“Don’t Repeat Yourself” is a powerful principle for software engineers and data professionals. But staying DRY while implementing data access controls is a nearly impossible task. Every tool pushes you to redefine user permissions in its own “governance layer.” That configurability is great for tool users and admins, but it introduces significant complexity into the data platform as a whole: No one knows where rules are really defined, or why, or how new ones can be updated. There is no “single source of truth” for access control policy, but is instead a mish-mash of rules in different applications.
In this post, I’ll explain how Immuta’s data team uses dynamic access controls in Snowflake to drive access policies in downstream systems such as Looker and Jupyter Notebooks. Our approach is driven by two principles:
- As much access control logic as possible should be implemented where the data resides.
- Everywhere possible, users should access data as themselves.
Focusing our access control efforts on the data platform (Snowflake, in our case) allows us to simplify administration at the application layer while increasing the transparency across the organization of who can see what data.
Proliferation is the problem
When data is accessed within the confines of its original application, it is rich with context, often including role-based access controls. When that data is extracted, though, it’s stripped of these application controls and dropped in a new environment — the data engineering edition of Naked and Afraid.
With analytics tools, though, we often do this one or more additional times, meaning if we want to implement the same controls as the source system, we would have to do it twice or more, in different applications. This is too much for even the most dedicated data team, which will typically focus its efforts on the most visible layer — the analytics tool — and may create one or more system users for passing access through.
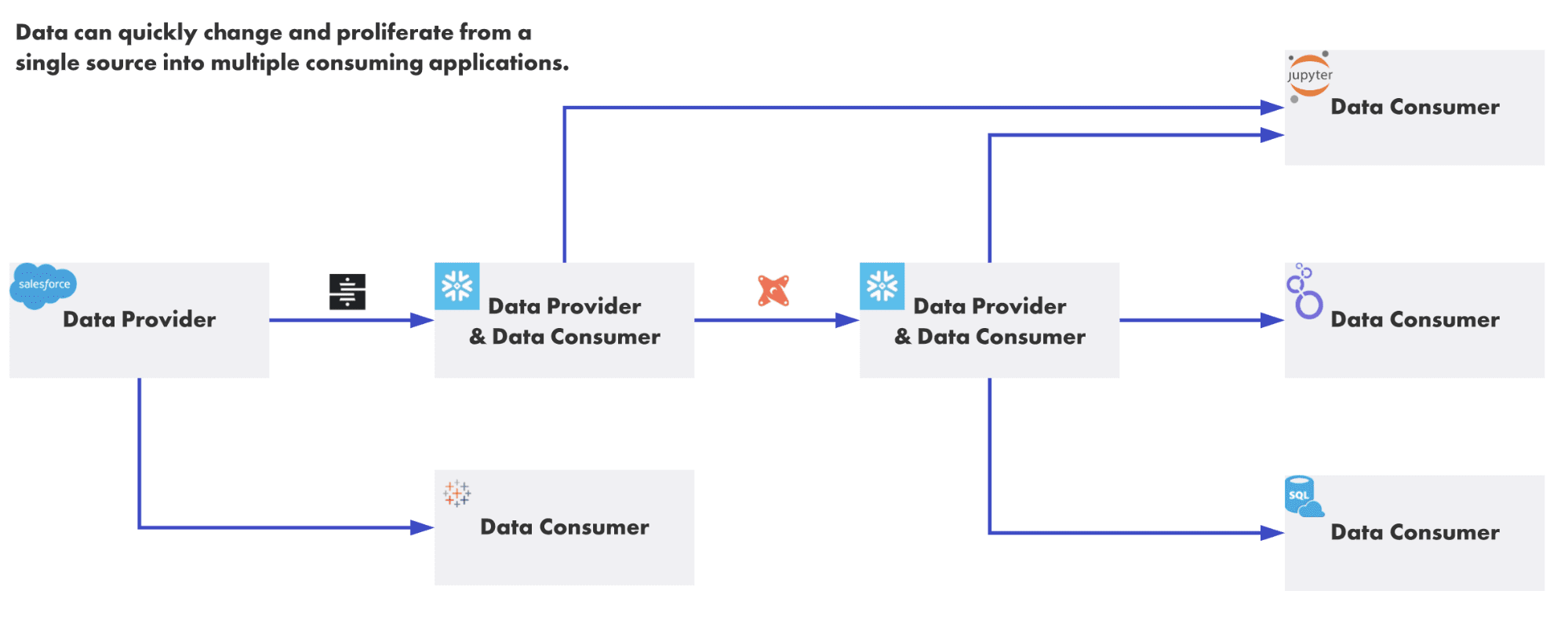
Data consumers may wish to read from raw or derived sources, and from a variety of tools. Additionally, it is also possible for users to access many data platforms directly.
