
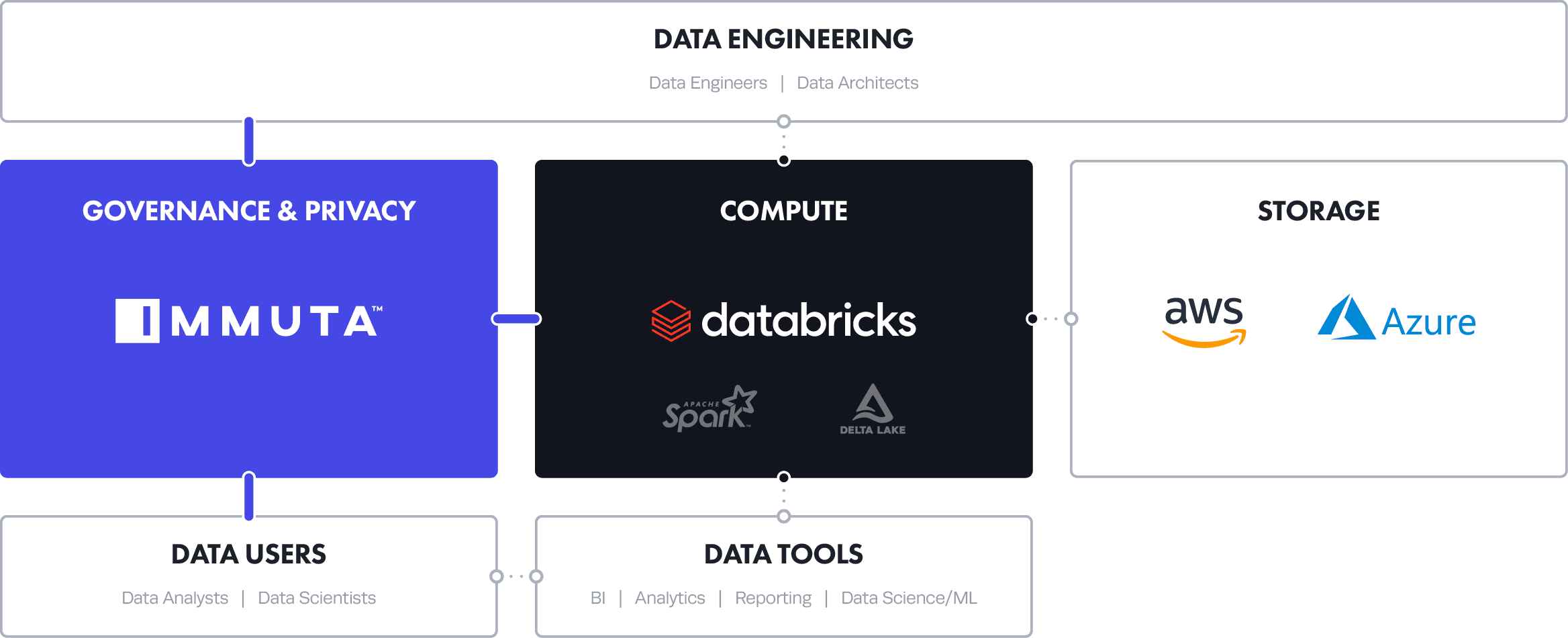
Immuta and Databricks have formed a deep business partnership and integrated their market-leading analytics and data governance solutions to deliver the best unified analytics in the cloud plus native data governance and access control.
Your most sensitive data is also your most valuable asset when it comes to analytics and data science. But if your most valuable asset can’t be accessed in real-time by analysts and data scientists – is it valuable anymore?
Organizations today know that making their data centralized, discoverable, and actionable is the key to data-driven innovation, personalized user experiences, and revenue growth. But with strict data privacy regulations like California’s CCPA and Europe’s GDPR, and internal data rules and security policies, data scientists are losing access to critical data. As a result, advanced analytics and data science projects – which require fast access to data – are slowing down or coming to a halt.
