
Are you using Apache Sentry on Cloudera to enforce data access control policies? Are you now looking to modernize by moving to Databricks for all the greatness it provides (nearly limitless scalability, cost savings through ephemeral compute, ACID transactions through Delta Lake)? You might be wondering how you can take all the hard work you’ve put into Sentry access controls and move it over to Databricks.
This article covers a migration strategy using Immuta’s platform, which automates Databricks access controls natively in Spark with a more powerful and scalable approach to managing policies.
Before diving into how to migrate these Databricks access controls, let’s examine how Sentry approaches access control.
Data Access Control with Sentry
Sentry allows you to enforce table- and column-level controls on your Impala/Hive tables. If you are reading this article, you undoubtedly understand most of this, but it’s important for us to level set on Sentry’s capabilities and limitations before we compare it to Immuta’s native enforcement capabilities in Databricks. Let’s review the controls provided by Sentry (table-, column-, and row-level), as well as usability and understandability:
Table Controls
- You can GRANT SELECT TO [ROLE] [roleName] on your tables.
- It can only be permissioned to ROLEs.
Column Controls
- You can GRANT SELECT(column_name) TO [ROLE] [roleName] on your tables.
- It can only be permissioned to ROLES.
- GRANT SELECT(column_name) will only allow you to select that column. If others are contained in your query, your query is completely blocked.
- Yes, this means you have to explicitly GRANT every column rather than REVOKE the columns you don’t want your users to see.
Row-Level Security
- The recommended way to enforce row-level security in Sentry is by creating views and only providing access to those views, instead of the table from which they were created.
Usability / Understandability
- These controls are only for Hive/Impala and do not control access lower than table-level in Spark (no column- or row-level security in Spark).
- There is a minimalist HUE user interface for authoring policies, which is very difficult to use properly and because of that, it is actually easier to use the command line in Hive or Impala shell to build the policies.
- Sentry provides no way other than command line to view the policies that are currently being enforced on tables. This looked to be possible in the HUE interface, but unfortunately the shell was easier. Sentry also does not provide any data auditing or reporting capability based on actions being taken in the system.
Now armed with a solid understanding of Sentry (and in particular, its limitations), we’ll now explore Immuta and its fine-grained access controls and privacy controls, before diving into the actual migration strategy.
Data Access Control with Immuta
The Immuta Data Access platform delivers automated security and privacy controls to safely analyze and protect sensitive data at scale. Immuta provides a direct mapping to the Sentry controls we just reviewed, with significant improvements required to scale data access controls for modern data platforms. With Immuta, policies can be enforced natively in Databricks Spark and through interactive Databricks SQL against Azure Data Lake (gen1 or 2), S3-backed tables, or even Delta tables.
Table Controls
- You can GRANT based on the direct user, an attribute the user possesses, or the group to which they belong.
- You can initialize approval flows for access to tables.
- “Subscriptions” to tables can have an expiration date.
Column Controls
- Column controls include advanced dynamic data masking techniques. As a result, column access is no longer a binary decision (i.e. do you have access or not). Data within columns can be “fuzzed,” allowing some level of utility from the column while protecting the sensitive information it contains. Immuta can mask using:
- Hashing (with a secret salt)
- Encryption
- Format preserving encryption
- Rounding/data generalization
- Regular expression
- K-anonymization
- Differential privacy
- Local differential privacy (randomized response)
- Replacing with null or a constant
- Masking policies are enforced using the principle of least privilege access; applying them to all users; and then setting exceptions based on an attribute the user possesses, the group they belong to, or even what the user is doing (their purpose). This aligns well with Sentry’s GRANT-based mechanism without the headache of GRANTing one column at a time.
Row-Level Security
- Immuta can enforce row-level security natively in Spark and interactive Databricks SQL without the need to create views.
Usability / Understandability
- Unlike Sentry, Immuta also has the compliance and legal users in mind rather than just the database administrator and analysts. Through the plain language representation of the policies, teams of analysts and compliance professionals have complete visibility into how policies are actually being enforced.
- Immuta also provides a report generation tool, allowing data teams to quickly generate common reports for compliance teams based on the Immuta audit logs, rather than having to rely on manual processes to comb the audit logs.
Migrating from Sentry on Cloudera to Immuta
Now that you’re fully armed with an understanding of Immuta and Sentry – and how they differ – let’s explore considerations for migrating from Sentry to Immuta on Databricks.
Role Mapping
For initial setup, you will take the roles that are granted access to the tables/columns in Sentry and represent those as groups in the identity management system you are using for Databricks. Alternatively, you can map those roles to group attributes in Immuta, without the need to add any additional groups in your identity management system.