In an ideal world, you’d define your access control rules in one place, and downstream applications would invoke them, eliminating the need to define additional application-specific logic. For example, a rule prohibiting a marketing user from accessing a certain table would be created in Snowflake, and Looker would be able to enforce that rule simply by passing the user credentials down when it queries Snowflake.
The platform-centric access control model
To begin to address this challenge, our data team has adopted a platform-centric access control approach with Immuta. We follow two principles when making architectural decisions in order to manage complexity in downstream tools.
First, make the data platform — Databricks, Snowflake, Starburst, etc. — the center of your ecosystem. By focusing here, you can shift the gravity of your data assets away from peripheral data consumption tools and closer to your ingestion and transformation processes.
Second, wherever possible, users should access data as themselves. This principle is simple to say but hard to do. It requires a mature user onboarding process and well-defined user attributes. It also requires data platform owners to learn a whole new set of acronyms (IAM, AD, SAML, LDAP). And finally, it requires connecting systems in a way that honors the relationship of the user to the database.
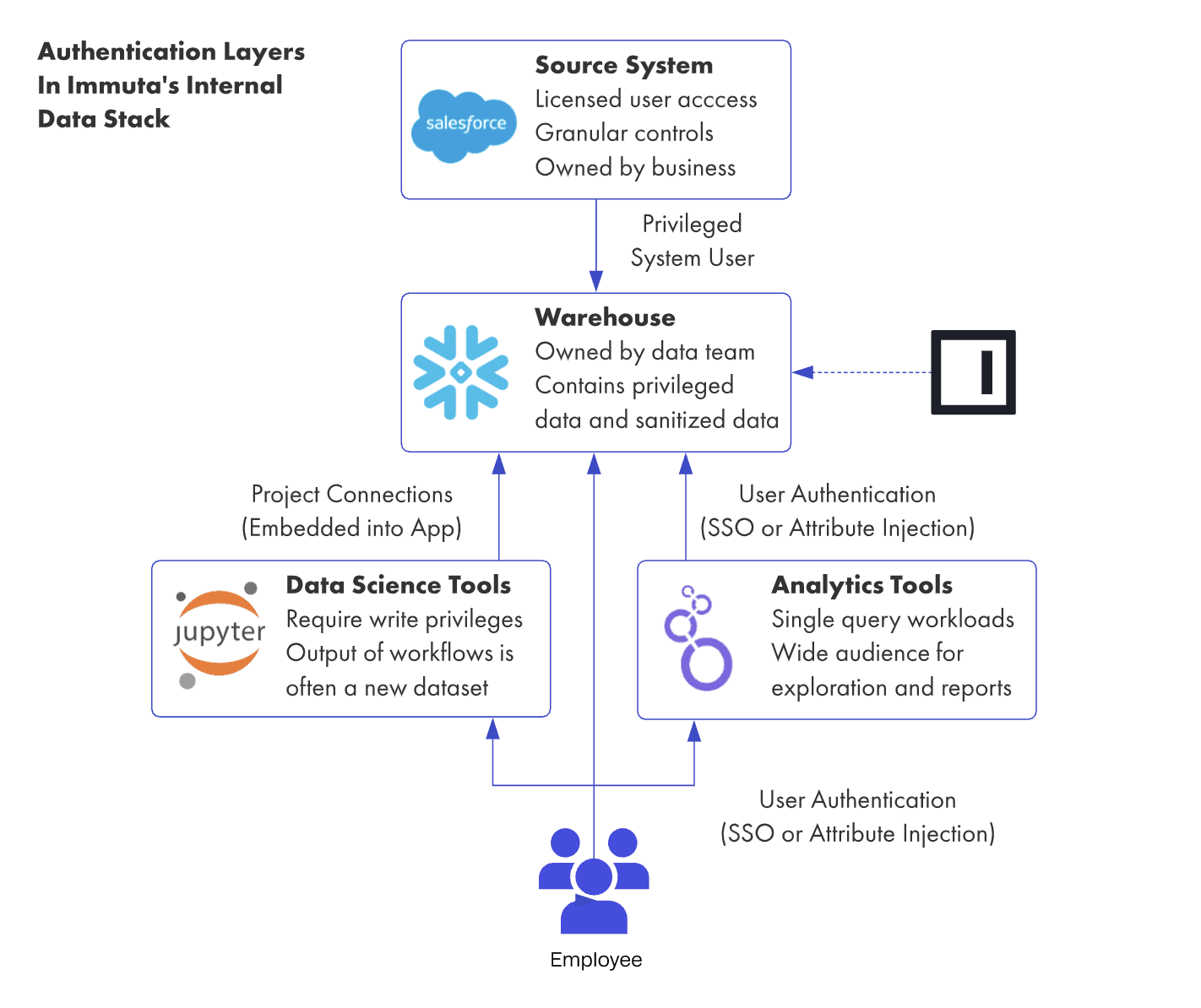
Although it may seem trivial to allow individualized connections against a given database, it is not. Many analytics tools don’t allow for the customization of database connections at the user level, or the injection of attributes into the query itself. One reason we selected Looker as our team’s analytics platform was precisely because of its rich set of user attribute features that enables us to individualize connections with the database.
Individualizing Looks with Looker
Our overall goal is to provide a simple user experience, reduce complexity in where and how we manage access control rules, and improve auditability of the data assets our team delivers. We can achieve this by setting up the Snowflake database connection using OAuth for the majority of our dashboard models. With this approach, users get personalized results for each dashboard fed by that connection string, since access policies will be enforced by the Immuta-backed database views at query time.
Pushing policy down to Snowflake allows us to greatly simplify the permissions model in Looker. We no longer need to manage access to models for control purposes, and can instead think only about managing the user experience and developer privileges. We can be confident that consumer and employee data will have the correct policies applied — and we can audit and track this as well.
This dynamic approach, however, is not without tradeoffs. While it creates a consistent user experience across a variety of tools and increases visibility into where data is coming from, it also creates a greater burden on architecting systems correctly. There are times when a report-builder will want to cache data in the consuming tool for performance purposes. This caching eliminates the possibility of a user-based authentication against the database, since it must copy the data into the tool (or, for example, create a persistent derived table in the database, in cases such as Dataiku or Looker).
