The terms role-based access control and attribute-based access control are well known, but not necessarily well understood — or well defined, for that matter. If attribute-based access control includes user roles, then what is role-based access control? Where is the line drawn?
Fundamentally, these data access control terms — role-based access control and attribute-based access control — are poorly named and confusing. That’s because they are less about the role or attribute, and more about how the policy is handled. Policies are central to access controls, and how they’re applied is the defining factor between role-based and attribute-based access control. More importantly, what they allow data teams to do distinguishes highly efficient and secure data use from cumbersome, risky practices.
2024 State of Data Security Report
700+ data professionals' perspectives on AI, data security, and governance.
Access the Report
What is Role-Based Access Control (RBAC)?
Role-based access control (RBAC) is an approach to data security that permits or restricts system access based on an individual’s role within the organization. This infers that data consumers can only access data that pertains to their job functions. Role-based access controls typically manage access to tables, columns, and cells, and is closely tied to table access control list (ACL), although the latter is more data consumer-specific and isn’t as realistic a choice when implementing organization-wide.
Data teams managing access through RBAC implicitly predetermine what the users will have access to by adding them to a role, then explicitly determining the privilege associated with each role. Put simply: data engineers decide who belongs in an arbitrary “thing” — in this case the role — then must decide what that “thing” has access to.
Because of this implicit predetermination, a better term for RBAC would be static-based access control. An analogy that fits quite well to describe RBAC is writing code without the ability to use variables: You write the same block of code over and over again, with slight changes tied to the role you want that policy to act against. For example, if you wanted a policy to restrict access to a specific U.S. state for each role in your organization, you would have to write 50 policies — one for each state — and also maintain 50 roles for each policy. Another twist is that if any users had access to more than one state, you would need to create a policy for those scenarios — with RBAC, everything must be predetermined.
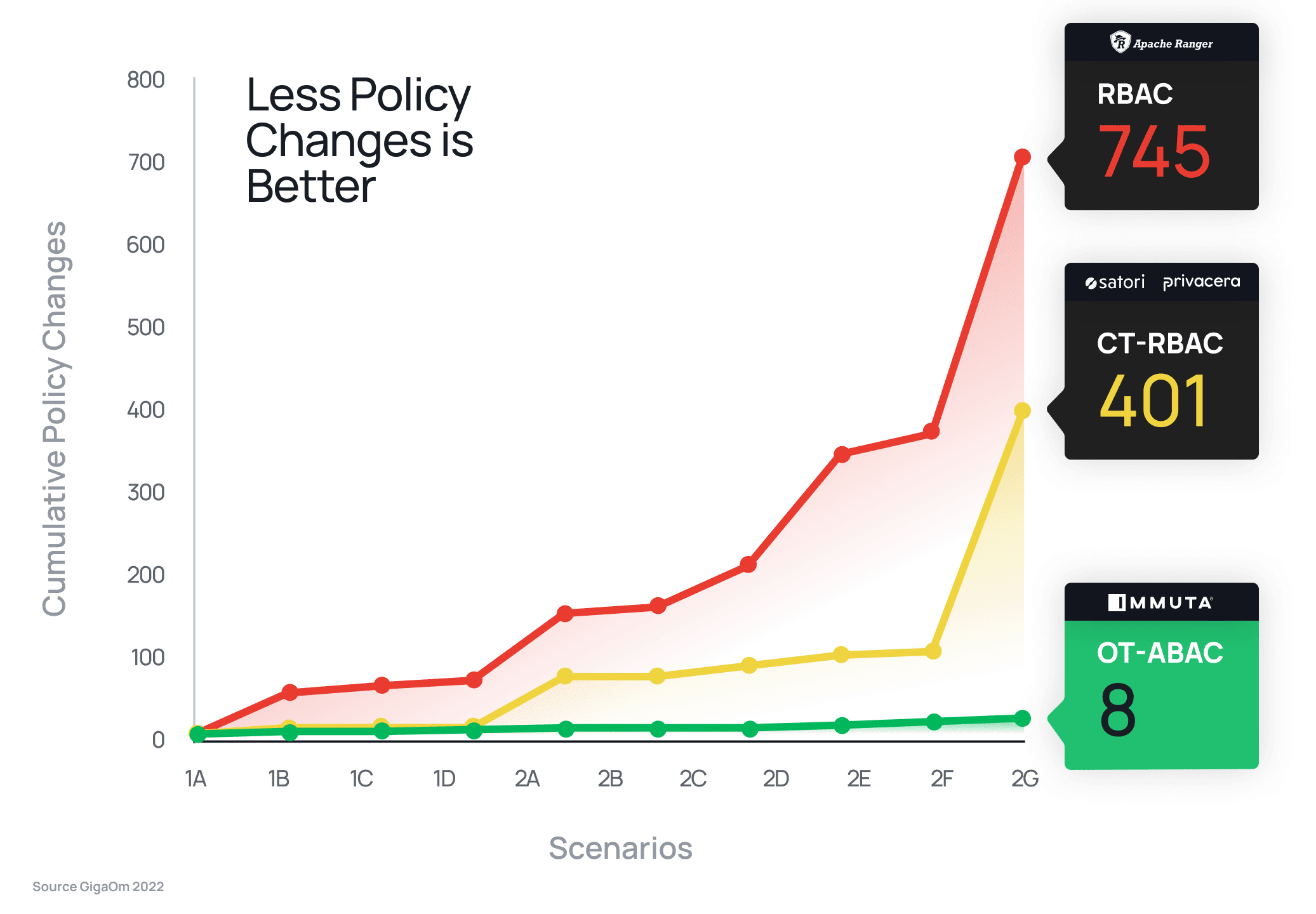
Almost all modern and legacy databases utilize the role-based access control model to implement data access control. Open source access control frameworks, such as Apache Ranger and Sentry, also follow this approach. However, the limitations of such frameworks are clear, as independent research by GigaOm demonstrated – the static nature of role-based access controls required 93x more policy changes than attribute-based access control to satisfy the same security requirements.
[Tip] Get a Timeline of Data Access Controls in RBAC vs. ABAC: Future-Proofing Access Controls
What is Attribute-Based Access Control (ABAC)?
Attribute-based access control (ABAC) is an approach to data security that permits or restricts data access based on assigned user, object, action and environmental attributes. In contrast to RBAC, which relies on the privileges specific to one role for data protection, ABAC has multiple dimensions on which to apply access controls. This makes attribute-based access control a highly dynamic model because policies, users, and objects can be provisioned independently, and policies make access control decisions when the data is requested.
