If Disney World were a database, we would rave about its access control strategy. It is secure: only authorized users get into the park or into any sensitive backstage areas. It is dynamic: many rides and concessions are available to the right people with the wave of a bracelet. Most importantly, its strategies blend seamlessly in with other tactics to support the overall user experience. Hidden complexity and rigorous controls enable the free movement and delight of tens of thousands of consumers.
It’s not a far-fetched comparison. Major cloud platforms are beginning to resemble data amusement parks more and more, but the security challenge remains as daunting as ever. And, despite many of them offering advanced functionality – dynamic dynamic masking, automated data classification, increasingly configurable roles – it’s still a major challenge to piece everything together into a holistic approach to data access control that is empowering to end users.
In this post, we’ll share the Immuta data team’s three-pronged internal strategy for Snowflake fine-grained access control, and resource and user management when coupled with an Immuta policy engine.
- Create an open discoverability space with sanitized data for all employees
- Provision roles on request to enable custom project schemas
- Enforce strict controls over the raw data assets
Together with the policies enforced by Immuta, this strategy allows the data team to open up our Snowflake platform without concerns about leaking sensitive data to our end users.
Going PUBLIC for a Better User Experience
A hypothesis: There is no intrinsic consumer demand for “analytics,” “marketing,” and “executive” roles in your data platform. The data consumer’s priority is to get access to useful data that will bring them value, and roles are something they (and data platform owners) have to live with because, well, that’s just how it’s done.
The alternative is to drive access to data assets based on user attributes (which includes, but is not limited to, groups and roles). User-focused access controls take the role concept to its limits: the user profile is its own role, and complex access decisions can be based on one or more of that user’s properties.
With Immuta, each user in the PUBLIC role has personalized access to each table, down to the cell level. This dramatically simplifies both the platform owner’s administrative burden and the end user’s experience. It also unlocks many more possibilities for differentiating user access or protecting sensitive data.
The diagram below shows how this works to centralize and implement fine-grained access control in Snowflake.
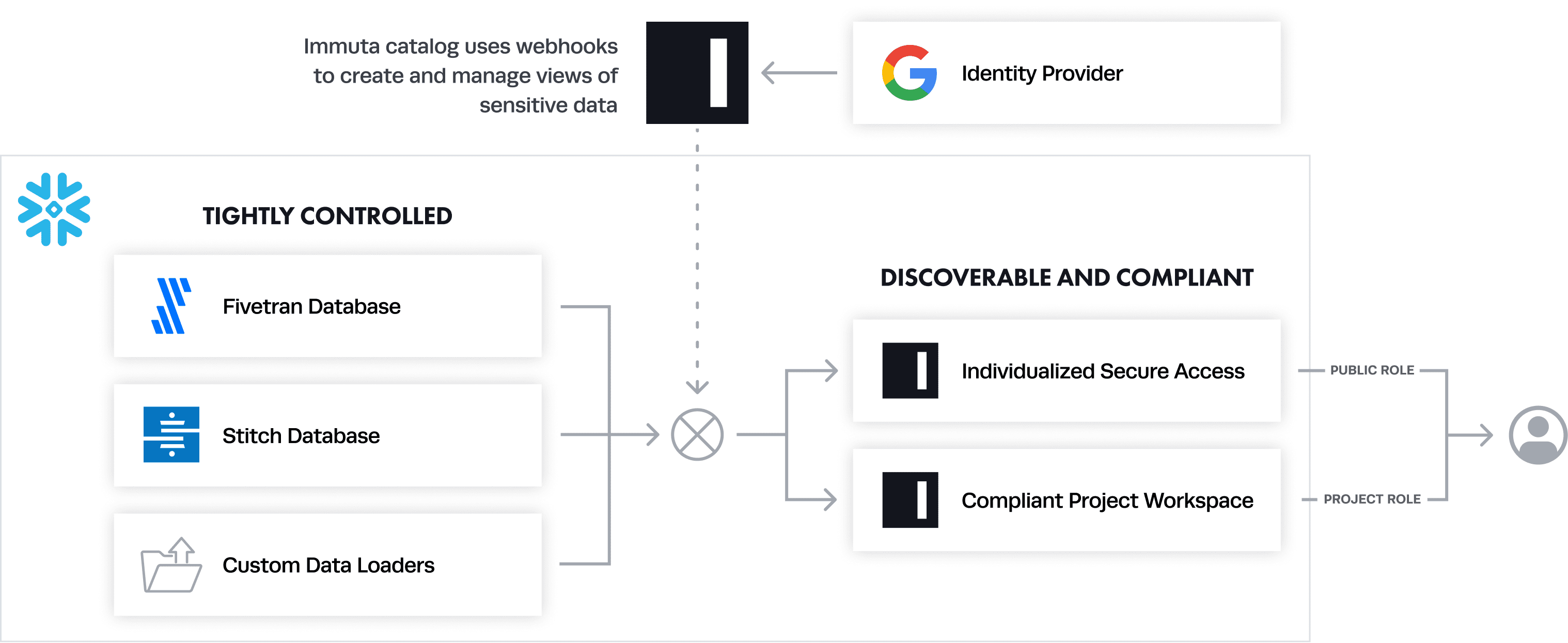
The flexibility arises because Immuta separates the data access control decision (what data should be released?) from the specific database objects (who is querying what data?). This presents a few advantages:
- Policies can be layered on, rather than baked in. If you want to start masking user names, you don’t have to create a specific new policy for all the affected tables.
