




“What if all those organizations could just create those rules, save it and be able to know in an auditable way that those rules are being followed. That’s what Immuta does for us.”

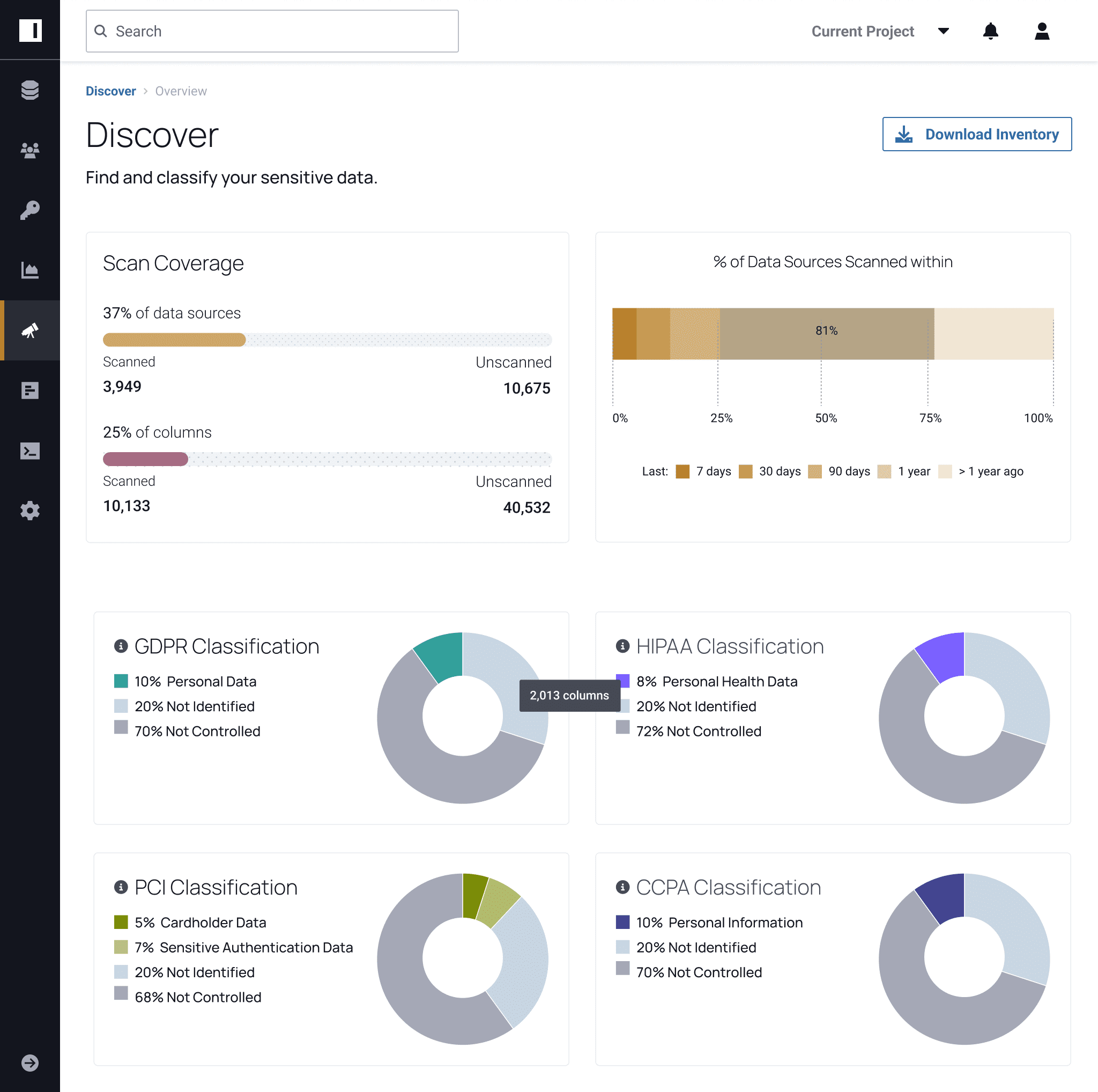
Immuta automatically discovers structured data in data lakes and warehouses, categorizing sensitive data like PII and PHI according to frameworks such as GDPR, HIPAA, PCI, and others. This gives you full visibility into what data requires access control and continuous monitoring.
Request A DemoQuickly understand your data, what is sensitive, and how to proactively monitor it
Comply with regulations like GDPR or HIPAA, and import your own compliance frameworks
Get accurate metadata and actionable tags, enabling you to secure your data
Leverage metadata to control data privacy and improve your data security posture
Automatically and continuously inventory the data in cloud data platforms like Snowflake, Databricks, Trino/Starburst, and Redshift. Understand what data you possess at a granular level.