It’s important to first understand the elements of attribute-based access control in order to understand how it works:
- Attribute: A characteristic of any piece of data in the system. ABAC makes access decisions based on the attributes of users, objects, and environment.
- User attributes: Information about a data user, including name, title, department, and permission level.
- Object attributes: Information about the data itself, including creator, type, creation date, and level of sensitivity.
- Action attributes: Information about what is being done to the data by the subject, including reading, editing, approving, and deleting.
- Environmental attributes: Contextual information about the data, including location, date of access, and level of organizational threat.
- Policy: A set of rules stating permission or restriction to data based on its attributes.
To define ABAC more concretely, let’s revisit our U.S. state example. Rather than having to build 50 policies and roles — or more, depending on whether users have access to more than one state — you can instead treat attributes as dynamic variables. This means with ABAC, you can create that 50-state rule with a single policy, like so: only show rows where state IN (@user-attribute:state), where @user-attribute:state is the dynamic attribute that contains their list of states.
This example demonstrates why ABAC would be more accurately defined as dynamic-based access control. Revisiting our original analogy, ABAC is like writing code using variables, eliminating the need to create the same blocks of code (policies) over and over again. The list of variables at your fingertips, listed above, allows you to separate who the user is, what they are doing, and what policy should be dynamically applied at runtime, rather than predefining all policy up front by conflating who has access to what based on roles, as with RBAC.
Find Out More: What is ABAC? Attribute-Based Access Control 101
What Role-Based Access Control is Not
It’s common to get confused by the term role-based access control and assume if the “role” can come from multiple systems and dimensions, as with ABAC, it actually qualifies as attribute-based access control. While role is a critical component of RBAC, policy is still being applied statically, rather than dynamically. This is why role-based access control should really be called static-based access control (SBAC) and attribute-based access control should be called dynamic-based access control (DBAC).
It’s important to remember that if you’re currently using RBAC, you do not have to throw away existing roles to switch to ABAC. You can simply leverage them in a new and more powerful way — dynamically — with ABAC. You can read more about how here (hint: you’re probably already 90% of the way to an ABAC model!).
Additionally, RBAC can be confused with tag-based or logic-based policy authoring, where policies are applied to tables not based on their physical table definitions, like table name or column name, but instead on their logical metadata, such as “mask everywhere there is PII.” While this is a powerful feature for building scalable policies and data attributes are critical to attribute-based access control, it does not complete the full ABAC model.
