
Have you been on Cloudera or Hortonworks using tools like Apache Sentry and Apache Ranger to build data access control policies? Are you now looking to modernize and move to Databricks for all the greatness it provides (nearly limitless scalability, cost savings through ephemeral compute, ACID transactions through Delta Lake)? You might be wondering how you can take all the hard work you’ve put into Ranger access controls and move them over to Databricks.
Immuta is here to help.
Why Migrate from Apache Ranger on Databricks to Immuta?
Many of our customers ask, “Can you just take my Ranger policies as-is and enforce them in Databricks?” And we always advise against this approach. Just like you’re modernizing data analytics with your move to Databricks, you want to modernize how you handle policies in order to scale user adoption in sensitive data environments.
Let me explain why.
As an example, we’ve enabled a customer with 122 different Ranger masking and row-level policies to boil that list down to two – yes, two – policies in Immuta. An independent study by GigaOm also found that Immuta requires 75x fewer policy changes than Ranger, resulting in an estimated ROI of $300,000.
How is that possible? There are four reasons:
- Attribute-based access control (ABAC). Ranger and Sentry are role-based access control models (RBAC), while Immuta follows the attribute-based access control (ABAC) model. This provides scalability, and I’ll explain how shortly.
- Building policy at the logical layer rather than the physical layer. While it is possible to build Ranger policies via tags, which is similar, there are major limitations to this method.
- Exception-based policy authoring. Immuta follows the principle of least privilege access by specifying who should be “let in” rather than who should be “kept out.” We’ll learn more in the masking policy section.
- Simplicity and visibility. With Immuta, it is much more intuitive to build policies and easier for everyone across the organization to understand how policies are actually being enforced.
Let’s dive in. I’ll use real but sanitized versions of that customer’s policies to demonstrate the power of ABAC, building policies at the logical layer, and exception-based authoring while displaying the intuition of Immuta’s powerful interface.
Policy 1: Contrast Ranger Row-Level Filtering with Immuta
In this scenario, we have two separate tables. One is a lookup table for product lines associated with different customers. A good way to picture this is if you had several customers that all purchased different data products (product lines) you offer. The table would look like this:
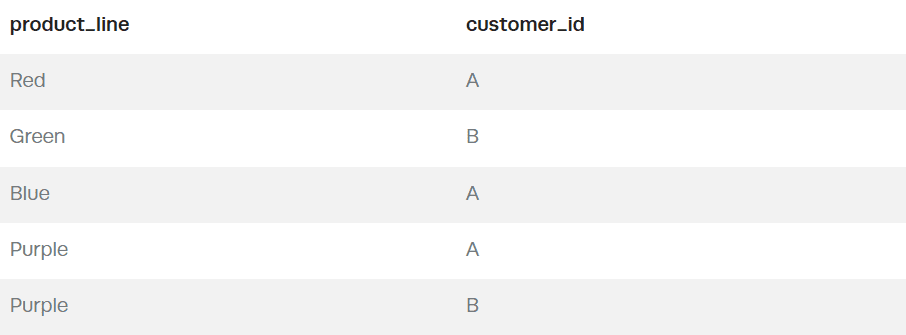
In this table, A has purchased the Red and Blue product lines, and B has purchased Green, whereas both A and B have purchased Purple.
Our second table is the actual data that needs the row filtering:

What’s in the columns doesn’t really matter. What matters is the need to filter the data by Product Line. However, a problem emerges – we only know the customer_id associated with each user in the system, not their product_line, so we must leverage that lookup table to map user → customer_id → product_line → row-level policy.
Row-Level Filtering Policies with Ranger
To do that with Ranger, we need to build a policy for each unique set of users in our system, where the customer_id is hard coded as part of the WHERE clause:
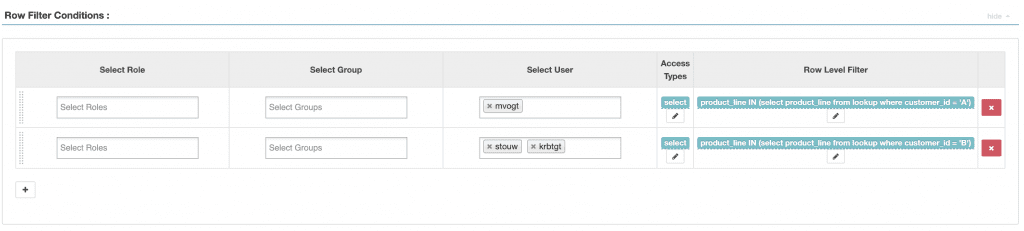
So yes, you are going to need a row-level policy for every customer_id-to-user combination that exists in your data. This is because you are not able to treat your users and their attributes as variables in the policy. In other words, in a Ranger/RBAC world, you explicitly assign a policy to a role, or in this case, a user. Every time you add a new user or customer, you have to remember to update your policies!