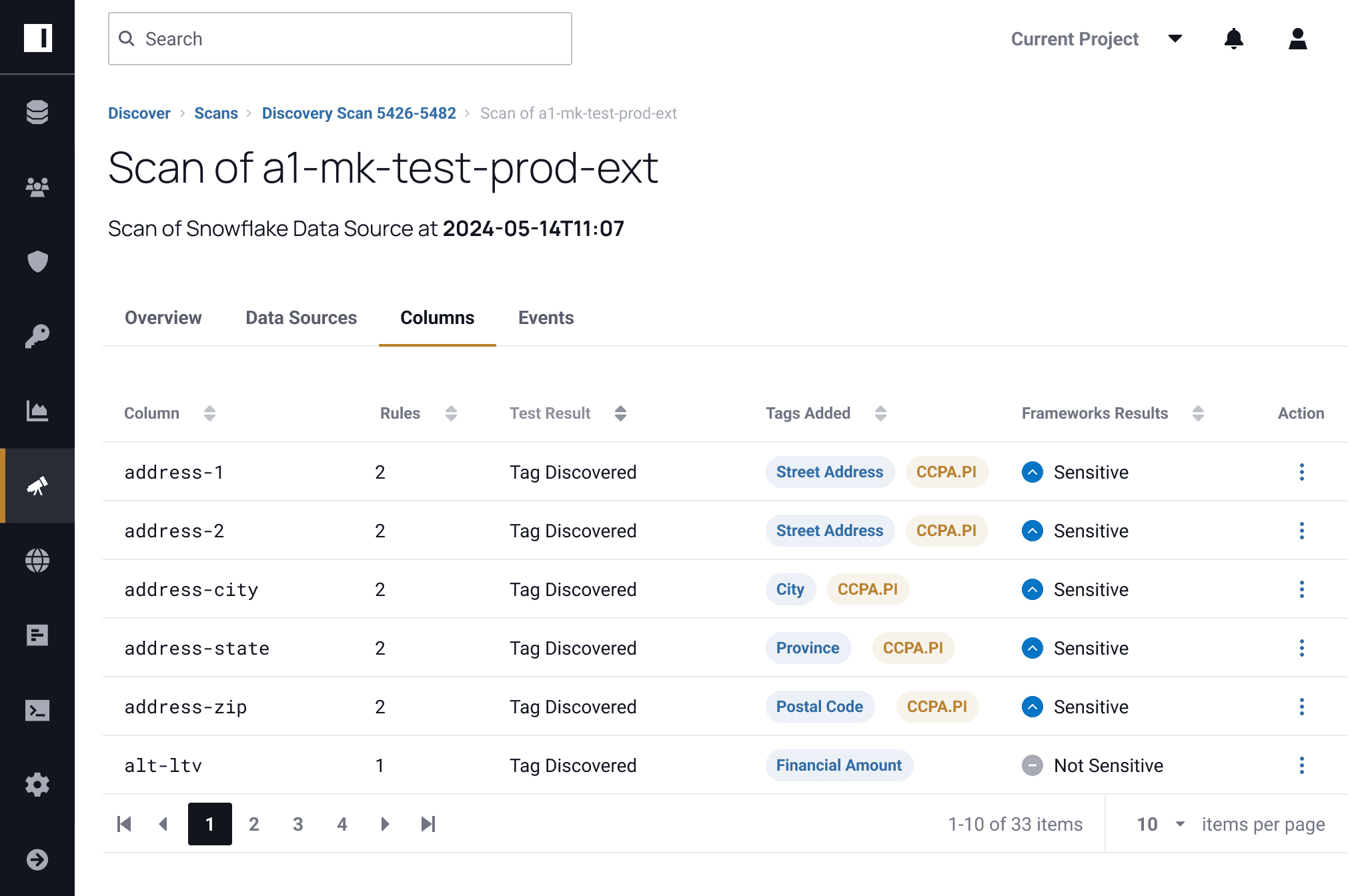
Discover sensitive data like PII or PHI with 60+ pre-built classifiers on a per-column level. Customize and import identifiers to find data specific to your organization.