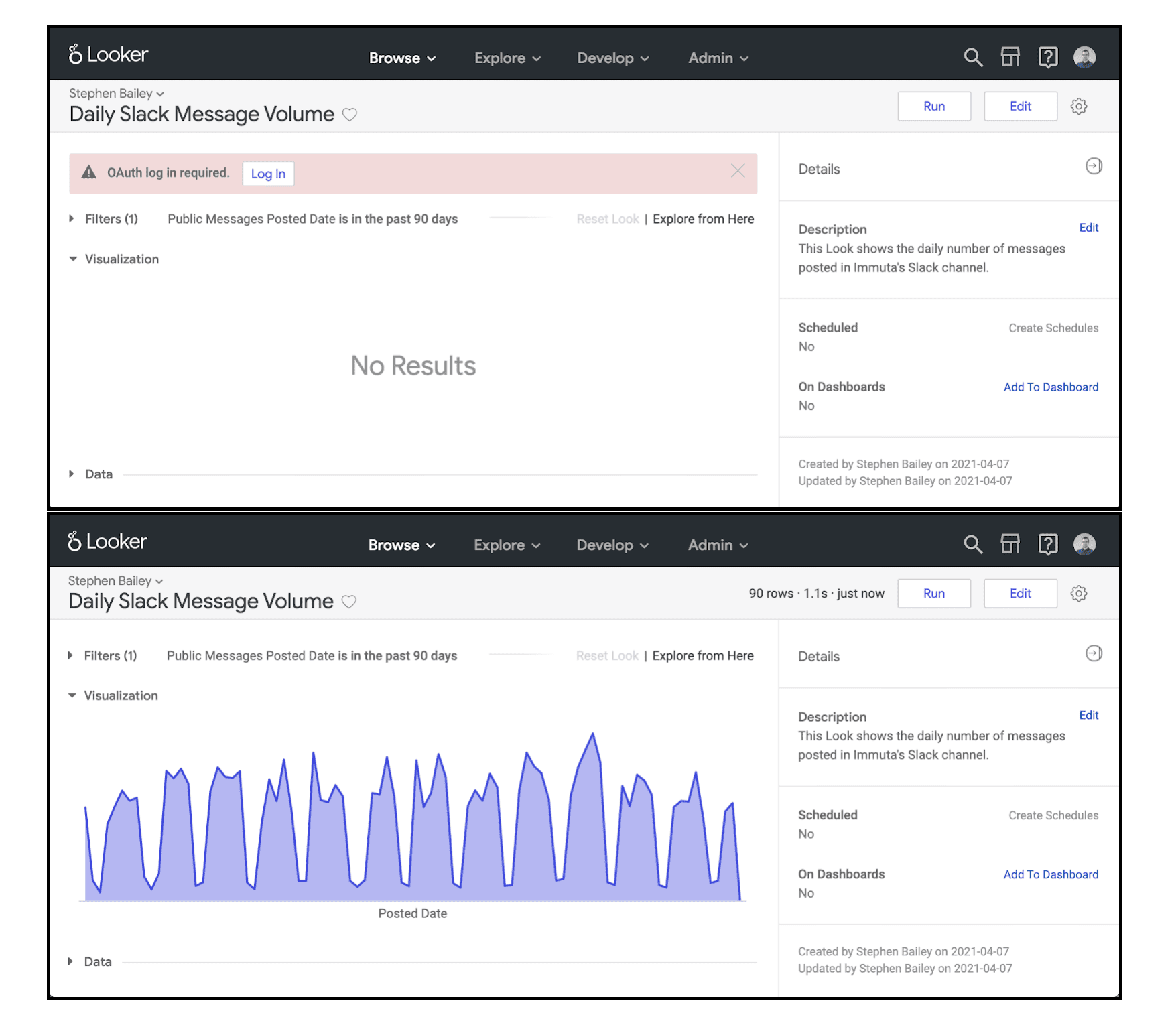
The user experience of logging in and getting personalized queries is simple and intuitive. Top, a prompt asks the user to login using OAuth. Bottom, data is returned after authentication.
Immuta projects can address this issue by generating a “clean room” for these transformations or interactions to take place. In these cases, an analyst might triage a series of data sources to upload, generate connection credentials with this limited set of privileges, then upload that connection to the tool. This ensures that the derived data sets are centrally managed and that provenance over the “extract” is recorded (and rescindable) in the future. It prevents the problem of creating generic system users that start with a small set of privileges but end up with a wide swath, and are accessible to everyone.
Conclusion
In the past, it was possible for organizations to tightly control the number and type of tools consuming data from the warehouse or data lake. That world is quickly fading. Consequently, the data platforms — and not the analytic tools — are becoming the epicenter of data management efforts. By focusing on governing these platforms well and maximizing the interoperability of tools with these platforms, we can create more scalable access control patterns that are simpler to audit and comprehend.
To learn more about how we use Immuta at Immuta, check out this blog on dogfooding data access control.