Dynamic Row-Level Filtering Policies with Immuta
With Immuta’s ABAC approach, you are able to treat user attributes as variables and use them in the policy. Here’s a screen shot from Immuta depicting a user, stouw, and his associated Customer IDs.

While this is being shown in the Immuta console, it’s important to understand that these user attributes – how you define your users – can come from any system in your organization through the Immuta pluggable interface.
Now, let’s use that attribute to dynamically enforce the row-level policy:
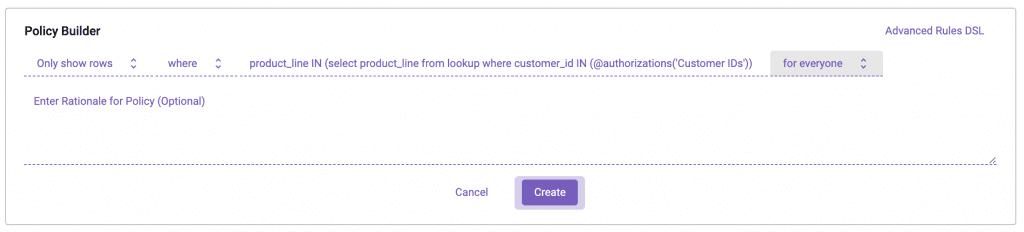
In the Immuta ABAC world, we are able to separate defining the user from the policy, allowing the policy to dynamically make a decision based on who the user is at query time. This is possible due to that @authorizations method in the policy, which treats the user’s ‘Customer IDs’ attribute as a variable. This also means that if you add new users, you never have to create another policy.You simply need to tag them with the attributes they possess, and there is no implied access with that assignment.
This enabled us to boil down to one policy in Immuta.
But wait, there’s more!
What I didn’t show in that Ranger policy is that you must build the Ranger row-level filtering policies one table at a time. So, not only do you need a policy per Customer ID + User combination, but you need it per Customer ID + User + Table (with product lines) combination. You can see how this can quickly balloon to many, many policies.