Role-Based Access Control Pros and Cons
Pros of RBAC
The main advantage of role-based access control is that it’s been widely adopted and allows small- to medium-sized organizations to eliminate implementing access controls on an individual basis. Since RBAC policies can be written on the basis of the existing roles in the organization, they are easy to establish and assign. New employees and internal role changes no longer require new policy creation; data teams can simply assign or update the appropriate role to dictate employees’ data access levels.
Additionally, data engineers can assign a single user to multiple roles and create access hierarchies. For instance, a manager with a “human resources” role assignment can also be given a “manager” role assignment, and may have broader access privileges than their direct reports, allowing the manager to override their role-based restrictions. However, it’s important to note that not all RBAC enforcement engines support hierarchical role structures, and instead support a flat structure that only allows one role at a time per user.
Establishing role-based access control is relatively easy, thanks to its dimensionality (or lack thereof). Data teams map the roles within the organization and assign access permissions to each; once established, permission is automatically provisioned or deprovisioned based on a user’s assigned role in the system. This “set it and forget it” approach frees data teams from manually granting or restricting access, but it also requires them to proactively set up new roles and permissions if and when necessary. Many times, this will begin to fall out of real-world organizational structures because it means building roles for the purpose of policy — remember, with RBAC, all policy must be predetermined.
Cons of RBAC
The same feature of role-based access control that makes it easy to set up is also one of its greatest limitations. For small- and medium-sized organizations, RBAC may be manageable; however, as the number of people and roles grows, the job quickly becomes much more complex for data teams, particularly if utilizing a hierarchical approach. This introduces the very likely potential for “role explosion,” which requires data engineers to manage hundreds or thousands of user roles in an effort to control access to data in specific tables or databases. This time-intensive responsibility negates a central reason for implementing role-based access controls in the first place — saving time on enabling access control on an individual basis.
Role explosion also creates a situation in which the administrator can no longer easily understand which roles belong to which access permissions, so translating a user need to an actual role assignment can be very complex to manage.
Since data teams must predetermine all policies up front, RBAC requires work when new data arrives. In our U.S. state example, if you’ve built all the policies — one for each state and role — and then begin to load data from Canada, nobody will be able to see the Canadian data unless you’ve remembered to preemptively create the policy before the new data arrived. With so many policies, users, and other things to keep track of, this is a big ask for any data architect or engineer. Because RBAC does not future-proof any changes in the organization, you must always proactively remember to update policy on any data or organizational structure change.
Additionally, RBAC inherently neglects the principle of least privilege, which states that data consumers should be given access only to the data necessary for completing a task at hand, and no more. Coarse-grained access control offered under the RBAC model does not allow data teams to automatically set permissions based on an individual’s need at a certain moment in time. Each custom permission becomes a new role, contributing to the role explosion mentioned earlier.
For instance, someone in accounting may work solely on accounts payable and have no reason to access employee payroll information. Meanwhile, another person in the same accounting department may need access to employee tax information but doesn’t have a reason for accessing contractual agreements. Role-based access control may either give both people too much access — violating the principle of least privilege and potentially exposing sensitive information — or be overly restrictive, in which case individuals may request access that data teams must manually verify and grant or deny, increasing the organization’s number of roles.
Attributed-Based Access Control Pros and Cons
Pros of ABAC
Attribute-based access control leverages multiple dimensions of the data’s and data consumer’s unique attributes to determine whether to grant or deny data access. Unlike the static role-based access control model, ABAC’s multidimensional approach makes data access more dynamic. Data teams define attributes and create policies for them, but once assigned to system components, they require little maintenance. This avoids manual role creation and subsequent role explosion, while making data access control more scalable. A single policy in the ABAC model can replace hundreds of separate roles that would’ve been necessary to achieve the same outcome using a RBAC approach.
While one of the ABAC attribute categories concerns user roles, unlike RBAC they are taken into account alongside several other factors. Therefore, attribute-based access control provides more control variables than role-based access control, making data more secure and adhering to the principle of least privilege. This means data and compliance teams can feel more certain that data is not overly accessible by individuals who should not have access. Having fewer role-specific policies makes the ecosystem easier to manage and monitor, enabling data policy enforcement and auditing that reduce the chance of any sensitive data slipping through the cracks and getting into the wrong hands.
Looking back at our accounting department scenario, attribute-based access control may define both users as being in accounting, but thanks to permissions associated with the object attributes — for instance, contracts and invoices versus tax information — if someone responsible for accounts payable tries to access a W-9, they will be denied. To take it a step further, the accountant responsible for payroll may be able to access W-9s, but only during a certain time period or to perform a specific action, like viewing but not editing. This ensures the right people have access to the right data at the right times, and in doing so adds layers of security in a scalable manner that doesn’t require time-intensive role updates or creation.