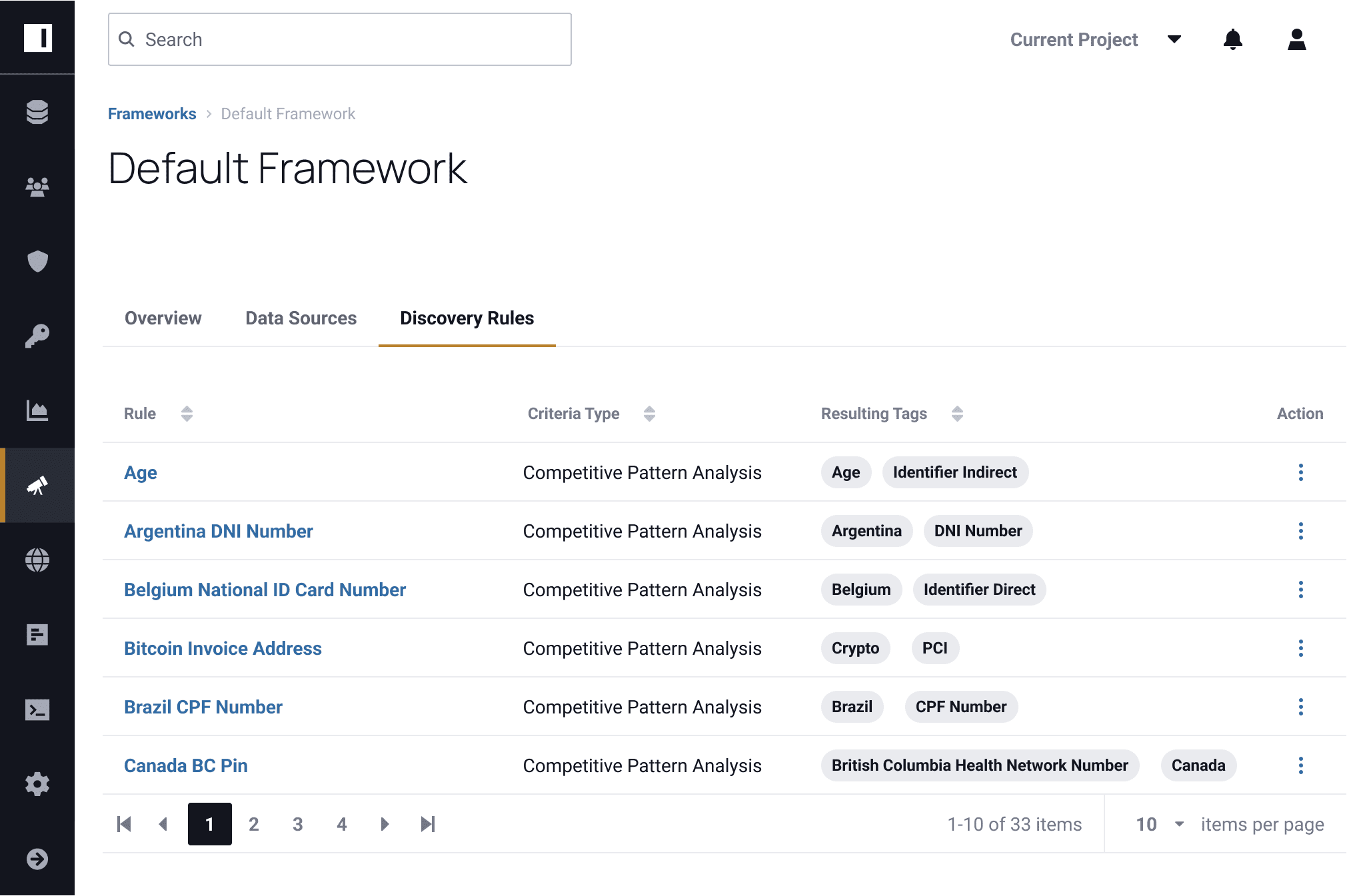
Categorize all your data automatically according to regulatory frameworks such as CCPA, GDPR, HIPAA, or PCI. Customize and import your company-specific frameworks to ensure compliance at every level.