- Exceptions can be dealt with as they arise, rather than planned out ahead of time. For example, a decision may be that users should only have access to the last year of Salesforce data, except for the analytics team. A second policy can be easily layered on to minimize access, even long after the data set is made “golden.”
Focusing efforts on building out this common access area with the appropriate protections brings clarity to what data needs to be protected, why, and for whom.
Securing Backstage Access for Snowflake Fine-Grained Access Control
Despite these advantages, you can’t protect what you don’t know. At the same time that we create a trusted space for consumers, we also create a protected space for the raw data. This separation of concerns enables us to trust our security, even when data becomes “truly sensitive.”
We follow a three step onboarding process at Immuta:
- Onboard the data into its own database with tightly controlled credentials. For example, data synced by Fivetran would live in its own database, while custom data loads would exist separately. At Immuta, we create these databases with Terraform and only allow our core data engineers access to their credentials.
- Classify the data with the internal metadata framework. If the data has personal or privileged information, we need to capture and record it so that metadata-driven protections can later be applied. We use dbt to record this information.
- Register the data with Immuta to create policy-compliant views in Snowflake. Finally, we register it with Immuta, which will automatically apply policies once the associated metadata is also uploaded. In most cases, this will happen automatically.
We’ve recently made Snowflake data governance easier to implement, with the ability to manage row access policies, column masking policies, object tagging, and classification directly on Snowflake tables, without using views. Policies can now be managed directly on Snowflake, leveraging all native controls within it. Furthermore, Immuta admins can create global policies and add Snowflake users without going into Immuta. Ultimately, since Immuta is made invisible for the average user, teams are able to benefit from performance and usability improvements thanks to row-level security caching.
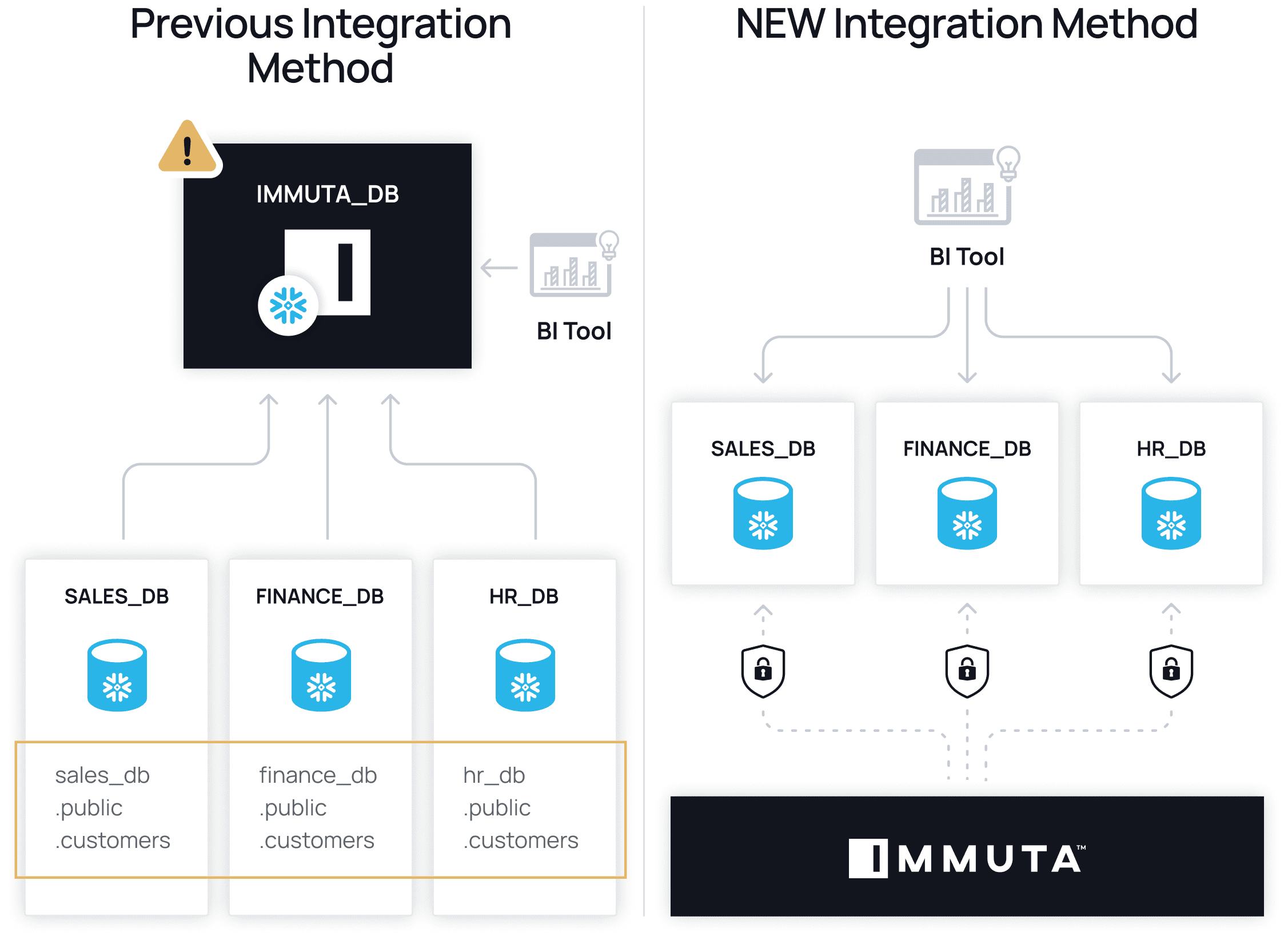
All “production” data access, even by transformation tools, will be done after access controls are implemented in Immuta. This ensures a hard isolation of the raw data assets and also enables changes to propagate through downstream pipelines, such as dbt workflows.
Creating Roles for a Reason
So far, we’ve discussed two types of roles: a general consumption role (PUBLIC) and a set of engineering-only roles for raw data ingestion. But there are many times when baseline policies don’t match the requirements of the business. This is the perfect use case for a third kind: the project role.