But what if your data science platform had data governance and privacy protection built in? What if it automatically knew what data to share with each user, for their role, purpose or project? And what if you could easily invite consultants or clients to participate in analytics projects, ensuring the same data policies (or even stricter policies) apply to them?
This is no longer a vision – it’s reality.
Today we’re excited to share that we’ve deepened our business partnership to strengthen Databricks access control, and introduced a new, native product integration that fuses Immuta’s automated Data Security platform with Databricks’ market-leading Unified Data Analytics Platform. It’s the best in data governance and data analytics – now one.

Immuta was the first provider in the data security space to recognize the need to join data access control with data science and analytics. We announced our initial partnership with Databricks in the spring of 2018 and in the years since have seen growing interest among our joint customer bases each year. There are some tectonic market drivers (including some that conflict) that make this partnership so critical for our customers, including:
- Data as the “fuel” for business. Businesses are capturing more data than ever (think social, mobile, cloud/IoT, 5G, data meshing, data monetization) and mining it to innovate, personalize products, and find new revenue streams.
- The rise in privacy expectations. Data privacy is more important than ever as a result of government regulations (billion dollar fines if you don’t comply) and consumer expectations (privacy protection is increasingly a driver of brand loyalty).
- The move to the cloud. Cloud-based analytics enables faster access to data and rapid analysis, but also greater risk potential due to consolidated sensitive data combined with nearly limitless compute power. The majority of organizations have now deployed or migrated to a cloud platform.
Both of our companies saw these trends converging, and knew we could solve big problems for companies by bringing our technologies – and best practices – together. Data scientists, Data Engineers, ML Engineers, and Data Analysts can now “just do their jobs” in Databricks – on the largest, most sensitive data sets in the world. Immuta works in the background protecting privacy so users and teams don’t have to worry about privacy, regulations or business rules. It’s truly frictionless for the user, while simple and powerful for governance teams.
For example, a global insurance customer had a challenge with “role bloat” that was preventing the move to a modern data science platform. To meet the dynamic access patterns of their analyst community, every combination of group, geography, clearance, and purpose required unique data-access roles and policies. It’s a story we hear every day – businesses want to take the next step and use data for advanced analytics and machine learning/AI, but regulatory- and rule-based data restrictions are getting in the way.
With Immuta natively integrated within Databricks, the customer now has the power to create automatically-enforced data policies – in plain language – combining ABAC (or attribute-based access control) and purpose. Now, the customer’s analysts enjoy dynamic access to data, with Immuta ensuring proper security and privacy protection – down to the row, column, and cell-level. Immuta’s integrated data governance ultimately made possible the migration to Databricks. The customer now benefits from analytics on a modern platform, without sacrificing governance and security.
Before we get into the new features of our joint solution with Databricks, let’s step back and review why automated data governance and privacy protection is now mission-critical in the world of data science and analytics. Until recently, analytics teams were forced to rely on ad-hoc, complex processes that restricted their agility and increased time-to-data or, in many cases, eliminated access to data altogether. Here are some warning signs and signals of an organization with immature data governance:
- No unified catalog. Companies without automated governance typically lack a unified data catalog for searching and exploring data sources across the enterprise. Why? Because you can’t provide self-service access to data through a programmatic catalog withOUT automated governance. If you did, you’d likely be in violation of one or more regulations.
- Manual “all or nothing” data approval processes. One user getting access to one table for one project requires multiple manual email approvals and checks against tens or hundreds of governance ‘policies’ – often hand-written by GRC teams to comply with every law applicable to the business. This “all or nothing”, human-driven approach to governance typically takes weeks or months and results in either zero access (crippling analytics) or unlimited access to entire tables or data sources (jeopardizing compliance).
- “Role bloat”. To handle the exploding number of regulatory- and rule-based restrictions to data, system administrators continue to create more and more roles that represent specific data access combinations. This “role bloat” – left unchecked – results in a situation where no one in IT or analytics knows what roles map to what data, and you have more roles than users and tables!
- Copies, copies and more copies. Analytics teams with immature governance often attempt to deal with privacy by creating copies of data and manually stripping out sensitive columns or rows. These copies, often hosted on cloud databases, create real risk for the business and limit the value of data for the data scientist. Copied data ages quickly and is often is stripped of the valuable, personal or behavioral signals they need to build advanced models.