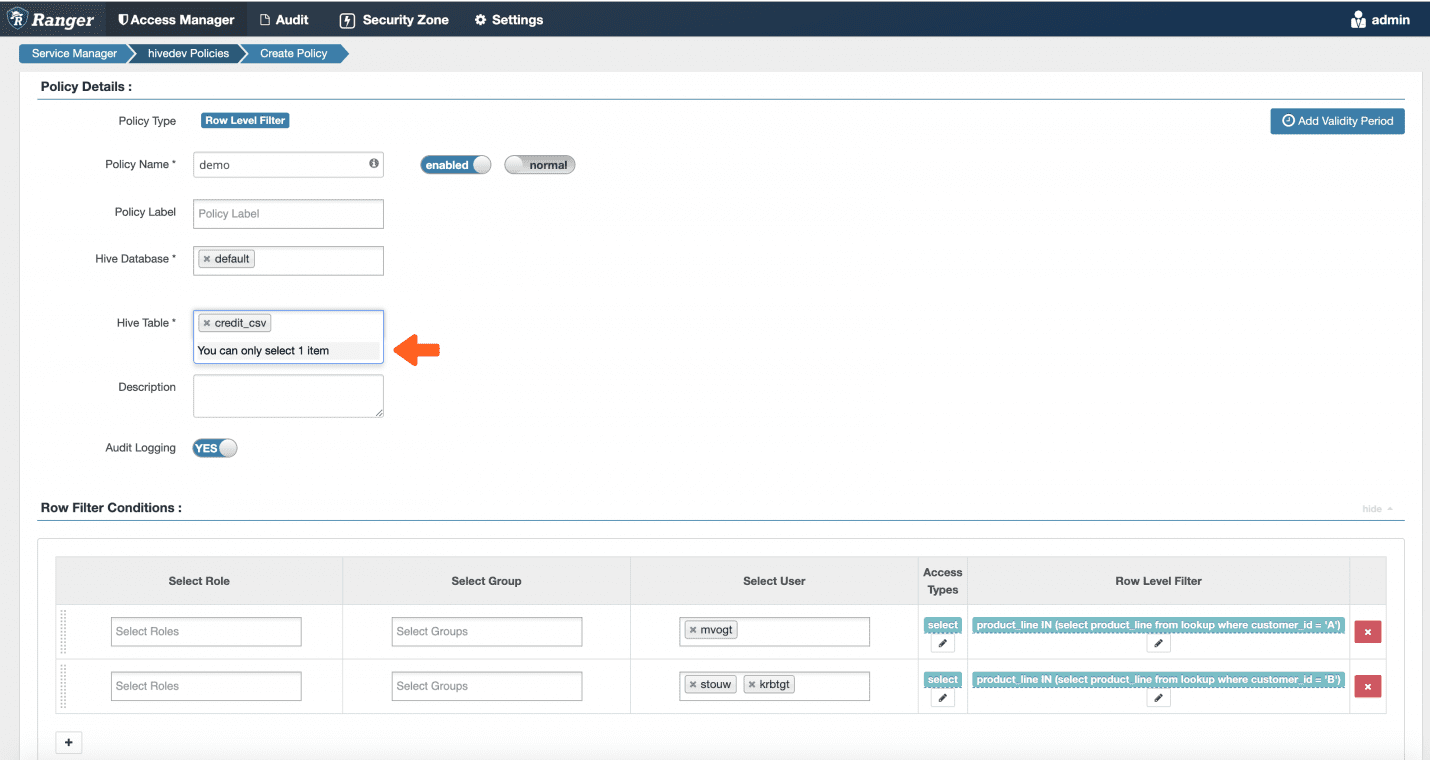
Scalable Row-Level Filtering Policies with Immuta
So how do we avoid doing this row-level filtering policy per table in Immuta? We use the logical layer, also known as tags, to build the policy (note that Ranger does support using tags for some policies, but not row-level policies).
In Immuta, you are able to tag your tables and columns, and use those as variables in policies just like we did with our user attributes. It’s important to understand that just like user attributes, those tags can come from any and multiple systems (business glossaries/catalogs) across your organization – wherever you define your data – in order to drive policy:
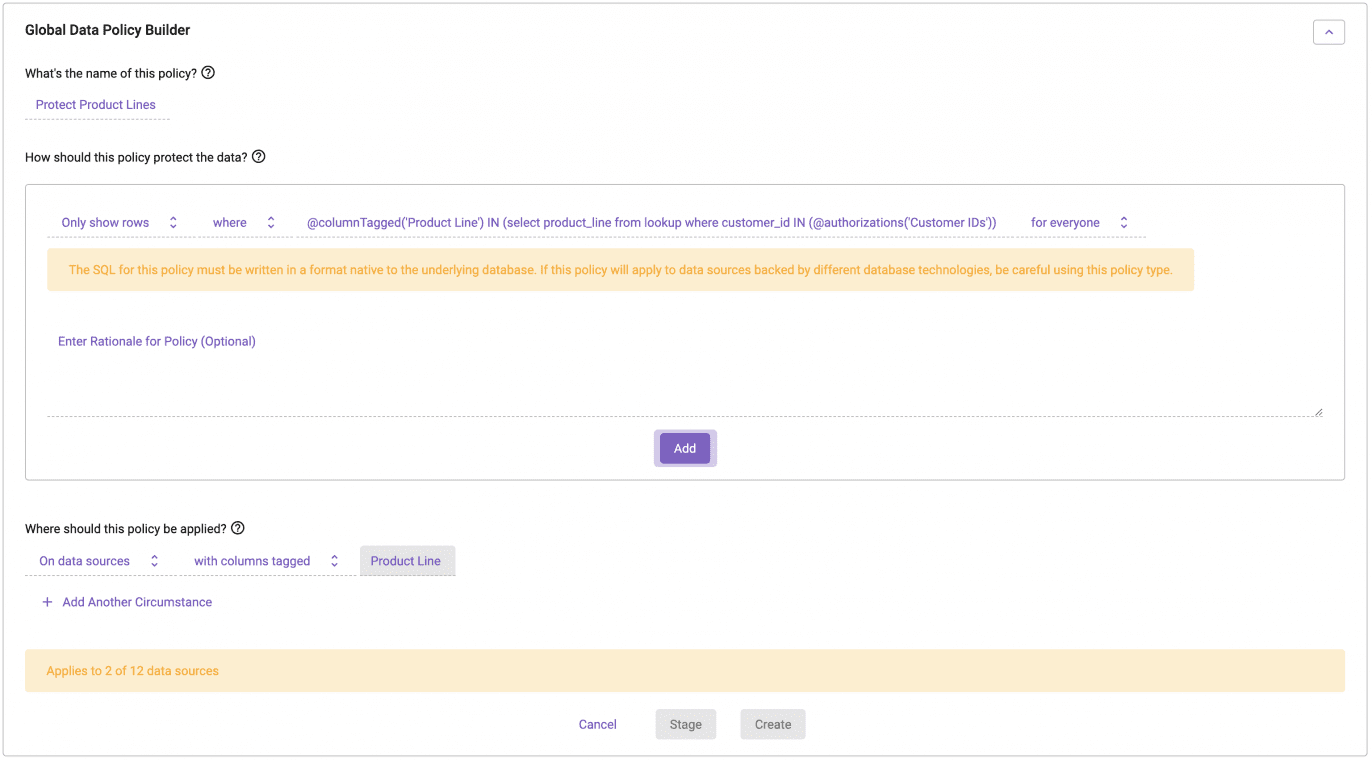
You’ll notice the policy hasn’t changed much from the previous Immuta policy example, other than two components:
- We’ve replaced the physical column name of product_line with the @columnsTagged variable, which is treated as a variable in the policy.
- Anything with a column tagged ‘Product Line,’ no matter what table it lives in or how the column is spelled, will have this policy correctly applied to it. In this case, you can see it is two out of our 12 tables (termed data sources in Immuta).
We’ve successfully kept this at a single policy, no matter how many tables it impacts. This also does not need to be updated at all. Whether you are adding new users or adding new tables, you simply keep the definitions of your users and tables up to date (with attributes and tags, respectively).
Policy 2: Contrast Ranger Masking Policies with Immuta
Let’s draw an analogy. Imagine you are planning your wedding reception. It’s a rather posh affair, so you have a bouncer checking people at the door.
- Do you tell your bouncer who’s allowed in? (exception-based)
- Or, do you tell the bouncer who to keep out? (rejection-based)
The answer to that question is pretty obvious… but, when building masking policies in a Ranger/RBAC world, you define who to keep out of the wedding reception (who the masking policy applies to), not who to let in the wedding reception (who is an exception to the masking policy). This causes data leakage issues because there is no way to define default behavior (reject anyone without an invite), which you’ve undoubtedly had to account for with Ranger. Rejection-based masking logic is another reason for policy explosion with Ranger/RBAC because you are, again, explicitly assigning a policy against a role rather than making dynamic decisions.