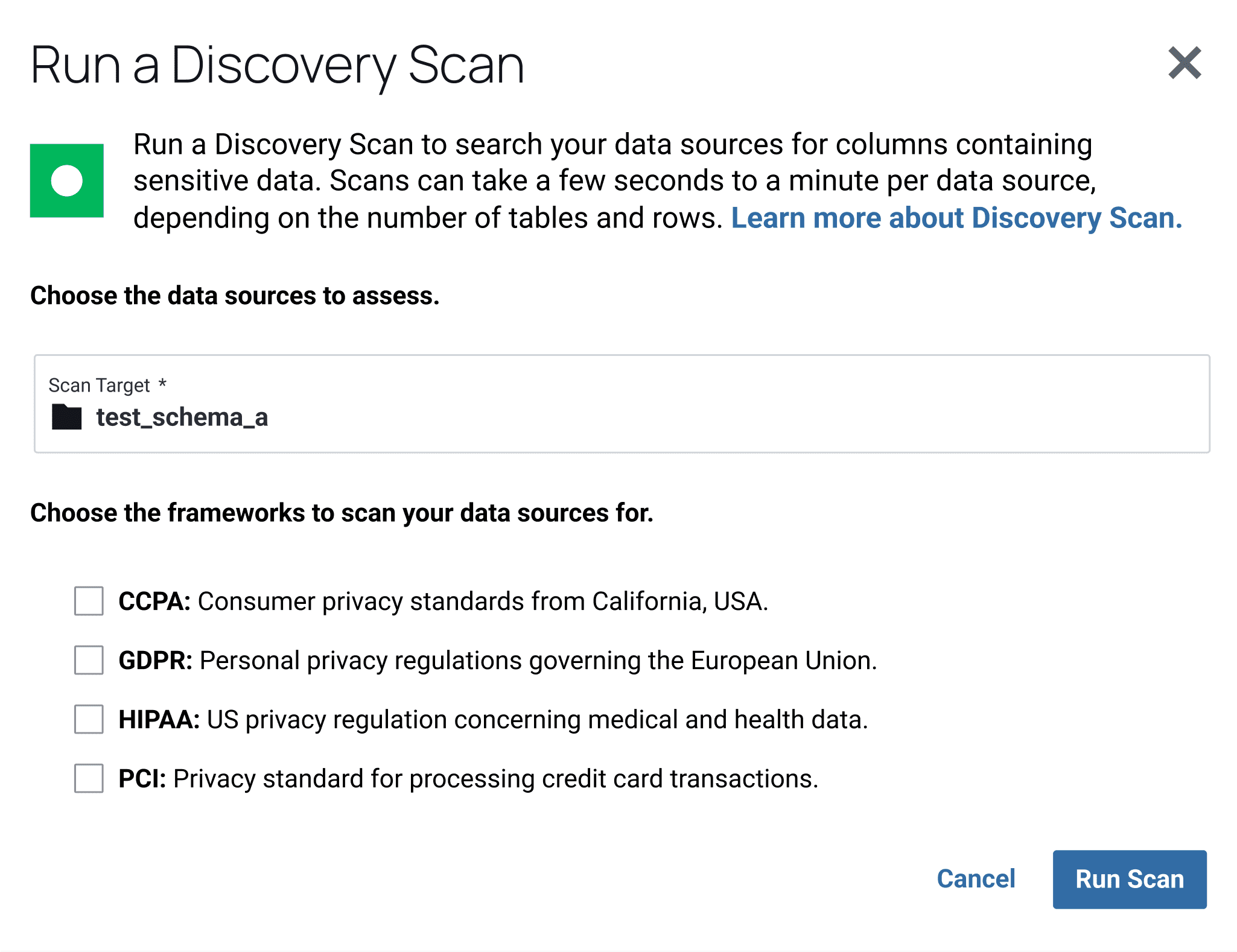
Immediately understand your sensitive and highly sensitive data, and classify it based on context and proximity to other potentially sensitive information.