By deeply integrating Immuta and Databricks, we can help analytics and data science teams quickly move from this state of immature governance to advanced, automated, fine-grained governance. Our new, native integration streamlines access to data for Databricks users in a compliant manner, allowing organizations to democratize access to data and meet stringent policies. Here are some specific features that make our joint solution so powerful:
- Fine-grained access control. We like to think of the “old” way of governing data as a light switch (it’s either on, or it’s off). Immuta adds a “dimmer” to your data access. Now you can apply powerful masking and anonymization techniques, plus row-level redactions, to your data on-the-fly. All Immuta privacy techniques and methods are enforced dynamically in Databricks’ Spark jobs. Dimming your data access lets you say “yes” to more users while ensuring compliance and preserving data value and utility.
- Unified, self-service data catalog. All Databricks data is searchable and discoverable through Immuta, which provides an at-a-glance view of data including where it’s stored, who owns it, when it was added, how recently it was it queried, and more. And because our catalog has governance ‘baked in’, we can uniquely enable self-service, programmatic data access. When a user subscribes to data in Immuta, all global (across all data sources) and local (data-source specific) policies will automatically be applied to their Spark workloads in Databricks.
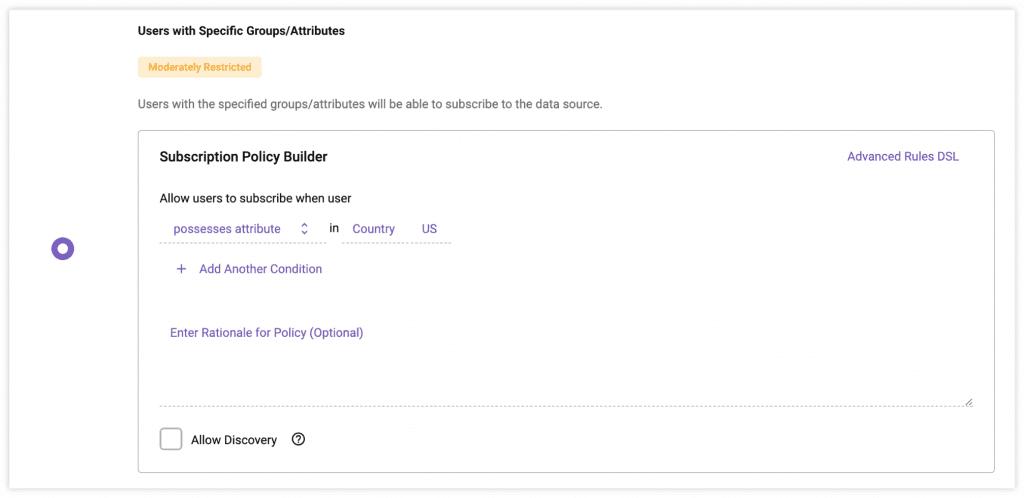
- No-code policies to cover every regulation. We know that lawyers aren’t engineers, and vice versa. So we designed our policy authoring to require absolutely NO coding. Simply write a sentence to define both global and local policies. These policies will automatically be enforced natively within Databricks, mitigating any concerns about query latency.

- Attribute-based access controls (ABAC). Immuta can pull in user attributes from many external systems, such as LDAP, Okta, Active Directory, or even SaaS systems like Workday. These user attributes can be used to author fine-grained, no-code-required policies for data governance – avoiding role bloat.
- Metadata-driven policy authoring. Instead of building policies one table at a time, Immuta allows the application of policies to be driven by data metadata such as sensitive data tags discovered by Immuta (using our Sensitive Data Detection feature) or ontologies curated by the organization through external tools that Immuta can reference.
With the joint solution we’ve announced today, our mutual customers will be able to safely expand and accelerate data science and analytics strategies in the cloud, while remaining compliant with data regulations and business rules. Interested in learning more? Read about the Immuta data security platform, explore our customers’ stories, or request a demo with our team.