Rejection-Based Masking Policies with Ranger
Here’s an example masking policy in Ranger that will apply on any column tagged PII:
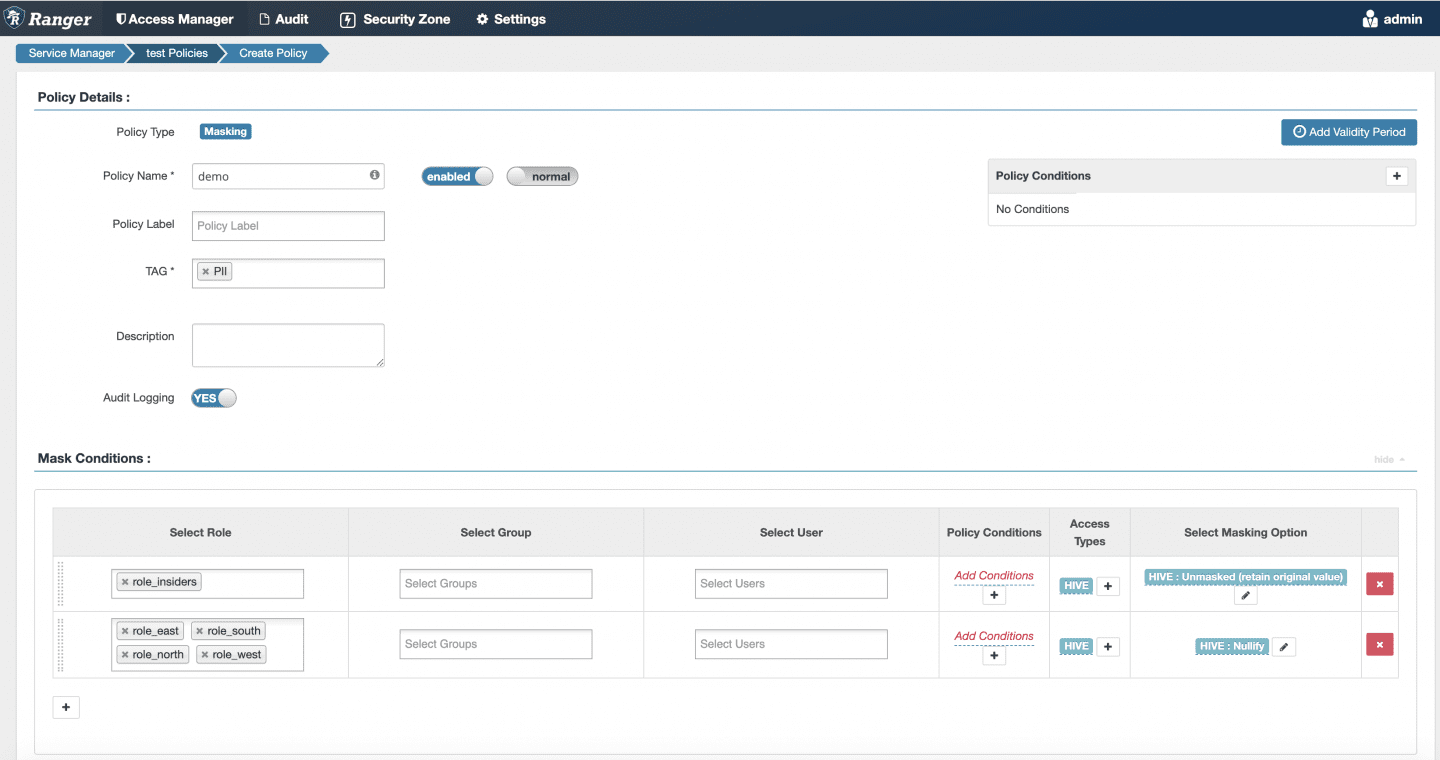
In the Ranger masking policies, we must account for every possible role in the system. You might be wondering why we have the “Unmasked (retain original value)” for role_insiders. This is because if someone belongs to both role_insiders and role_east, for example, they will see the data in the clear rather than the masked value because Ranger processes these policies in order, top to bottom. This is a byproduct of rejection-based policies; you must account for all roles because you are “keeping people out of your wedding” (role_north, role_south, role_east, role_west), not simply listing who should be let in (role_insiders). Isn’t it odd that your masking type is “Unmasked (retain original value)?” The answer is yes, because this model is odd but required because you must explicitly tie policy to roles (or users).
To make matters worse, let’s say a new role is added to the system while you’re on vacation – role_central. If the person or people tied to this role are not also in role_north, role_south, role_east, role_west, they will see the PII because there is no policy tied to it! You must remember to update this masking policy any time that situation arises in your identity management system to avoid that severe PII data leak.
Exception-Based Masking Policies with Immuta
With Immuta/ABAC, the policies are built using an exception-based model. When we think about our wedding analogy, this means the bouncer has a list of who should be let into the reception. This will always be a shorter list of users/roles if following the principle of least privilege, which is the idea that any user, program, or process should have only the bare minimum privileges necessary to perform its function. This aligns with the concept of privacy by design, the foundation of the CPRA and GDPR, which also states “Privacy as the default setting.”
