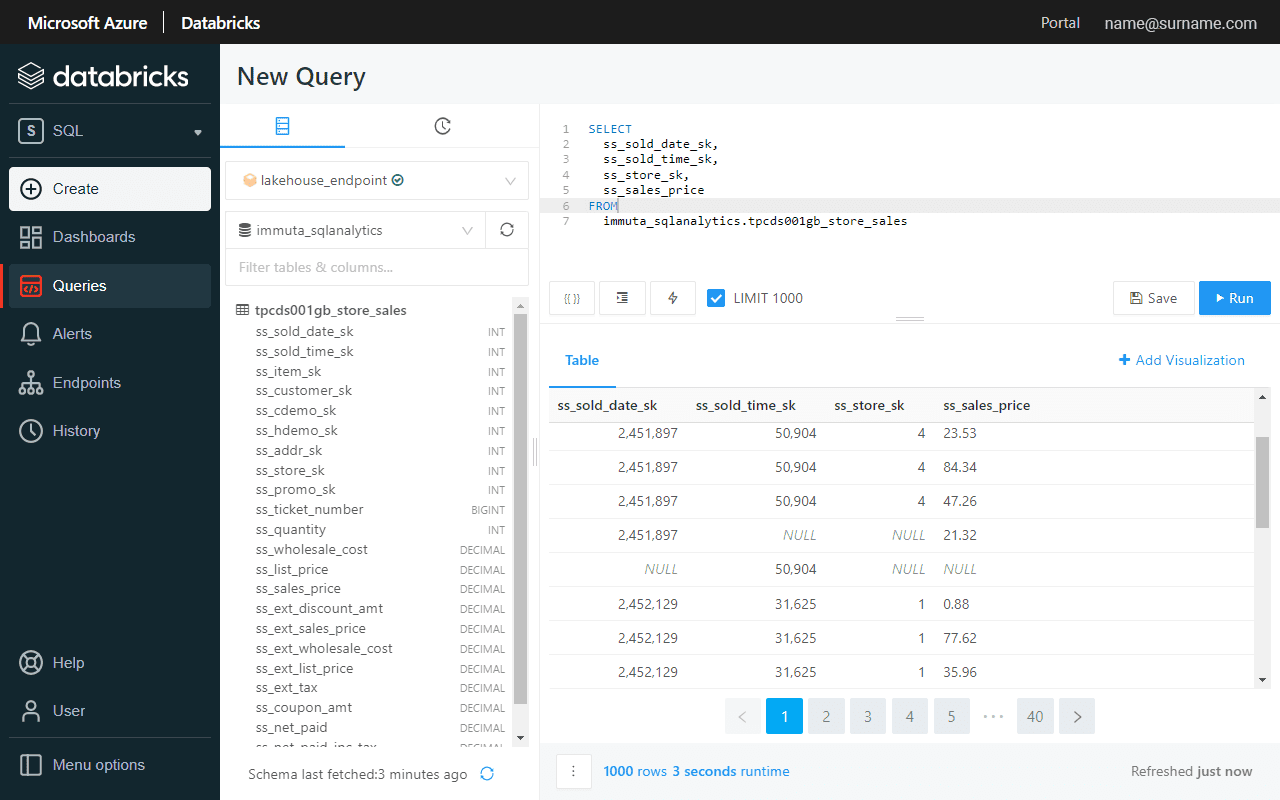
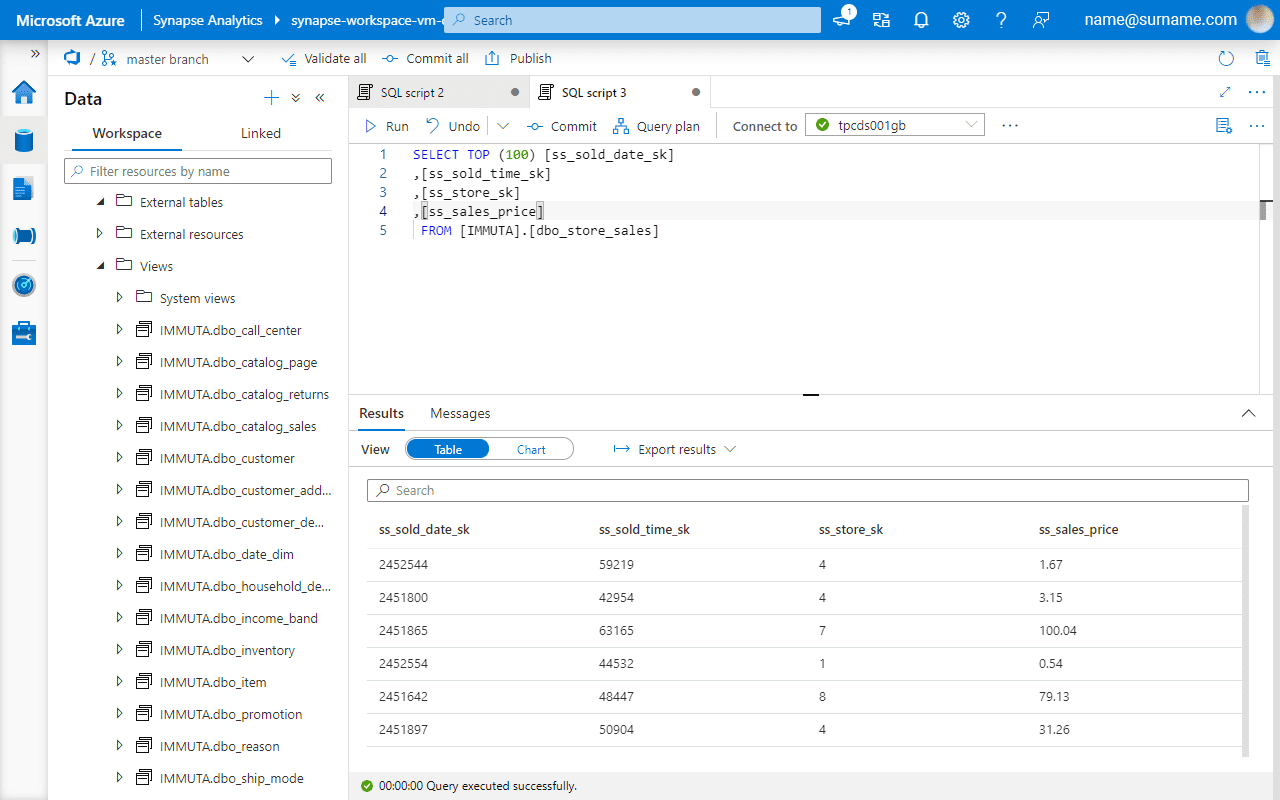
A global access policy defines filtering logic and links user attributes to column entries.
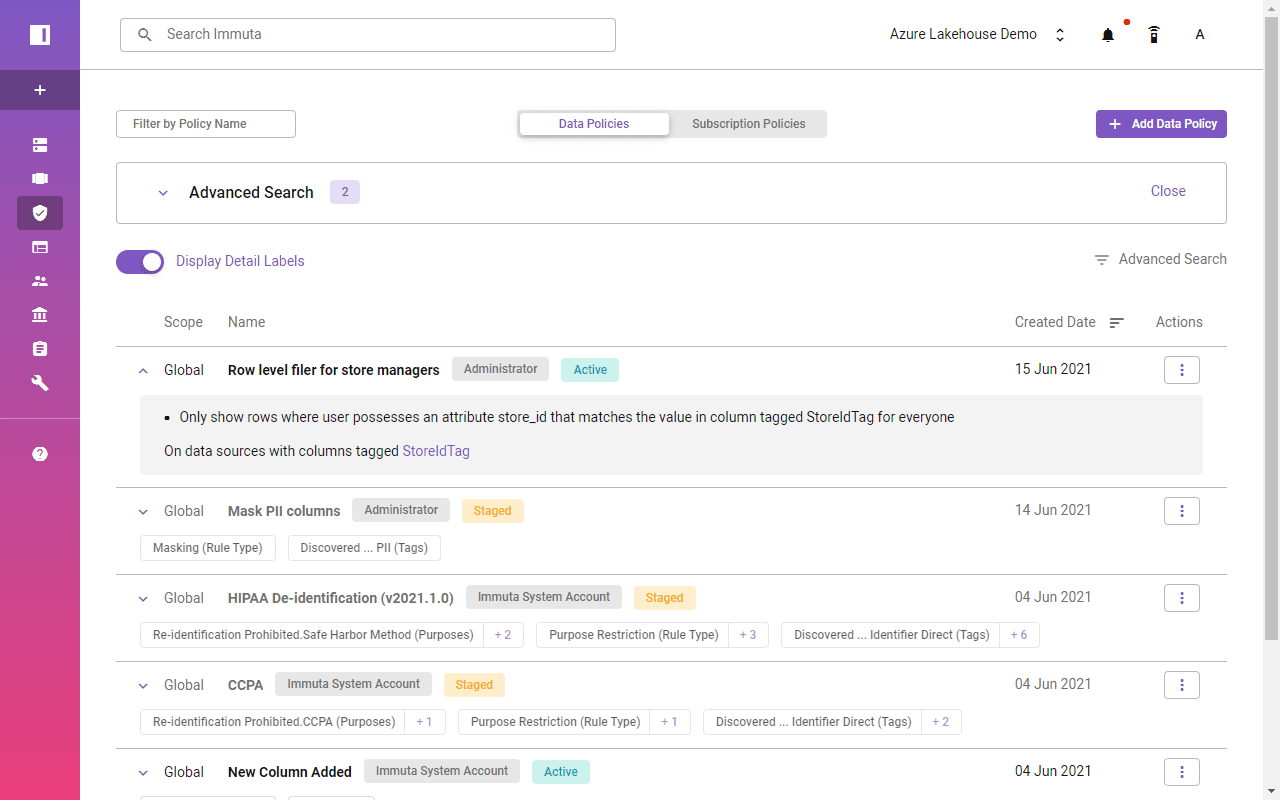
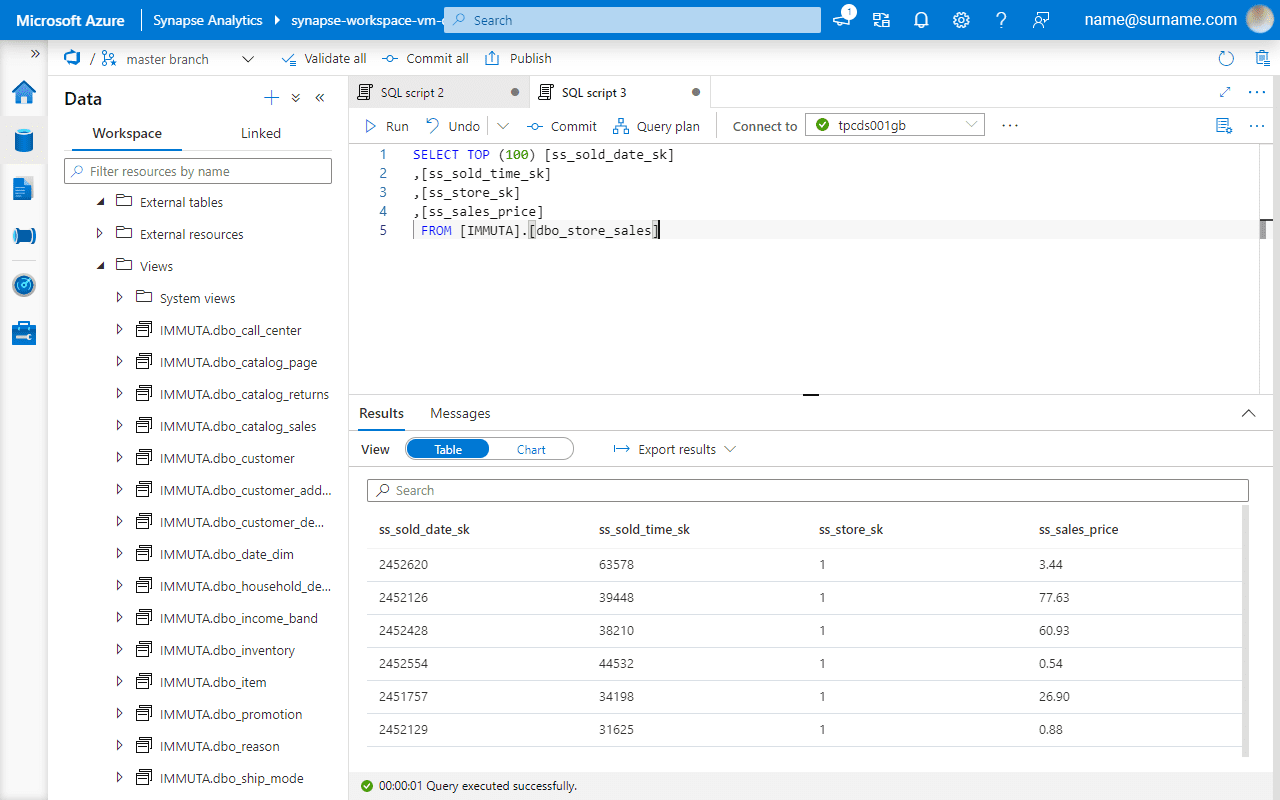
A single click enables a row-level filter across Azure Synapse and Databricks SQL.
Conclusion
Azure Synapse and Databricks engines combined with decoupled Azure Data Lake storage with Delta format enable Azure Lakehouse architecture. The setup unlocks scenarios ranging from data warehousing to advanced analytics use cases.
This article showcases the complexity of access management set up if done exclusively and independently in Azure Synapse and Databricks. Data duplication, access logic definitions in views, and lack of attribute-based access control might become a showstopper for companies trying to implement Azure Lakehouse data access control on an enterprise level.
The Immuta Data Security Platform provides a centralized access control capability for Azure Lakehouse implementations. Features like sensitive data discovery, security, and monitoring ensure compliance and data protection for companies of any size and industry.
To see Immuta in action, watch this 7-minute demo or request a live demo with our team.