Migrating Table Controls
To migrate table controls, you would create Immuta subscription policies on the tables mapping to those roles similar to how you would with Sentry. There are two key things to keep in mind here:
- It is possible to build a policy once and have it apply to many tables at once using logical tags on tables. This will reduce your work significantly and improve scalability when you need to make a batch change.
- You will not have to worry about protecting views you previously had to create for row-level security. In fact, you will not have to create those views at all (see the Migrating Row-Level Security section for more detail).
Migrating Column Controls
To migrate column controls, you would invert all column grants as exceptions to Immuta masking policies. Let’s take the following GRANT as an example:
With Immuta, you could represent this GRANT using a cleaner and much easier to understand masking policy, whereby you mask by making it null for everyone except Billing (Note: you would also want to include any roles that have full access to the table in that exception along with Billing):

As mentioned with table controls, it is possible to build policy at the logical tag level, which allows you to write this policy once and apply it across all relevant tables with the credit card number tag:
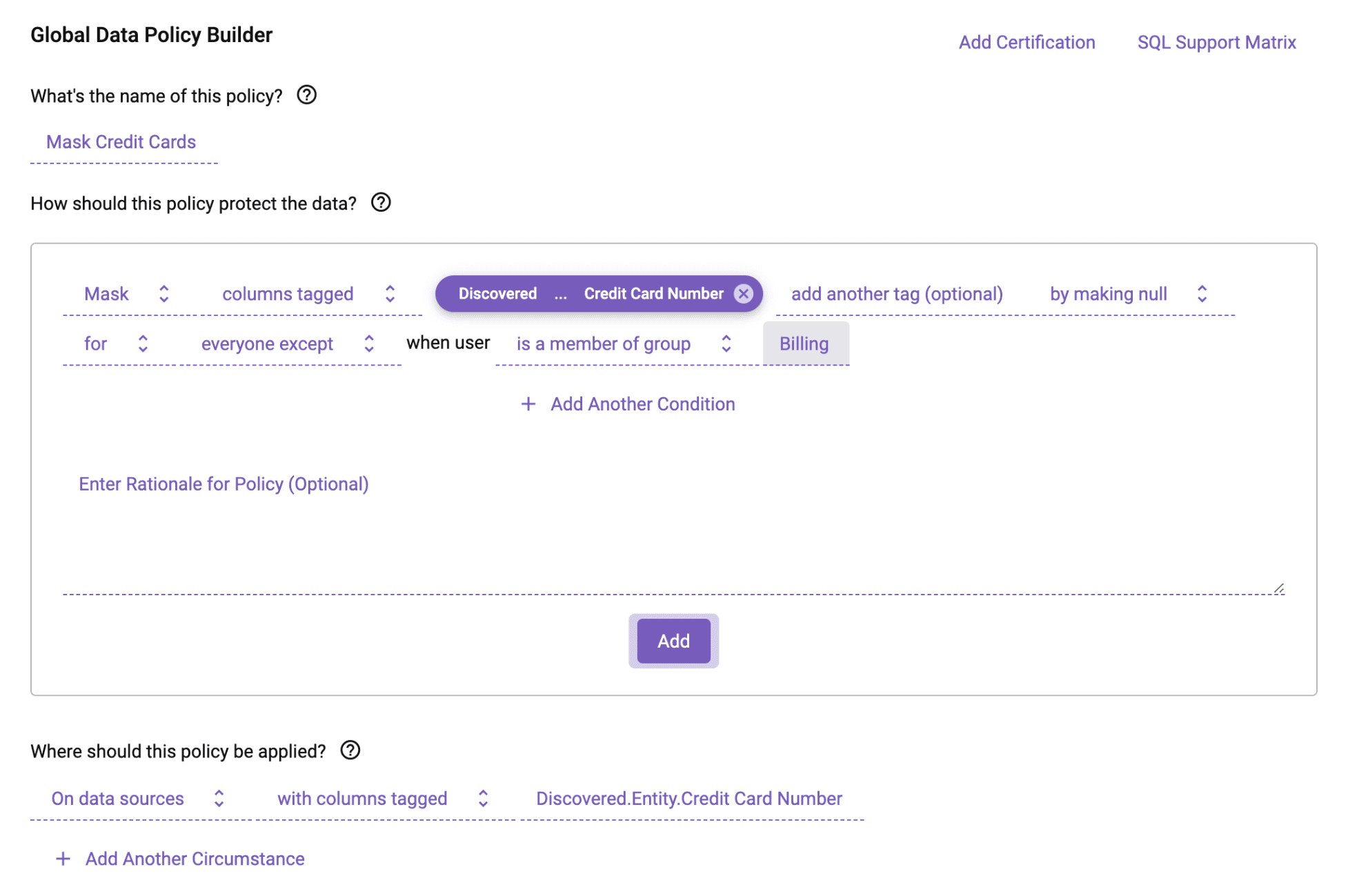
Also remember that you don’t have to null out the column. Instead, you could use one of Immuta’s advanced dynamic data masking techniques, such as a regular expression, that removes the last 5 digits of the credit card number.