Here is this same policy in Immuta:
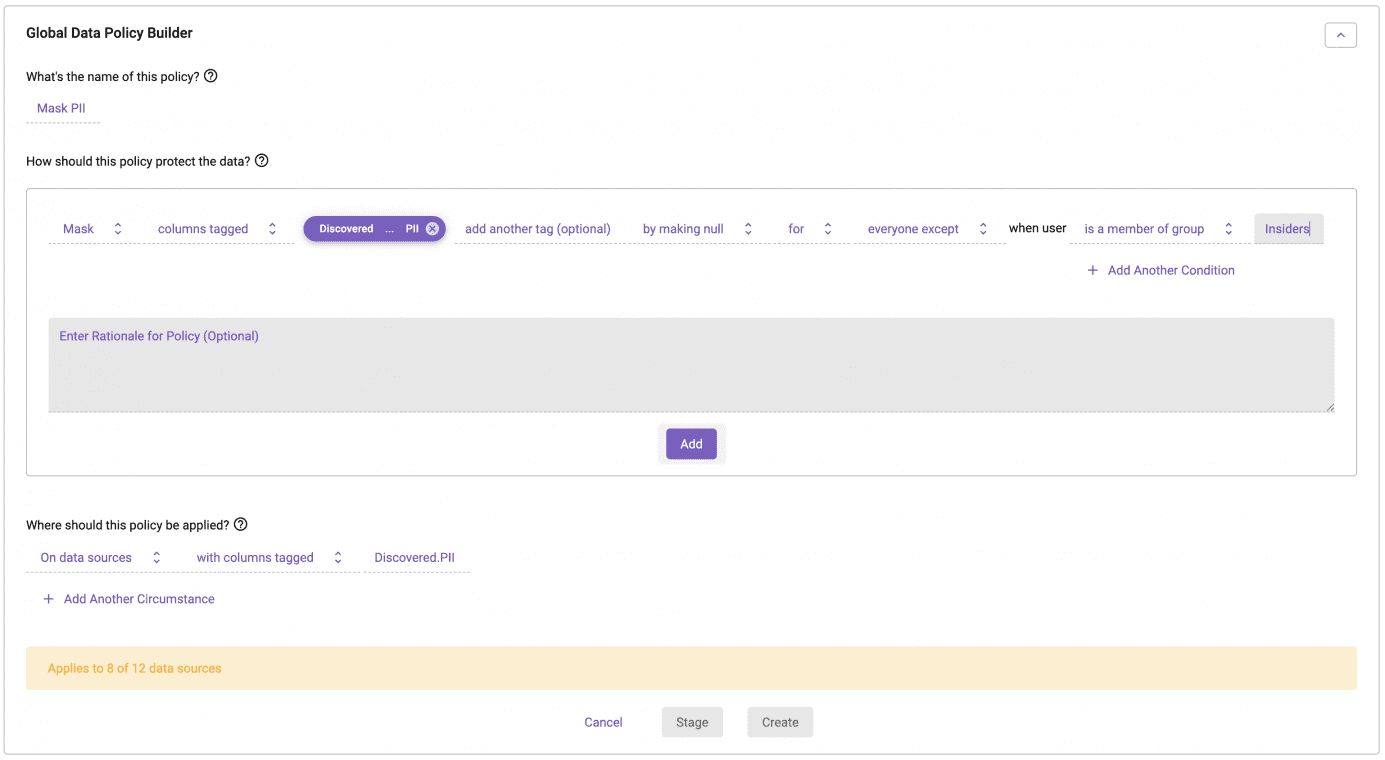
You can see this policy is much more comprehensible and aligns with how you should be thinking about access control to highly sensitive data like PII: exception-based. It also means that as new users and/or roles are added to the system, you do not need to update your masking policies at all, just like if a new baby is born, you don’t need to add them to the bouncer’s list of who not to let in. There is no longer a data leak risk.
But what if you have a policy that has different masking types per role, such as in the example below in Ranger?