In Immuta, Projects can be thought of as dynamic schemas with their own unique user base and policy logic. They are very useful for organizing data or creating data clean rooms that can be shared more broadly. Some example use cases for projects include:
- Creating a temporary development space for a data scientist who wants to try doing some custom modelling with a data science tool like Dataiku
- Scoping access control permissions to a data unloading tool, such as Census, so that not all users have access to all data and it can be revoked by administrators
- Creating an isolated connection string for a BI tool, such as Looker, to provide elevated permissions to sensitive data assets
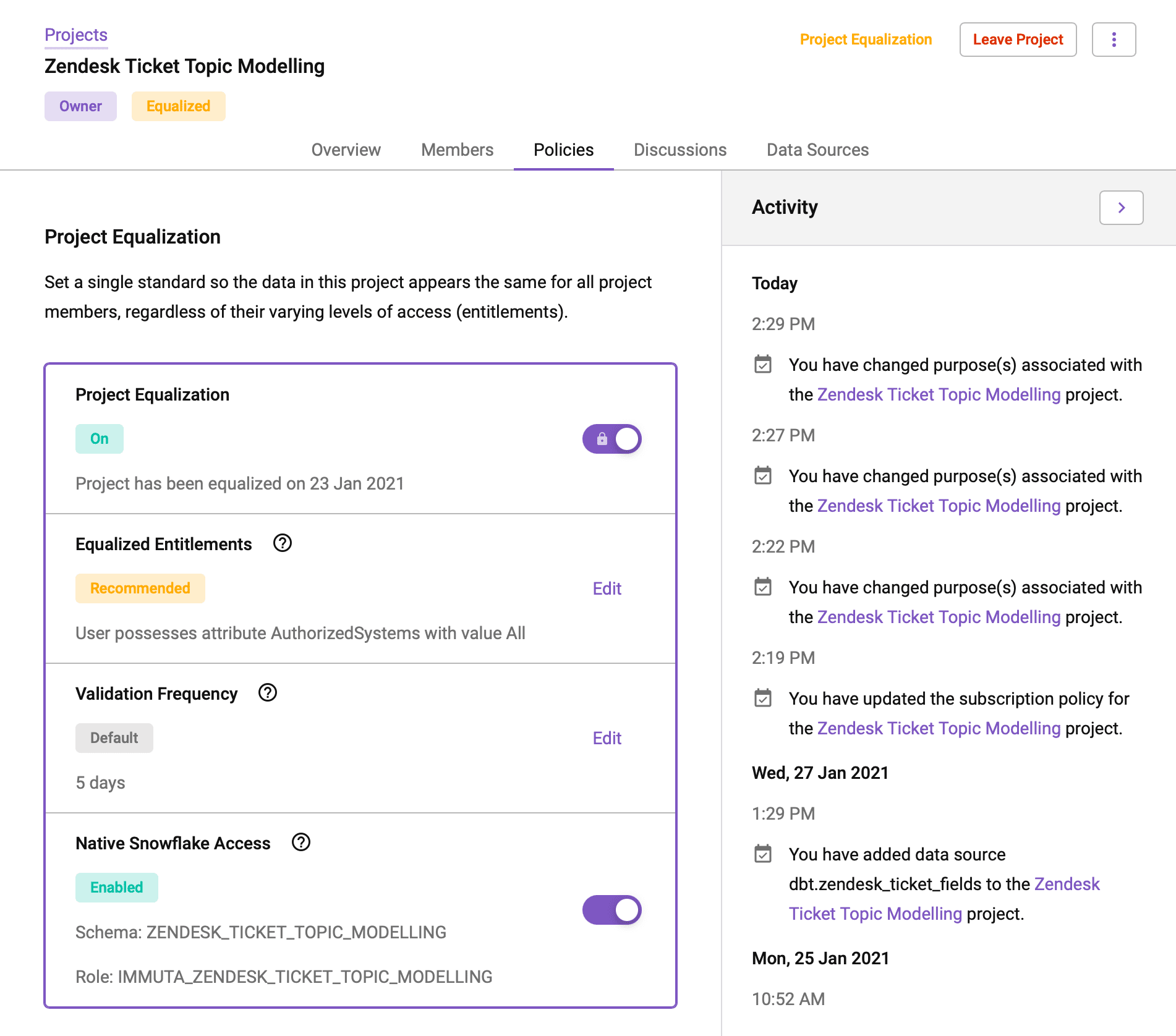
Each Immuta project can generate a Snowflake schema and role, which can then be granted to other users. Access policies can also be repealed in a project context. For example, a certain use case may require unmasked access to personal data.
The “baseline policy” pattern, combined with an as-needed project workflow, enables a highly evolvable data platform with respect to policy enforcement. Rather than trying to build a role structure that won’t last through next month’s re-organization, our team is able to write a policy that effectively implements access controls and can be updated on an as-needed basis.
Conclusion
By creating a safe general space and focusing protection on entry points and privileged areas, an amusement park enables the free movement and activity of its attendees. In the same way, the approach we have implemented on Immuta’s data team enables the safe exposure of all of our data assets, without solidifying today’s governance decisions in the data model. Although our policies are certain to evolve – we may start masking this type of data, or restrict access to those types of sources – we will not have to re-architect the database or review a cadre of roles: all that will need to change is the relevant metadata and global policies.