Unlike RBAC, which conflates who the user is with what access they should have, ABAC separates the who from the what. This flexibility is what makes ABAC dynamic. Furthermore, because ABAC is dynamic, it is also future-proof. In the US state example, if new Canadian data is added under an ABAC model, there would be no need for a new policy because the existing policy — only show rows where state IN (@user-attribute:state) — would still hold.
Cons of ABAC
While role-based access control is easier to establish but harder to scale, attribute-based access control is the opposite: more work to establish but easier to scale. This is because data teams are tasked with defining a standard for defining data access policies, then creating and uniformly implementing these policies across their data landscape, including on-premises and cloud platforms.
Anticipating data security needs and enacting adequate plans to address them requires working with legal and compliance teams to understand regulations like HIPAA compliance and GDPR compliance, contractual obligations and industry standards, among other considerations. While legal and compliance teams can provide guidance on the substance of these requirements, it’s up to data teams to execute secure, consistent protection measures. Having a standardized definition for data access policies is a first step, but an automated data access control solution like Immuta, which spans across data sources and offers ABAC, streamlines the process and allows it to be more intuitive. This makes the time- and labor-intensive up-front work less burdensome and ensures more reliable protection is in place.
Which One to Use: RBAC or ABAC?
For small organizations just starting to implement access control management, role-based access control seems to be a reasonable place to start. With few internal users, very few policies and a limited amount of data, this approach is an easier lift to get off the ground as a preliminary data protection measure.
However, small organizations debating between RBAC and ABAC that are concerned with modern privacy regulations and/or that have plans to grow — as well as any other organization comprising more than a few data users — would be wise to implement attribute-based access control from the start. Doing so will allow them to scale more easily without having to reassess their data access structure and rewrite their access control policies after data sources, policies, and/or users have increased substantially.
It’s also important to consider the current state of the world: While RBAC may have worked in the past, complex data regulations are much more pervasive now and will continue to be so, making RBAC an increasingly antiquated approach. Regardless of organizational size, the proliferation of sensitive data being used to drive analytics in today’s market is enough to make any data teams’ heads spin. Keeping up with rapidly growing and evolving data sets, use cases, business needs, and regulatory demands is incredibly complex with coarse-grained access control offered by RBAC. Conversely, ABAC’s dynamic policy creation makes it significantly easier for data engineers to maintain pace with incoming data and prepare it accordingly, without spending unnecessary time creating new roles to accommodate new needs.
Immuta’s attribute-based access control leverages dynamic attributes to enforce data protection at the time a query is made, enabling protection down to the row-, column-, and cell-level. This means access decisions are explicitly tied to the data object, action, and purpose for access, as opposed to implicitly predetermined by a static role-based policy. Therefore, Immuta’s fine-grained access control upholds the principle of least privilege, while at the same time avoiding overly restrictive controls that are inefficient for data consumers and delay speed to data access and analytics results.
With Immuta’s cloud-based architecture, which decouples users, attributes, and policy decisions from compute, data teams can also automatically enforce policies based on data and user attributes, such as geography, time and date, clearance level, and purpose. This means as new data or users are added to a system, data engineers don’t need to remember to preemptively update policies. In other words, their data protection strategy has been future-proofed and made compute-agnostic.
[How To] Enable Snowflake Attribute-Based Access Control with Decentralized Ownership
Purpose-based access control (PBAC) in Immuta buffers this policy enforcement by universally applying regulation-based restrictions to sensitive personal data, as detected by automated sensitive data discovery tagging. When combined with dynamic data masking tools like k-anonymization and differential privacy, this reinforces confidence that the right people are accessing the right data at the right time, and for appropriate purposes. For regulatory compliance and auditing, this level of control is particularly powerful and critical for ensuring data is adequately protected and reportable to legal and compliance teams.
See It In Action: Watch a short PBAC demo here.
In sum, Immuta’s attribute-based access control enables:
- Flexibility — because the policies needed to meet ethical and legal privacy obligations are more complex now than ever before, and will continue to increase in complexity.
- Simplicity — because it avoids role explosion and removes the burden on data teams to predetermine and create roles for each new data access request or data usage need.
- Customized permissions — because it separates user attributes from where and when users have access to data, which in turn removes uncertainty about what data users implicitly have access to data when they are added to roles.
See how much time your data team can save with Immuta’s dynamic attribute-based access control by requesting a demo.