Migrating Row-Level Security
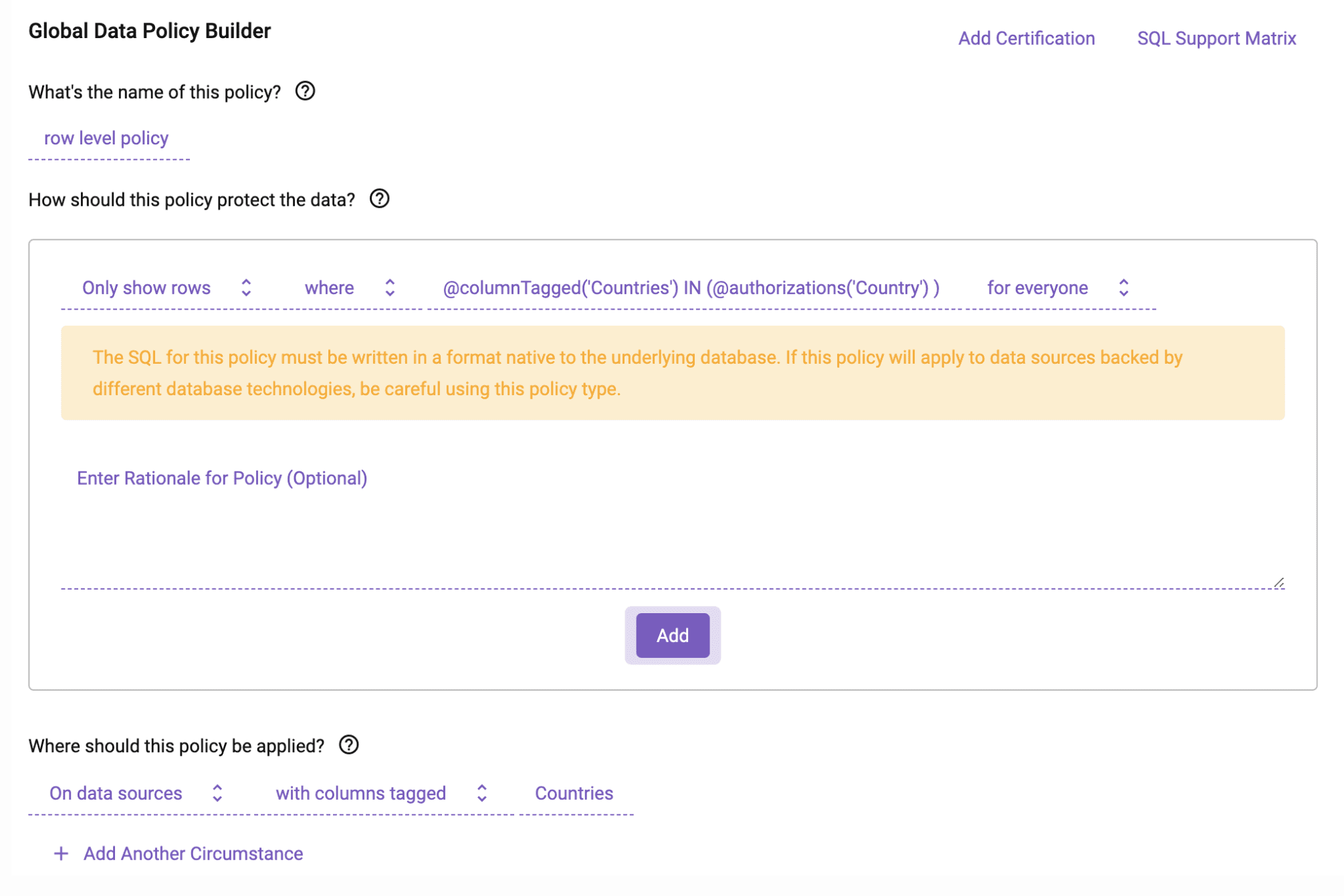
Since Immuta can enforce row-level security natively in Spark and interactive Databricks SQL, there is no need to migrate the views you created to enforce row-level security; you only need the original tables in Databricks.
Using that single table, you are able to dynamically inject user attributes or groups as variables to enforce policy. For example, we are comparing the user’s country to the column transaction_country, and if there’s a match, that row will remain. If not, it will be redacted:

These policies would map to the WHERE clauses used to create your views and the roles that were granted access to those views using Sentry. You can even apply complex WHERE clauses that include variables as dynamic user attributes to drive the policy, which can be applied across many tables at once using logical tags:
What’s Next?
If you want to learn more about Immuta, please start by requesting a demo.