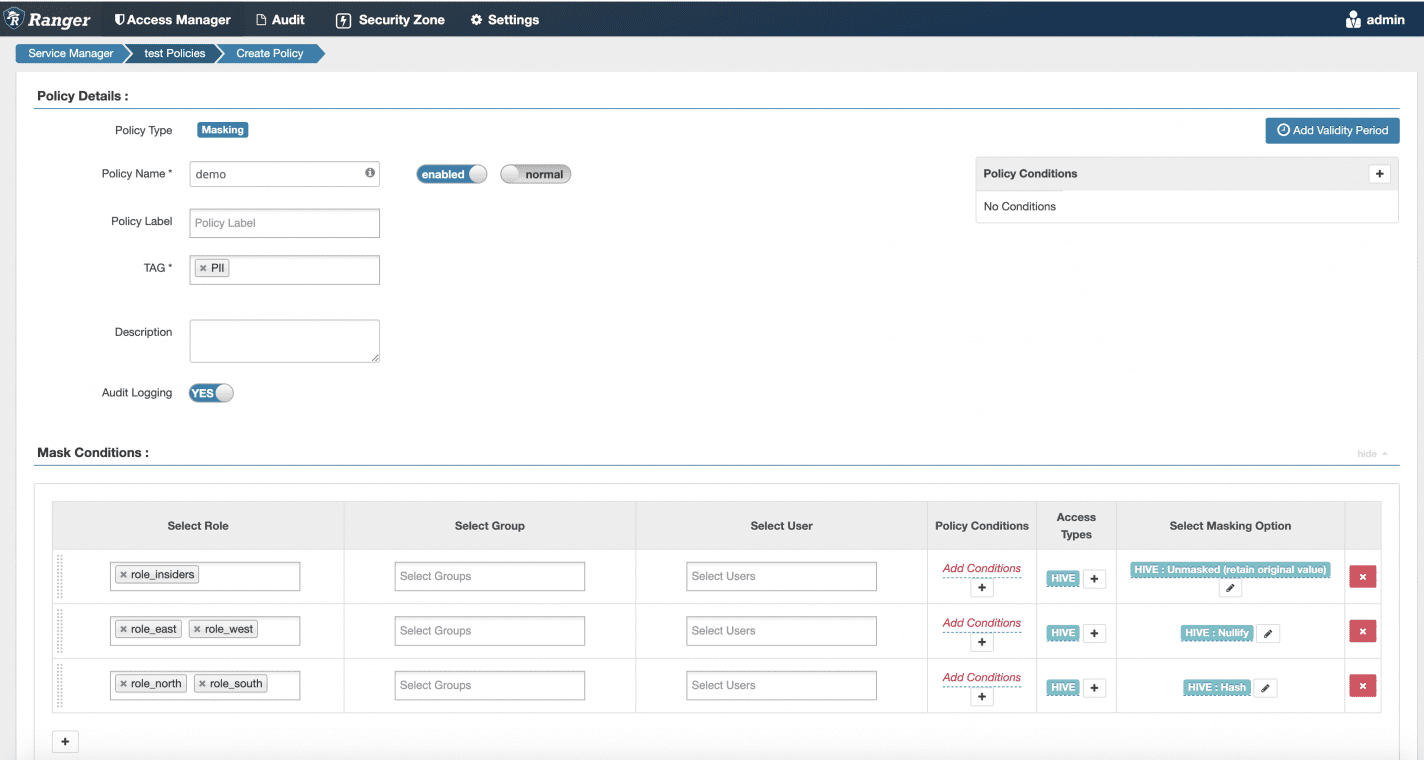
In this case, role_east and role_west get the PII nullified, but role_north and role_south will get the PII hashed (and role_insiders alone will see the PII in the clear). It’s important to note that Ranger has the same problem described with masking as described with row-level: If you need to combine roles with AND rather than OR, you must create new roles to represent that AND (not pictured in this example).
In Immuta, we can do the same exception-based policy trick that avoids accounting for all possible roles. Looking at this policy, here is the amount of utility you get from the data per masking type in order of best to worst:
- Seeing the data unmasked: obviously, the greatest utility.
- Seeing data hashed: since it’s deterministic, you can at least track, associate, and/or aggregate the values, but not know what the true value is.
- Seeing the data nulled: the column is completely useless.