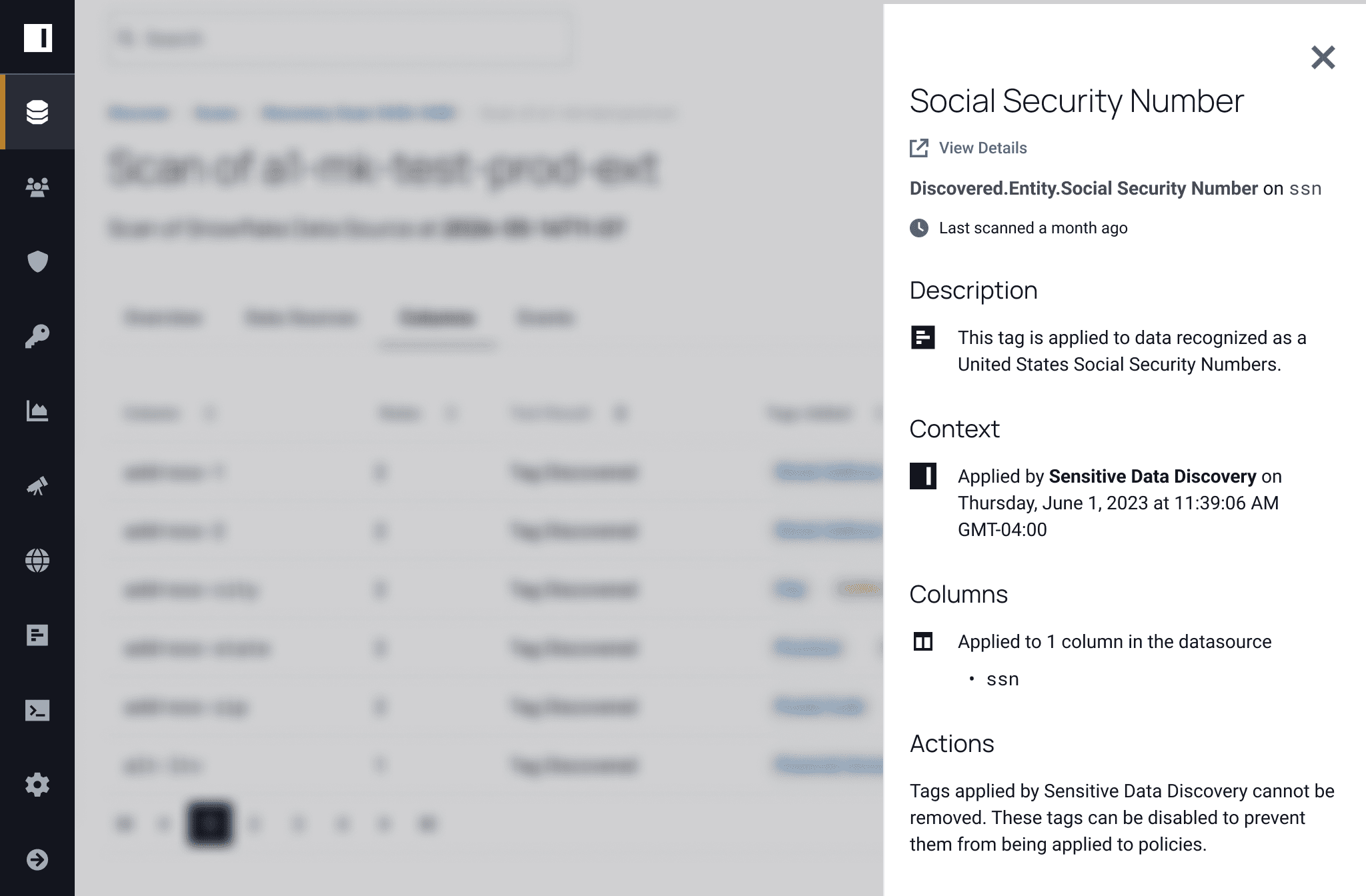
Analyze large amounts of data within your cloud platform or database, and quickly profile it. Avoid having to wait for slow data transfers with peace of mind that only metadata syncs back to Immuta.
Adhere to data localization and residency requirements by design (no data ever leaves the data store). Even if you run a global platform, data gets analyzed in-region.


“What if all those organizations could just create those rules, save it and be able to know in an auditable way that those rules are being followed. That’s what Immuta does for us.”

improvement in process efficiency
enhancement in analytics by using sensitive data securely
automation of data requests for 6000 analysts
increase in users accessing data
Data discovery and classification is a multi-step process aimed at providing a more detailed understanding of user data. Data discovery tools assess the data environment and identify data source locations. Next, the data is classified, using predefined parameters to identify and label certain data types that reside in these sources. Immuta’s sensitive data discovery tools automatically assess incoming data, classifying sensitive data in columns as tags and maintaining consistent data discovery and classification across the data ecosystem.
Data classification is a way of tagging data according to its type, sensitivity, and value to the organization if altered, stolen, or destroyed. This process is integral to the protection of data, as policies can be built based on how certain data is classified and its level of sensitivity. While the specificity of types of classification can vary, the most common types of data classification include public data, private and/or internal data, confidential data, and restricted data.
Taking a more traditional manual approach to data classification is incredibly labor-intensive, time-consuming, and prone to human error. By contrast, automated data classification streamlines the classification process by automatically analyzing and categorizing data in real-time. This automated data classification is carried out based on predetermined parameters, which are set by data teams in advance and allowed to run as new data enters a given data ecosystem.
An effective data discovery software should provide teams with a few key capabilities. These include an automated data discovery and classification process, giving enterprises clear visibility across their ecosystem as new data sources are added to different components. This data discovery software should also reduce costs and time-to-data, as well as reduce the risk of data breaches and leaks and ensure adherence to various compliance laws and regulations.
Let us show you how Immuta can transform the way you govern and share your sensitive data.