Understanding which policy provides least privilege – in this case null – we should write the policy in Immuta to ensure that is the default behavior (and is understood to be the default behavior):
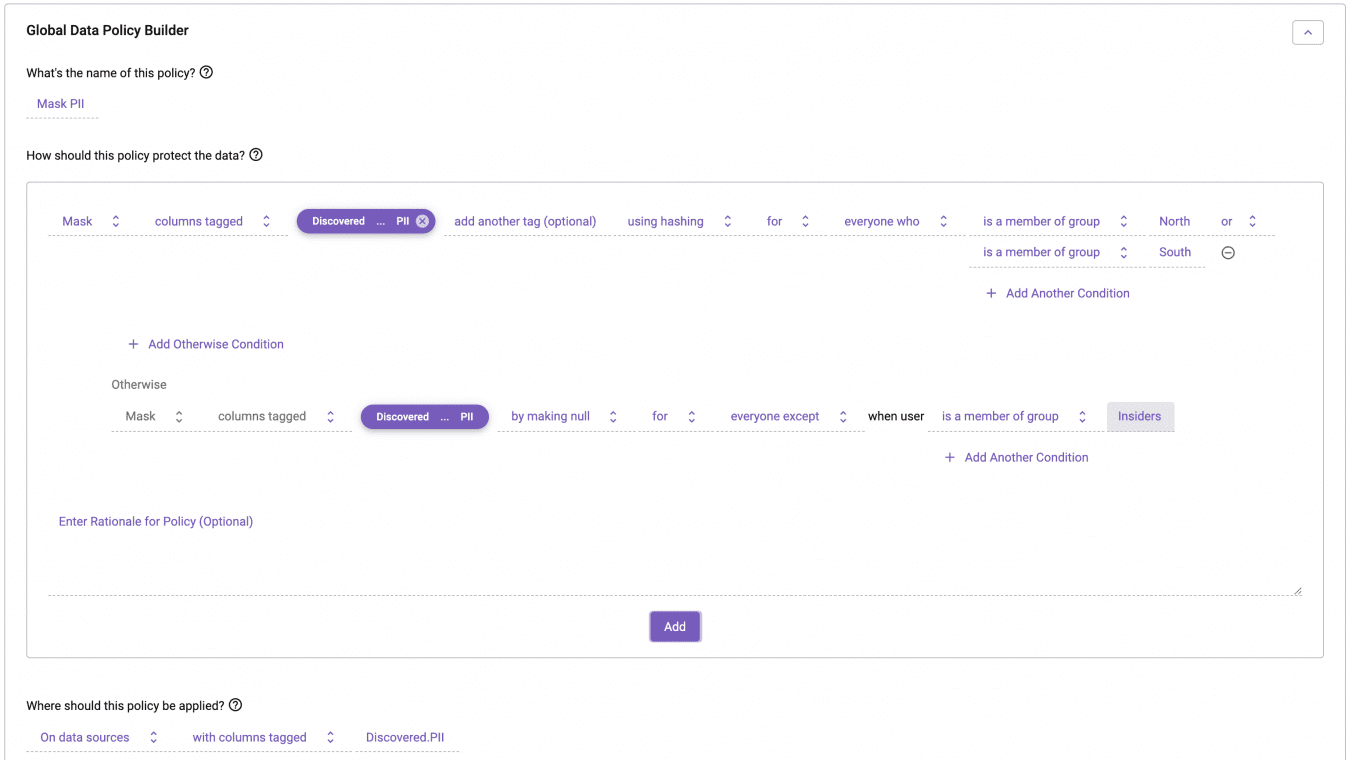
This is the power of ABAC with exception-based policy definitions. We’ve reduced the number of policies but also reduced the amount of “role-tracking” you must do to avoid data leaks when new roles are added to the system because you are able to set a default to least privileged.
This concludes our quick summary of migrating from Ranger to Immuta on Databricks. We skipped over other important topics, such as dynamic data masking and advanced privacy enhancing technologies (PETs) supported by Immuta and not Ranger, such as k-anonymization and differential privacy, which can open much more data to your users.
There are also, of course, many other policy nuances that could be covered here but weren’t, which we’re happy to discuss if you want to reach out with specific questions. And, if you’re wondering how Databricks row-level security is actually done in Databricks – it is native within the Spark execution – Immuta enforcement is completely invisible to users executing Spark on the Databricks cluster, no matter the language: R, Scala, Python, or SQL.